Дисперсионный анализ
| Загрузить архив: | |
| Файл: ref-17359.zip (138kb [zip], Скачиваний: 239) скачать |
Министерство образования Российской Федерации
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«ОРЕНБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ»
Факультет информационных технологий
Кафедра прикладной информатики
КУРСОВАЯ РАБОТА
По дисциплине: «Системный анализ»
На тему: «Дисперсионный анализ»
ГОУ ОГУ 071900.5303.09 ПЗ
|
Руководитель работы |
|
_____________Юдина Н.М. |
|
«___»_____________2003 г. |
|
Исполнитель |
|
студент гр. 99 ИСЭ-2 |
|
_____________Жбанов В.В. |
|
«___»_____________2003 г. |
г. Оренбург-2003
Содержание
с.
Введение…………………….……………………………………………....3
1 Дисперсионный анализ………………………………………………....4
1.1 Основные понятия дисперсионного анализа…………………..……4
1.2 Однофакторный дисперсионный анализ………………………….....6
1.3 Многофакторный дисперсионный анализ…………………….........12
2 Применение дисперсионного анализа в различных задачах и
исследованиях……………………………………………………………………...16
2.1 Использование дисперсионного анализа при изучении
миграционных процессов……………………………………………….……..….16
2.2 Принципы математико-статистического анализа данных
медико-биологических исследований……………...……………….……………17
2.3 Биотестирование почвы……………...…………………………..…...19
2.4 Грипп вызывает повышенную выработку гистамина…………..…..21
2.5 Дисперсионный анализ в химии……………………………...…..….22
2.6 Использование прямого преднамеренного внушения в
бодрствующем состоянии в методике воспитания физических качеств………23
2.7 Купирование острой психотической симптоматики у больных
шизофренией атипичным нейролептиком……………………………………….26
2.8 Снование фасонной пряжи с ровничным эффектом………….....….28
2.9 Сопутствующая паталогия при полной утрате зубов у лиц
пожилого и старческого возраста………………………………...………………29
3 Дисперсионный анализ в контексте статистических
методов…...................................................................................................................31
3.1 Векторные авторегрессии……………………………………...……..34
3.2 Факторный анализ………………………………………………….…37
3.3 Парная регрессия. Вероятностная природа регрессионных
моделей……………………………………………………………………….….…41
Заключение………………………………………………………….…..... 44
Список использованных источников………………………………....….45
Введение
Цель работы: познакомится с таким статистическим методом, как дисперсионный анализ.
Дисперсионный анализ (от латинского Dispersio – рассеивание) – статистический метод, позволяющий анализировать влияние различных факторов на исследуемую переменную. Метод был разработан биологом Р. Фишером в 1925 году и применялся первоначально для оценки экспериментов в растениеводстве. В дальнейшем выяснилась общенаучная значимость дисперсионного анализа для экспериментов в психологии, педагогике, медицине и др.
Целью дисперсионного анализа является проверка значимости различия между средними с помощью сравнения дисперсий. Дисперсию измеряемого признака разлагают на независимые слагаемые, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. Последующее сравнение таких слагаемых позволяет оценить значимость каждого изучаемого фактора, а также их комбинации /1/.
При истинности нулевой гипотезы (о равенстве средних в нескольких группах наблюдений, выбранных из генеральной совокупности), оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии.
При проведении исследования рынка часто встает вопрос о сопоставимости результатов. Например, проводя опросы по поводу потребления какого-либо товара в различных регионах страны, необходимо сделать выводы,на сколько данные опроса отличаются или не отличаются друг от друга. Сопоставлять отдельные показатели не имеет смысла и поэтому процедура сравнения ипоследующей оценки производится по некоторым усредненным значениям и отклонениям от этой усредненной оценки. Изучается вариация признака. За меру вариации может быть принята дисперсия. Дисперсия σ2 – мера вариации, определяемая как средняя из отклонений признака, возведенных в квадрат.
На практике часто возникают задачи более общего характера – задачи проверки существенности различий средних выборочных нескольких совокупностей. Например, требуется оценить влияние различного сырья на качество производимой продукции, решить задачу о влиянии количества удобрений на урожайность с/х продукции.
Иногда дисперсионный анализ применяется, чтобы установить однородность нескольких совокупностей (дисперсии этих совокупностей одинаковы по предположению; если дисперсионный анализ покажет, что и математические ожидания одинаковы, то в этом смысле совокупности однородны). Однородные же совокупности можно объединить в одну и тем самым получить о ней более полную информацию, следовательно, и более надежные выводы /2/.
1 Дисперсионный анализ
1.1 Основные понятия дисперсионного анализа
В процессе наблюдения за исследуемым объектом качественные факторы произвольно или заданным образом изменяются. Конкретная реализация фактора (например, определенный температурный режим, выбранное оборудование или материал) называется уровнем фактора или способом обработки. Модель дисперсионного анализа с фиксированными уровнями факторов называют моделью I, модель со случайными факторами - моделью II. Благодаря варьированию фактора можноисследоватьего влияниена величину отклика. В настоящее время общая теория дисперсионного анализа разработана для моделей I.
В зависимости от количества факторов, определяющих вариацию результативного признака, дисперсионный анализ подразделяют на однофакторный и многофакторный.
Основными схемами организации исходных данных с двумя и более факторами являются:
- перекрестная классификация, характерная для моделей I, в которых каждый уровень одного фактора сочетается при планировании эксперимента с каждой градацией другого фактора;
- иерархическая (гнездовая) классификация, характерная для модели II, в которой каждому случайному, наудачу выбранному значению одного фактора соответствует свое подмножество значений второго фактора.
Если одновременно исследуется зависимость отклика от качественных и количественных факторов, т.е. факторов смешанной природы, то используется ковариационный анализ /3/.
интерпретация результатов в терминах поставленной задачи /13/.
В таблице 3.1 приведены статистические методы, с помощью которых решаются аналитические задачи. В соответствующих ячейках таблицы находятся частоты применения статистических методов:
- метка «-» - метод не применяется;
- метка «+» - метод применяется;
- метка «++» - метод широко применяется;
- метка «+++» - применение метода представляет особый интерес /14/.
Дисперсионный анализ подобно t-критерию Стьюдента, позволяет оценить различия между выборочными средними;однако, вотличиеотt-критерия, в нем нет ограничений на количество сравниваемых средних. Таким образом, вместо того, чтобы поставить вопрос о различии двух выборочных средних, можно оценить, различаются ли два, три четыре, пять или kсредних.
Дисперсионный анализ позволяет иметь дело с двумя или более независимыми переменными (признаками, факторами) одновременно, оценивая не только эффект каждой из них по отдельности, но и эффекты взаимодействия между ними /15/.
Таблица 3.1 – Применение статистических методов при решении аналитических задач
|
Аналитические
задачи, возникающие |
Методы |
Методы
поверки |
Методы |
Методы |
Методы
анализа |
Методы |
Методы |
Методы |
Методы
анализа |
Методы
анализа |
|
Задачи горизонталь-ного |
++ |
+ |
- |
+ |
+ |
- |
- |
- |
- |
- |
|
Задачи вертикального |
++ |
- |
- |
+ |
++ |
++ |
+ |
+ |
- |
- |
|
Задачи трендового |
++ |
- |
+++ |
++ |
- |
- |
- |
- |
++ |
+++ |
|
Задачи анализа |
++ |
+ |
+ |
- |
+ |
+++ |
++ |
++ |
- |
++ |
|
Задачи сравнитель- ного |
++ |
- |
+ |
+ |
++ |
+++ |
++ |
++ |
- |
+ |
|
Задачи факторного анализа |
+ |
+ |
++ |
- |
++ |
+++ |
+ |
++ |
- |
+ |
К большинству сложных систем применим принцип Парето, согласно которому 20 % факторов определяют свойства системы на 80 %. Поэтому первоочередной задачей исследователя имитационной модели является отсеивание несущественных факторов, позволяющее уменьшить размерность задачи оптимизации модели.
Анализ дисперсии оценивает отклонение наблюдений от общего среднего. Затем вариация разбивается на части, каждая из которых имеет свою причину. Остаточная часть вариации, которую не удается связать с условиями эксперимента, считается его случайной ошибкой. Для подтверждения значимости используется специальный тест - F-статистика.
Дисперсионный анализ определяет, есть ли эффект. Регрессионный анализ позволяет прогнозировать отклик (значение целевой функции) в некоторой точке пространства параметров. Непосредственной задачей регрессионного анализа является оценка коэффициентов регрессии /16/.
Слишком большая размерность выборок затрудняет проведение статистических анализов, поэтому имеет смысл уменьшить размер выборки.
Применив дисперсионный анализ можно выявить значимость влияния различных факторов на исследуемую переменную. Если влияние фактораокажется несущественным, то этот фактор можно исключить из дальнейшей обработки.
3.1 Векторныеавторегрессии
Макроэконометристы должны уметь решать четыре логически отличающиеся задачи:
- описание данных;
- макроэкономический прогноз;
- структурный вывод;
- анализ политики.
Описание данных означает описание свойств одного или нескольких временных рядов и сообщение этих свойств широкому кругу экономистов. Макроэкономический прогноз означает предсказание курса экономики, обычно на два-три года или меньше (главным образом потому, что прогнозировать на более длинные горизонты слишком трудно). Структурный вывод означает проверку того, соответствуют ли макроэкономические данные конкретной экономической теории. Макроэконометрический анализ политики происходит по нескольким направлениям: с одной стороны, оценивается влияние на экономику гипотетического изменения инструментов политики (например налоговой ставки или краткосрочной процентной ставки), с другой стороны, оценивается влияние изменения правил политики (например переход к новому режиму монетарной политики). Эмпирический макроэкономический исследовательский проект может включать одну или несколько из этих четырех задач. Каждая задача должна быть решена таким образом, чтобы были учтены корреляции между рядами по времени.
В 1970-х годах эти задачи решались с использованием разнообразных методов, которые, если оценить их с современных позиций, были неадекватны по нескольким причинам. Чтобы описать динамику отдельного ряда, достаточно было просто использовать одномерные модели временных рядов, а чтобы описать совместную динамику двух рядов – спектральный анализ. Однако отсутствовал общепринятый язык, пригодный для систематического описания совместных динамических свойств нескольких временных рядов. Экономические прогнозы делались либо с использованием упрощенных моделей авторегрессии — скользящего среднего (ARMA), либо с использованием популярных в то время больших структурных эконометрических моделей. Структурный вывод основывался либо на малых моделях с одним уравнением, либо на больших моделях, идентификация в которых достигалась за счет плохо обоснованных исключающих ограничений, и которые обычно не включали ожидания. Анализ политики на основе структурных моделей зависел от этих идентифицирующих предположений.
Наконец, рост цен в 1970-е годы рассматривался многими как серьезная неудача больших моделей, которые в то время использовались для выработки политических рекомендаций. То есть это было подходящее время для появления новой макроэконометрической конструкции, которая могла бы решить эти многочисленные проблемы.
В 1980 году была создана такая конструкция – векторные авторегрессии (VAR). На первый взгляд, VAR – не более, чем обобщение одномерной авторегрессии на многомерный случай, и каждое уравнение в VAR – не более, чем обычная регрессия по методу наименьших квадратов одной переменной на запаздывающие значения себя и других переменных в VAR. Но этот вроде бы простой инструмент дал возможность систематически и внутренне согласованно уловить богатую динамику многомерных временных рядов, а статистический инструментарий, который сопутствует VAR, оказался удобным и, что очень важно, его было легко интерпретировать.
Выделяют три различных VAR-модели:
- приведенная форма VAR;
- рекурсивная VAR;
- структурная VAR.
Все три являются динамическими линейными моделями, которые связывают текущие и прошлые значения вектора Yt n-мерного временного ряда. Приведенная форма и рекурсивные VAR – это статистические модели, которые не используют никакие экономические соображения за исключением выбора переменных. Эти VAR используются для описания данных и прогноза. Структурная VAR включает ограничения, полученные из макроэкономической теории, и эта VAR используется для структурного вывода и анализа политики.
Приведенная форма VAR выражает Yt в виде распределенного лага прошлых значений плюс серийно некоррелированный член ошибки, то есть обобщает одномерную авторегрессию на случай векторов. Математически приведенная форма модели VAR – это система n уравнений, которые можно записать в матричной форме следующим образом:
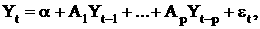 (17)
(17)
где a - это n´ l вектор констант;
A1, A2, ..., Ap – это n´ n матрицы коэффициентов;
et, - это n´l вектор серийно некоррелированных ошибок, о которых
предполагается, что они имеют среднее ноль и матрицу ковариаций 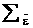
Ошибки et, в (17) – это неожиданная динамика в Yt, остающаяся после учета линейного распределенного лага прошлых значений.
Оценить параметры приведенной формы VAR легко. Каждое
из уравнений содержит одни и те же регрессоры (Yt–1,...,Yt–p),
и нет взаимных ограничений между уравнениями. Таким образом, эффективная оценка
(метод максимального правдоподобия с полной информацией) упрощается до обычного
МНК, примененного к каждому из уравнений. Матрицу ковариаций ошибок можно состоятельно
оценить выборочной ковариационной матрицей полученных из МНК остатков.
Единственная тонкость – определить длину лага p, но это можно сделать, используя информационный критерий, такой как AIC или BIC.
На уровне матричных уравнений рекурсивная и структурная VAR выглядят одинаково. Эти две модели VAR учитывают в явном виде одновременные взаимодействия между элементами Yt, что сводится к добавлению одновременного члена к правой части уравнения (17). Соответственно, рекурсивная и структурная VAR обе представляются в следующем общем виде:
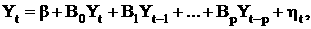 (18)
(18)
где b - вектор констант;
B0,..., Bp - матрицы;
ht — ошибки.
Наличие в уравнении матрицы B0 означает возможность одновременного взаимодействия между n переменными; то есть B0 позволяет сделать так, чтобы эти переменные, относящиеся к одному моменту времени, определялись совместно.
Рекурсивную VAR можно оценить двумя способами. Рекурсивная структура дает набор рекурсивных уравнений, которые можно оценить с помощью МНК. Эквивалентный способ оценивания заключается в том, что уравнения приведенной формы (17), рассматриваемые как система, умножаются слева на нижнюю треугольную матрицу.
Метод оценивания структурной VAR зависит от того, как именно идентифицирована B0. Подход с частичной информацией влечет использование методов оценивания для отдельного уравнения, таких как двухшаговый метод наименьших квадратов. Подход с полной информацией влечет использование методов оценивания для нескольких уравнений, таких как трехшаговый метод наименьших квадратов.
Необходимо помнить о множественности различных типов VAR. Приведенная форма VAR единственна. Данному порядку переменных в Yt соответствует единственная рекурсивная VAR, но всего имеется n! таких порядков, т.е. n! различных рекурсивных VAR. Количество структурных VAR– то есть наборов предположений, которые идентифицируют одновременные взаимосвязи между переменными, - ограничено только изобретательностью исследователя.
Поскольку матрицы оцененных коэффициентов VAR затруднительно интерпретировать непосредственно, результаты оценивания VAR обычно представляют некоторыми функциями этих матриц. К таким статистикам разложения ошибки прогноза.
Разложения дисперсии ошибки прогноза вычисляются в основном для рекурсивных или структурных систем. Такое разложение дисперсии показывает, насколько ошибка в j-м уравнении важна для объяснения неожиданных изменений i-й переменной. Когда ошибки VAR некоррелированы по уравнениям, дисперсию ошибки прогноза на h периодов вперед можно записать как сумму компонентов, являющихся результатом каждой из этих ошибок /17/.
3.2 Факторный анализ
В современной статистике под факторным анализом понимают совокупность методов, которые на основе реально существующих связей признаков (или объектов) позволяют выявлять латентные обобщающие характеристики организационной структуры и механизма развития изучаемых явлений и процессов.
Понятие латентности в определении ключевое. Оно означает неявность характеристик, раскрываемых при помощи методов факторного анализа. Вначале имеется дело с набором элементарных признаков Xj, их взаимодействие предполагает наличие определенных причин, особенных условий, т.е. существование некоторых скрытых факторов. Последние устанавливаются в результате обобщения элементарных признаков и выступают как интегрированные характеристики, или признаки, но более высокого уровня. Естественно, что коррелировать могут не только тривиальные признаки Xj, но и сами наблюдаемые объекты Ni поэтому поиск латентных факторов теоретически возможен как по признаковым, так и по объектным данным.
Если объекты характеризуются достаточно большим числом элементарных признаков (m > 3), то логично и другое предположение - о существовании плотных скоплений точек (признаков) в пространстве n объектов. При этом новые оси обобщают уже не признаки Xj, а объекты ni, соответственно и латентные факторы Fr будут распознаны по составу наблюдаемых объектов:
Fr = c1n1 + c2n2 + ... + cNnN,
где ci - вес объекта ni в факторе Fr.
В зависимости от того, какой из рассмотренных выше тип корреляционной связи - элементарных признаков или наблюдаемых объектов - исследуется в факторном анализе, различают R и Q - технические приемы обработки данных.
Название R-техники носит объемный анализ данных по m признакам, в результате него получают r линейных комбинаций (групп) признаков: Fr=f(Xj), (r=1..m). Анализ по данным о близости (связи) n наблюдаемых объектов называется Q-техникой и позволяет определять r линейных комбинаций (групп) объектов: F=f(ni), (i = l .. N).
В настоящее время на практике более 90% задач решается при помощи R-техники.
Набор методов факторного анализа в настоящее время достаточно велик, насчитывает десятки различных подходов и приемов обработки данных. Чтобы в исследованиях ориентироваться на правильный выбор методов, необходимо представлять их особенности. Разделим все методы факторного анализа на несколько классификационных групп:
- Метод главных компонент. Строго говоря, его не относят к факторному анализу, хотя он имеет с ним много общего. Специфическим является, во-первых, то, что в ходе вычислительных процедур одновременно получают все главные компоненты и их число первоначально равно числу элементарных признаков. Во-вторых, постулируется возможность полного разложения дисперсии элементарных признаков, другими словами, ее полное объяснение через латентные факторы (обобщенные признаки).
- Методы факторного анализа. Дисперсия элементарных признаков здесь объясняется не в полном объеме, признается, что часть дисперсии остается нераспознанной как характерность. Факторы обычно выделяются последовательно: первый, объясняющий наибольшую долю вариации элементарных признаков, затем второй, объясняющий меньшую, вторую после первого латентного фактора часть дисперсии, третий и т.д. Процесс выделения факторов может быть прерван на любом шаге, если принято решение о достаточности доли объясненной дисперсии элементарных признаков или с учетом интерпретируемости латентных факторов.
Методы факторного анализа целесообразно разделить
дополнительно на два класса: упрощенные и современные аппроксимирующие методы.
Простые методы факторного анализа в основном связаны с начальными
теоретическими разработками. Они имеют ограниченные возможности в выделении
латентных факторов и аппроксимации факторных решений. К ним относятся:
- однофакторная модель. Она позволяет выделить только один генеральный латентный и один характерный факторы. Для возможно существующих других латентных факторов делается предположение об их незначимости;
- бифакторная модель. Допускает влияние на вариацию элементарных признаков не одного, а нескольких латентных факторов (обычно двух) и одного характерного фактора;
- центроидный метод. В нем корреляции между переменными рассматриваются как пучок векторов, а латентный фактор геометрически представляется как уравновешивающий вектор, проходящий через центр этого пучка. : Метод позволяет выделять несколько латентных и характерные факторы, впервые появляется возможность соотносить факторное решение с исходными данными, т.е. в простейшем виде решать задачу аппроксимации.
Современные аппроксимирующие методы часто предполагают, что первое, приближенное решение уже найдено каким либо из способов, последующими шагами это решение оптимизируется. Методы отличаются сложностью вычислений. К этим методам относятся:
- групповой метод. Решение базируется на предварительно отобранных каким-либо образом группах элементарных признаков;
- метод главных факторов. Наиболее близок методу главных компонент, отличие заключается в предположении о существовании характерностей;
- метод максимального правдоподобия, минимальных остатков, а-факторного анализа канонического факторного анализа, все оптимизирующие.
Эти методы позволяют последовательно улучшить предварительно найденные решения на основе использования статистических приемов оценивания случайной величины или статистических критериев, предполагают большой объем трудоемких вычислений. Наиболее перспективным и удобным для работы в этой группе признается метод максимального правдоподобия.
Основной задачей, которую решают разнообразными
методами факторного анализа, включая и метод главных компонент, является сжатие
информации, переход от множества значений по m элементарным признакам с объемом информации n х m к
ограниченному множеству элементов матрицы факторного отображения (m х r) или матрицы
значений латентных факторов для каждого наблюдаемого объекта размерностью n х r, причем обычно
r < m.
Методы факторного анализа позволяют также визуализировать структуру изучаемых
явлений и процессов, а это значит определять их состояние и прогнозировать
развитие. Наконец, данные факторного анализа дают основания для идентификации
объекта, т.е. решения задачи распознавания образа.
Методы факторного анализа обладают свойствами, весьма привлекательными для их
использования в составе других статистических методов, наиболее часто в
корреляционно-регрессионном анализе, кластерном анализе, многомерном
шкалировании и др. /18/.
3.3 Парная регрессия. Вероятностная природа регрессионных моделей.
Если рассмотреть задачу анализа расходов на питание в группах с одинаковыми доходами, например в $10.000(x), то это детерминированная величина. А вот Y - доля этих денег, затрачиваемая на питание - случайна и может меняться от года к году. Поэтому для каждого i-го индивида:
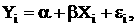
где εi- случайная ошибка;
α и β - константы (теоретически), хотя могут меняться от модели к модели.
Предпосылки для парной регрессии:
- X и Y связаны линейно;
- Х - неслучайная переменная с фиксированными значениями;
- ε - ошибки нормально распределены N(0,σ2);
- 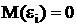 ;
;
- 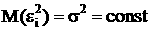
На рисунке 3.1 представлена модель парной регрессии.
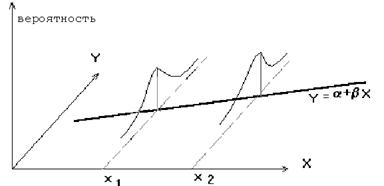
Рисунок 3.1 – Модель парной регрессии
Эти предпосылки описывают классическую линейную регрессионную модель.
Если ошибка имеет ненулевое среднее, исходная модель будет эквивалентна новой модели и другим свободным членом, но с нулевым средним для ошибки.
Если
выполняются предпосылки, то МНК оценки 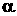 и
и 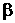 являются эффективными линейными
несмещенными оценками
являются эффективными линейными
несмещенными оценками
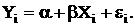
Если обозначить:
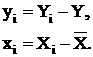
то что математическое ожидание и дисперсии коэффициентов и будут следующие:
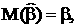
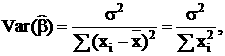
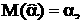
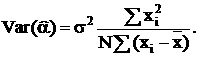
Ковариация коэффициентов:
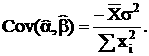
Если 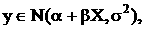 то и распределены тоже нормально:
то и распределены тоже нормально:
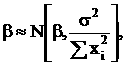
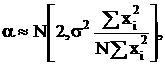
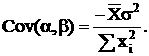
Отсюда следует, что:
- Вариация β полностью определяется вариацией ε;
- Чем выше дисперсия X - тем лучше оценка β.
Полная дисперсия определяется по формуле:
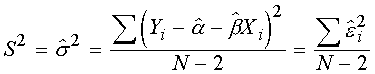
Дисперсия отклонений в таком виде - несмещенная оценка и называется стандартной ошибкой регрессии. N-2 - может быть интерпретировано как число степеней свободы.
Анализ отклонений от линии регрессии может представить полезную меру того, насколько оцененная регрессия отражает реальные данные. Хорошая регрессия та, которая объясняет значительную долю дисперсии Y и наоборот плохая регрессия не отслеживает большую часть колебаний исходных данных. Интуитивно ясно, что всякая дополнительная информация позволит улучшить модель, то есть уменьшить необъясненную долю вариации Y. Для анализа регрессионной модели проводят разложение дисперсии на составляющие, определяют коэффициент детерминации R2.
Отношение двух дисперсий распределено по F-распределению, т. е. если проверить на статистическую значимость отличия дисперсии модели от дисперсии остатков, можно сделать вывод о значимости R2.
Проверка гипотезы о равенстве дисперсий этих двух выборок:
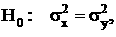
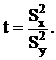
Если гипотеза Н0 (о равенстве дисперсий нескольких выборок) верна, t имеет F-распределение с (m1,m2)=(n1-1,n2-1) степенями свободы.
Посчитав F – отношение как отношение двух дисперсий и сравнив его с табличным значением, можно сделать вывод о статистической значимости R2 /2/, /19/.
Заключение
Современные приложения дисперсионного анализа охватывают широкий круг задач экономики, биологии и техники и трактуются обычно в терминах статистической теории выявления систематических различий между результатами непосредственных измерений, выполненных при тех или иных меняющихся условиях.
Благодаря автоматизации дисперсионного анализа исследователь может проводить различные статистические исследования с применение ЭВМ, затрачивая при этом меньше времени и усилий на расчеты данных. В настоящее время существует множество пакетов прикладных программ, в которых реализован аппарат дисперсионного анализа. Наиболее распространенными являются такие программные продукты как:
- MSExcel;
- Statistica;
- Stadia;
- SPSS.
В современных статистических программных продуктах реализованы большинство статистических методов. С развитием алгоритмических языков программирования стало возможным создавать дополнительные блоки по обработке статистических данных.
Дисперсионный анализ является мощным современным статистическим методом обработки и анализа экспериментальных данных в психологии, биологии, медицине и других науках. Он очень тесно связан с конкретной методологией планирования и проведения экспериментальных исследований.
Дисперсионный анализ применяется во всех областях научных исследований, где необходимо проанализировать влияние различных факторов на исследуемую переменную.
Список используемых источников
1 Кремер Н.Ш. Теория вероятности и математическая статистика. М.: Юнити – Дана, 2002.-343с.
2 Гмурман В.Е. Теория вероятностей и математическая статистика. – М.: Высшая школа, 2003.-523с.
3
4
5
6
7
8
9
10
11
12
13
14 www.bizcom.ru
15 Гусев А.Н. Дисперсионный анализ в экспериментальной психологии. – М.: Учебно-методический коллектор «Психология», 2000.-136с.
16 www.gpss.ru
17
18
19 www2.econ.msu.ru