Некоторые подходы к задачам распознавания и их приложениям
| Примечание | В статье расматренны некоторые подходы к решению задач управления вычислительным процессом ЭВМ, а также применение методов распознавание образов в созданий достоверных прогнозов в социально-экономической среде |
| Загрузить архив: | |
| Файл: ref-20907.zip (18kb [zip], Скачиваний: 41) скачать |
НЕКОТОРЫЕ ПОДХОДЫ К ЗАДАЧАМ РАСПОЗНАВАНИЯ
ОБРАЗОВ И ИХ ПРИЛОЖЕНИЯМ
Е. Т. РАМАЗАНОВ
Сейчасстатистические исследования развиваются в направлениинаучного предсказывания,прогнозирования социально- экономической среды. Один из подходов решение вопроса прогнозирование заключается в решении задач классификаций.
Одно из условий развитиянауки в направлениинаучного прогнозирования заключается в возможностях современной ЭВМ, которые позволяют обрабатыватьогромные массивы информации.
Известно что существует множество подходоврешений вопроса научного прогнозирования,такие какэксперимент, компьютерная моделирования.Возникает вопрос,на сколько можно доверять результатам решений предсказываниие, и, вообще, достоверен липолученный результат,насколько разница она с действительностью. Безусловно что решая конкретную заданную задачу, каждый метод имеет свои плюсы и минусы и исследователь используя тот или иной методстремится к томучто бы ошибка разницы была достаточно маленькой, и если уж совсем ошибки невозможно устранить, тооценить их(здесь вопрос достоверности он переносит в иное поле,исследователь решает вопрос объективно имитируетли реальный процесс или явление созданная модель. или. Строит критерий качества т.е. применяет идей оптимизации. Если да то он доверяет результату ). Оценить ошибку достоверности предсказывание порой и невозможно сделать ибо статистические оценки гипотез вероятностны.
Описанный здесь подходможет быть эффективен с точки зрениедостоверного предсказывания.
Задача классификацийтесно связана с такимидисциплинами как математическая статистика, теория вероятностей, кластерный анализ. Было проделана огромная работа по разработке методов и подходов решений задач классификаций. Фундаментом послужили такие работы какДж. Хартигана, Миркина, Дюрана М.Б. ,Дж. Вэн Райзена , Айвазяна . и др.
Решениезадачи классификаций основана на кластерном анализе.
Изложенные здесь основные идей кластерного анализаосновываются на работах [2 ]и[ 3].
Пусть множествоТ=( Т 1Т2Т3 ,…, Тn) обозначает n обьектов .
Предположим, чтосуществует некоторое множество наблюдаемых
показателей или характеристик.Обозначимэто множество
С=(С1С2 С3, .. ., Ср); этими характеристикамиобладает каждый индивид из множества Т.Наблюдаемые характеристикимогут быть количественнымиили качественными . Наблюдение часто называют измерениями. Результат измерениеi-йхарактеристики(измерение )Tj –обьекта обозначимхij, а вектор Хj=[ хij]размером рХ1 будет отвечать каждому ряду измерений для j- гообьекта . Таким образом исследователь множеством
Х=(Х1 Х2 Х3 ,…, Хp)описывает множествоТ.
Множество Х может представлено как к точек в р- мерном евклидовом пространстве Ер .
Задача кластерного анализа заключается в
томчтобы на оснований данных в
множестве Х разбить множество Тна m-классов
m Так чтобы,
каждый обьект принадлежалодному
и только одному подмножеству разбиение ,и
что бы обьекты принадлежащие одному и тому же
классубыли сходнымив то время как обьекты
различных классов былибы разнородными. Разбиение
здесь следует понимать как
разделение множествоТ на определенное
число непустыхпопарно непересекающихся
подмножеств. Решение задачи кластерного анализа является
разбиение удовлетворяющее некоторому критерию оптимальности . в качестве
критерияможет быть функционалнапример сумма квадратов отклонений W= Критерий
оптимальностипоказывает когда мы
получили нужное разбиение. Очевидно чтобы решить задачу кластерного
анализанеобходимо количественно определить понятия сходства и
разнородности . Задача была бырешена если
ТiТjобьекты попадали в один и тот же классвсякий раз когда расстояние между
точкамиХi Хj было
бы достаточным малыми ,наоборот,обьекты попадали бы в разные классыкогда между соответствующими точкамирасстояние былобы достаточно
большим. Расстояние d(XiXj) между точкамиХi Хj p
мерном евклидовом
пространствеможно задатьположительно определенной функцией, которая
является метрикой и удовлетворяет аксиомам метрики. Отметим чтофункция расстояниеd(XiXj)
задает соответственносходство
между обьектами
Тi Тj. Существует множество видов функций
расстояние использующийв евклидовом
пространстве .напримеревклидова метрика
, Л норма, расстояние Махаланобиса . приведем лишь
евклидова метрику d(XiXj)= Расстояние между n обьектамиможно задать в виде симметричнойматрицы размеромnХn.
Такую матрицу иногда называют матрицей связей. Также можно определить меру сходства . Мера
сходства s(XiXj) положительно определенная функция и
удовлетворяетследушим
условиям : 1. s(Xi Xi)=1 ; 2. s(Xi Xj)=s(Xj Xi) ; 3.
s(XiXj)
определена в интервале[0 1] ; мы можем задатьмеру сходство с помощьюфункций расстояние например: s(Xi
Xj)=1/1+d(Xi Xj) ; Существует множество методов классификаций .описание
этих методов и принциповвы можете найти
в работе 3. Интересен аппроксимационный подход.Пусть имеется матрица связей D размером nxn. Рассмотрим отношение эквивалентностиRn , которое
порождает разбиение множество
Хна непустые m классы Rn=(Rn
Rn Rn…Rn). представим
Rk в виде бинарной матрицы.Элемент матрицы равны 1,если обьектылежат в одном
классеи равны 0 в противном
случае. Требуется найти разбиениес
булевой матрицей Rn, которая бы в наибольшей мере
соответствовала матрице связей. Как сопоставить матрицу связей D и
матрицу Rn друг с другом. В работе [6]предлагают,
взвешивать матрицу Rn , вводя некоторый коэффицент маштаба K(Rn, Где dij=d(XiXj); rij-элементы
матрицы Rn.
Для аналитического решение
удобно что либо зафиксировать. Если задан порог близости r(Q, Rn)= где Требуется найти матрицу Rn
аппроксимирующего матрицуQ. Существует большая группа методов
кластерного анализа в основе которой лежит решение этой задачи . Предположим, что мы имеем результат
разбиение построенного нами алгоритма классификаций. Справедливо ли отнес обьект Тi классу
Rn, когда в действительности он принадлежит,
быть может, к другому классу.Вэтом случай исследователь идетпо одному из пути. Обрабатываетнабор данных
разными алгоритмами. результаты сравнивает между собой, или если есть
эксперт,то сравнивает с его разбиением.Но экспертного разбиение может и не
быть,а сравнение результатов разных алгоритмов может быть не достаточным. В таком случае исследователь может
провериткластер данных на
«реальность». Понятие реальности кластера данных основывается на идеях Дж.Хартигана. Как вообще предполагается строить
прогнозирования социально-экономической среды в задачах классификаций.
Рассмотрим на примере . Пусть имеемn
городов каждую из которых характеризуем
некоторымипараметрами . например
с1-потребление электроэнергий ,с2- личным потреблениеми.т.д. Тогда Х вектор
представляет собой набор указанных характеристик Задача классификаций
заключается в том чтобы разбить города по уровню развития.Ппредположим ,что
мы разбили города по уровню рразвития,и
предположим ,что результат
разбиениереален. Теперь изменим параметр одного городапроверим снова не изменился лирезультат
разбиениена основе результата
можно строить прогнозы .Прогноз будет достоверным ибо алгоритм классификаций
разбивает правильно . в заключении стоить отметит, что исследователь должен убедится в том, что
алгоритм классификаций разбивает правильно. Применение
алгоритмов распознавания для решений задач сегментации. Одним из
интересных приложений теорий распознавания
является возможностииспользовать
некоторыемодели этой теорийдля решения задач в разных областяхматематики. В частности длярешения трудных комбинаторных задач итаких как
задача сегментации программ[6].
Под задачей сегментацииобычно
принято понимать задачу разбиения последовательной программы на
взаимозависимыепо управлениюи информационной части (блоки, сегменты и. т.
д. ) в соответствии с той или иной целью. Для решения задач сегментации
существует ряд методов. Которые разделяются
условно на несколько подходов. Которые позволяют в основном получить
лишь приближенные решения при неизвестной погрешностиопределяемых решений. Один из таких подходов
является кластерный подход[6]. Кластерный подход основывается на представлении
задачи сегментациикак задачи
кластерного анализа. Сама программа в этом случае является точкой n-мерного пространства. Для решения задачисегментации программкластерный подходопирается на классическуюграфовую
постановкузадачи сегментации и
обладающей некоторыми специфическими особенностями. Формулировказадачи состоит в следующем: Требуется
разрезать вершины полного, взвешенного графа на части таким образом,чтобы суммарный вес вершин, попавших в каждое
подмножество не превосходил заданного
значения, а суммарный вес внешних по отношению к разбиению ребер был бы
минимален. При решении различных прикладных
задач распознавания и классификации успешно применяется метод опорных подмножеств.
Впервые метод опорных подмножеств был описан Ю.И. Журавлевым. Принципиальную возможность
применения метода опорных подмножеств для решения задачи сегментации было
описана в работе[6]. Основной трудностью здесь является содержательная интерпретация
параметров данного метода, задающих соответствующий класс алгоритмов вычисления
оценок. Интересным подходом для решения
задач распознавания образов и классификаций, а также некоторых дискретных
экстремальных задач,в частности задачи сегментации
является нейросетевой подход. СПИСОК ЛИТЕРАТУРЫ 2001.-208с. 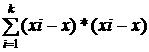 =
=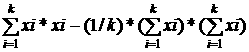 xi-измерение
i-гообьекта.
xi-измерение
i-гообьекта.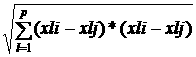 ;
;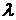 , и сдвига
, и сдвига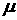 с критерием
аппроксимаций.,)=
с критерием
аппроксимаций.,)=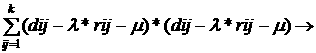 ;
;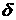 Q с элементами
равной1еслиdij
Q с элементами
равной1еслиdij
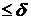 , и равные
0в противном случае. Близость между
матрицами Q иRk оценивается расстоянием Хемминга .
, и равные
0в противном случае. Близость между
матрицами Q иRk оценивается расстоянием Хемминга .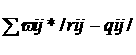 ;
; весовые коэффициенты.
весовые коэффициенты.