Принципы проектирования и использования многомерных баз данных
| Загрузить архив: | |
| Файл: vdv-0550.zip (36kb [zip], Скачиваний: 26) скачать |
Кафедра "КСУ"
Реферат
"Принципы проектирования и использования многомерных баз данных"
Введение
Сегодня все большее число организаций приходит к пониманию того, что без наличия своевременной и объективной информации о состоянии рынка, прогнозирования его перспектив, постоянной оценки эффективности функционирования собственных структур и анализа взаимоотношений с бизнес-партнерами и конкурентами их дальнейшее развитие становится практически невозможным. Поэтому не удивительно то внимание, которое сегодня уделяется средствам реализации и концепциям построения информационных систем, ориентированных на аналитическую обработку данных. И в первую очередь это касается систем управления базами данных, основанными на многомерном подходе - МСУБД.
Следует заметить, что МСУБД не являются изобретением девяностых годов, а сам многомерный подход возник практически одновременно и параллельно с реляционным. Однако, только начиная с середины девяностых годов, а точнее с 1993 г., интерес к МСУБД начал приобретать всеобщий характер. Именно в этом году появилась новая программная статья одного из основоположников реляционного подхода Э. Кодда [1], в которой он сформулировал 12 основных требований к средствам реализации OLAP (табл. 1) и произвел анализ некоторых как субъективных, так и вполне объективных недостатков реляционного подхода, затрудняющих его использование в задачах, требующих сложной аналитической обработки данных.
|
1 |
Многомерное представление данных |
Средства должны поддерживать многомерный на концептуальном уровне взгляд на данные. |
|
2 |
Прозрачность |
Пользователь не должен знать о том, какие конкретные средства используются для хранения и обработки данных, как данные организованы и откуда они берутся. |
|
3 |
Доступность |
Средства должны сами выбирать и связываться с наилучшим для формирования ответа на данный запрос источником данных. Средства должны обеспечивать автоматическое отображение их собственной логической схемы в различные гетерогенные источники данных. |
|
4 |
Согласованная производительность |
Производительность практически не должна зависеть от количества Измерений в запросе. |
|
5 |
Поддержка архитектуры клиент-сервер |
Средства должны работать в архитектуре клиент-сервер. |
|
6 |
Равноправность всех измерений |
Ни одно из измерений не должно быть базовым, все они должны быть равноправными (симметричными). |
|
7 |
Динамическая обработка разреженных матриц |
Неопределенные значения должны храниться и обрабатываться наиболее эффективным способом. |
|
8 |
Поддержка многопользовательского режима работы с данными |
Средства должны обеспечивать возможность работать более чем одному пользователю. |
|
9 |
Поддержка операций на основе различных измерений |
Все многомерные операции (например Агрегация) должны единообразно и согласованно применяться к любому числу любых измерений. |
|
10 |
Простота манипулирования данными |
Средства должны иметь максимально удобный, естественный и комфортный пользовательский интерфейс. |
|
11 |
Развитые средства представления данных |
Средства должны поддерживать различные способы визуализации (представления) данных. |
|
12 |
Неограниченное число измерений и уровней агрегации данных |
Не должно быть ограничений на число поддерживаемых Измерений. |
Таблица 1. (12 правил оценки средств для OLAP).
Набор этих требований, послуживших де-факто определением OLAP, достаточно часто вызывает различные нарекания, так как здесь смешаны:
·
·
·
Многомерное представление данных и OLAP уже стали сегодня одними из наиболее широко распространенных концепций построения аналитических систем.
Требования к средствам реализации систем оперативной и аналитической обработки данных
При первом знакомстве с многомерным подходом к организации данных достаточно часто возникают два противоречивых вопроса.
Для чего собственно нужны МСУБД и нужно ли тратить время и средства на их освоение и приобретение, если все те же задачи можно решить и средствами традиционных РСУБД?
И обратный:
Почему МСУБД ограничивают себя исключительно приложениями, ориентированными на анализ данных и почему бы на их основе не реализовывать традиционные системы оперативной обработки данных?
И несмотря на то, что эти вопросы выражают достаточно противоположные точки зрения, ответ на них звучит приблизительно одинаково: "Главное достоинство МСУБД состоит именно в том, что они узко специализированны и область их применения - интерактивная аналитическая обработка агрегированных исторических и прогнозируемых данных".
Агрегированные данные. Пользователя, занимающегося анализом, редко интересуют детализированные данные. Более того, чем выше уровень пользователя (руководителя, управляющего, аналитика), тем выше уровень агрегации данных, используемых им для принятия решения. Рассмотрим в качестве примера фирму по продаже автомобилей. Коммерческого директора такой фирмы мало интересует вопрос: "Какого цвета "Жигули" успешнее всего продает один из ее менеджеров - Петров: белого или красного?" Для него важно, какие модели и какие цвета предпочитают в данном регионе. Его также мало интересует детализация на уровне контракта, часа или даже дня. Например, если выяснится, что "ВАЗ2108 Красного цвета" чаще покупают в утренние часы, этот факт скорее заинтересует психиатра, а не коммерческого аналитика. Для правильного формирования склада ему важна и необходима информация на уровне декады, месяца или даже квартала.
Исторические данные. Важнейшим свойством данных в аналитических задачах является их Исторический характер. После того как зафиксировано, что Петров в июне 1996 г. продал 2 автомобиля "Волга" и 12 автомобилей "Жигули", данные об этом событии становятся историческим (свершившимся) фактом. И после того, как информация об этом факте получена, верифицирована и заведена в БД, она может быть сколько угодно раз считана оттуда, но уже не может и не должна быть изменена. Историчность данных предполагает не только высокий уровень статичности (неизменности) как собственно данных (например: Петров продал в 1995 г. 51 автомобиль "Жигули ВАЗ2105"), так и их взаимосвязей (например: в 1995 г. Петров работал в Восточном Регионе; в 1995 г. продавались автомобили модели ВАЗ2105). А это, в свою очередь, дает возможность использовать специализированные, основанные на предположении о статичности данных и их взаимосвязей методы загрузки, хранения, индексации и выборки.
Другим неотъемлемым свойством Исторических данных является обязательная спецификация Времени, которому эти данные соответствуют. Причем Время является не только наиболее часто используемым критерием выборки, но и одним из основных критериев, по которому данные упорядочиваются в процессе обработки и представления пользователю. А это накладывает соответствующие требования как на используемые механизмы хранения и доступа:
для уменьшения времени обработки запросов желательно, чтобы уже в БД данные хранились (были предварительно отсортированы) в том порядке, в котором они наиболее часто запрашиваются;
так и на языки описания и манипулирования данными, например:
во многих организациях используются как общепринятые, так и собственные календарные циклы (финансовый год может начинаться не в январе как календарный, а, например, в июне);
время является стандартным параметром практически любой аналитической, статистической или финансовой функции (прогноз, нарастающий итог, переходящий запас, скользящее среднее и т.д.).
Прогнозируемые данные. Когда говорится о неизменности и статичности данных в аналитических системах, имеется в виду неизменность исключительно Исторических данных (данных, описывающих уже произошедшие события). Такое предположение ни в коем случае не распространяется на Прогнозируемые данные (данные о событии, которое еще не происходило). И этот момент является весьма существенным.
Например, если мы строим прогноз об объеме продаж на июнь 1997 г. для менеджера Петрова, то, по мере поступления фактических (Исторических) данных за 1996 г., эта цифра может и будет многократно изменяться и уточняться. Более того, достаточно часто прогнозирование и моделирование затрагивает не только будущие, еще не произошедшие, но и прошлые, уже свершившиеся события. Например, анализ: "а, что будет (было бы)... если (бы)..?", строится на предположении о том, что значения некоторых данных, в том числе и из прошлого, отличны от реальных. И для ответа на вопрос:
"Какой был бы Прогноз по объему продаж автомобилей "Волга" для менеджера Петрова на июнь 1997 г., если бы объем продаж "Волг" в июне 1996 г. у него возрос на тот же процент, что объем продаж "Жигулей"?"
потребуется не только вычислить новое, еще не существующее значение Объема Продаж, для еще не наступившего июня 1997 г., но и предварительно вычислить гипотетическое значение Объема продаж, за уже прошедший июнь 1996 г.
На первый взгляд, мы сами противоречим себе, говоря о неизменности данных, как основополагающем свойстве аналитической системы. Но это не так. Это кажущееся противоречие наоборот подчеркивает и усиливает значимость требований к неизменности Исторических данных. Сколько бы мы не упражнялись (например, при анализе: "а что... если..?") со значением объема продаж за июнь 1996 г., значения Исторических (реальных) данных должны оставаться неизменными. Конечно, предположение о неизменности не означает невозможности исправления ошибок, если они были обнаружены в Исторических данных.
В свою очередь, к оперативным данным, отражающим состояние некоторой предметной области в данный текущий момент времени, не применимы такие понятия, как прошлое или будущее. Для них существует единственное понятие - сейчас, а их основное назначение - адекватное детализированное отображение текущих событий (изменений), происходящих в реальном мире. Например:
менеджер Петров продал еще одни "Жигули ВАЗ2106";
менеджера Петрова перевели из Восточного филиала фирмы в Западный.
Вместе с тем изменчивость Оперативных данных ни в коем случае не подразумевает их близость по свойствам к Прогнозируемым данным. Между ними существует коренное различие. Оперативным данным, в отличие от Прогнозируемых, присуще свойство общезначимости, и обычно все пользователи работают с одним и тем же экземпляром данных. После того как в оперативную систему заведены данные о том, что Петров продал еще один автомобиль, эта информация сразу же должна стать доступной всем заинтересованным в ней пользователям. Причем до тех пор, пока это изменение не зафиксировано, ни какой другой пользователь не имеет права изменять строку с информацией о продажах Петрова.
Существенно иная ситуация с Прогнозируемыми данными. Они носят, скорее, личностный (индивидуальный) характер. Вполне реальна ситуация, когда коммерческий директор фирмы и управляющий региональным отделением одновременно решили получить прогноз возможного объема продаж на 1997 г. для Петрова. Однако каждый из них делает собственный прогноз. Каждый из них может использовать свои функции прогнозирования, и, даже если применяется один и тот же метод (или функция), прогноз может основываться на различных исторических интервалах, и результаты, по всей вероятности, будут различны. Поэтому каждый из них работает с собственным экземпляром Прогнозируемых данных (хотя эти данные и относятся формально к одной и той же личности, виду деятельности и времени), и эти данные не должны смешиваться. Конечно, вполне вероятно, что один из этих вариантов будет принят в качестве плановых показателей для Петрова. Но после того, как Прогноз утвержден в качестве Плана, данные просто перейдут в другую категорию и станут Историческими.
Следует заметить, что в области информационных технологий всегда существовало два взаимодополняющих друг друга направления развития:
· транзакционную или операционную) обработку данных;
· DSS).
И практически до настоящего времени, когда говорилось о стремительном росте числа реализаций информационных систем, прежде всего имелись в виду системы, предназначенные исключительно для оперативной обработки данных. Именно для этого изначально и создавались и на это были ориентированы РСУБД, которые сегодня стали основным средством построения информационных систем самого различного масштаба и назначения. Но, являясь высокоэффективным средством реализации систем оперативной обработки данных, РСУБД оказались менее эффективными в задачах аналитической обработки.
Конечно, средствами традиционных РСУБД и на основании данных, хранящихся в реляционной БД, можно построить заранее регламентированный аналитический отчет (табл. 2) и даже Прогноз об ожидаемом объеме продаж автомобилей на следующий год.
|
Характеристика |
Статический анализ |
Динамический анализ |
|
Типы вопросов |
Сколько? Как? Когда? |
Почему? Что будет если? |
|
Время отклика |
Не регламентируется |
Секунды |
|
Типичные операции |
Регламентированный отчет, диаграмма |
Последовательность интерактивных отчетов, диаграмм, экранных форм; динамическое изменение уровней агрегации и срезов данных |
|
Уровень аналитических требований |
Средний |
Высокий |
|
Тип экранных форм |
В основном определенный заранее, регламентированный |
Определяемый пользователем |
|
Уровень агрегации данных |
Детализированные и суммарные |
В основном суммарные |
|
Возраст данных |
Исторические и текущие |
Исторические, текущие и прогнозируемые |
|
Типы запросов |
В основном предсказуемые |
Непредсказуемые, от случаю к случаю |
|
Назначение |
Работа с историческими и текущими данными, регламентированная аналитическая обработка и построение прогнозов |
Работа с историческими, текущими и прогнозируемыми данными. Многопроходный анализ, моделирование |
Таблица 2. (Сравнение характеристик статического (регламентированного) и динамического анализа).
Но, как правило, после просмотра такого отчета у пользователя (аналитика) появится не готовый ответ, а новая серия вопросов. Однако, если бы ему захотелось получить ответ на новый вопрос, он может ждать его часы, а иногда и дни. Обычно каждый новый непредусмотренный заранее запрос должен быть сначала формально описан, передан программисту, запрограммирован и, наконец, выполнен. Но после того, как аналитик получит долгожданный ответ, достаточно часто оказывается, что решение не могло ждать и оно уже принято, или что случается еще чаще, произошло взаимное непонимание и получен ответ на не совсем тот вопрос. Впрочем, не намного меньшее время затрачивается и на получение ответа и на заранее описанный и запрограммированный запрос.
Более того, для решения большинства аналитических задач, скорее всего, потребуется использование внешних по отношению к РСУБД, специализированных инструментальных средств. Выполнение большинства аналитических функций (например построение прогноза) невозможно без предположения об упорядоченности данных. Но в РСУБД предполагается, что данные в БД не упорядочены (или, более точно, упорядочены случайным образом). Естественно, здесь имеется возможность после выборки данных из БД выполнить их сортировку и затем аналитическую функцию. Но это потребует дополнительных затрат времени на сортировку. Сортировка должна будет проводиться каждый раз при обращении к этой функции, и, самое главное, такая функция может быть определена и использована только во внешнем по отношению к РСУБД пользовательском приложении и не может быть встроенной функцией языка SQL.
Не менее важно и то, что многие критически необходимые для оперативных систем функциональные возможности, реализуемые в РСУБД, являются избыточными для аналитических задач. Например, в аналитических системах (табл. 3) данные обычно загружаются достаточно большими порциями из различных внешних источников (оперативных БД, заранее подготовленных плоских файлов, электронных таблиц). И, как правило, время и последовательность работ по загрузке, резервированию и обновлению данных могут быть спланированы заранее. Поэтому в таких системах обычно не требуются и, соответственно, не предусматриваются, например, развитые средства обеспечения целостности, восстановления и устранения взаимных блокировок и т.д. А это не только существенно облегчает и упрощает сами средства реализации, но и значительно снижает внутренние накладные расходы и, следовательно, повышает производительность при выполнении их основной целевой функции - поиске и выборке данных.
|
Характеристика |
Оперативные |
Аналитические |
|
Частота обновления |
Высокая частота, маленькими порциями |
Малая частота, большими порциями |
|
Источники данных |
В основном внутренние |
В основном внешние (по отношению к аналитической системе) |
|
Возраст данных |
Текущие (за период от нескольких месяцев до одного года) |
В основном исторические (за период в несколько лет, десятки лет) и прогнозируемые |
|
Уровень агрегации данных |
Детализированные данные |
В основном агрегированные данные |
|
Назначение |
Фиксация, оперативный поиск и обработка данных |
Работа с историческими данными, аналитическая обработка, прогнозирование и моделирование |
Таблица 3. (Характеристики данных в системах, ориентированных на оперативную и аналитическую обработку данных).
Многомерная модель данных
"Многомерный взгляд на данные наиболее характерен для пользователя, занимающегося анализом данных" - это утверждение сегодня стало уже почти аксиомой. Однако, что такое многомерное представление, откуда появляется многомерность в трехмерном мире, чем оно отличается и чем оно лучше ставшего уже привычным реляционного представления? И наконец, откуда среди нас появились люди, мыслящие в четырех и более измерениях, и как это им удается - именно эти вопросы возникают практически у любого, впервые прочитавшего это утверждение.
На самом деле все сказанное в этом утверждении - чистая правда, и пользователю, занимающемуся анализом, действительно присуща многомерность мышления. Весь вопрос в том, что понимать под Измерением.
Двухмерное представление данных конечному пользователю
Достаточно очевидно, что даже при небольших объемах данных отчет, представленный в виде двухмерной таблицы (Модели автомобиля по оси Y и Время по оси X), нагляднее и информативнее отчета с реляционной построчной формой организации (рис. 1).
Реляционная модель
|
Модель |
Месяц |
Объем |
|
"Жигули" |
Июнь |
12 |
|
"Жигули" |
Июль |
24 |
|
"Жигули" |
Август |
5 |
|
"Москвич" |
Июнь |
2 |
|
"Москвич" |
Июль |
18 |
|
"Волга" |
Июль |
19 |
Многомерная модель
|
Июнь |
Июль |
Август |
|
|
"Жигули" |
12 |
24 |
5 |
|
"Москвич" |
2 |
18 |
No |
|
"Волга" |
No |
19 |
No |
Рисунок 1. (Реляционная и многомерная модели представления данных).
А теперь представим, что у нас не три модели, а 30 и не три, а 12 различных месяцев. В случае построчного (реляционного) представления мы получим отчет в 360 строк (30х12), который займет не менее 5-6 страниц. В случае же многомерного (в нашем случае двухмерного) представления мы получим достаточно компактную таблицу 12 на 30, которая вполне уместится на одной странице и которую, даже при таком объеме данных, можно реально оценивать и анализировать.
И когда говорится о многомерной организации данных, вовсе не подразумевается то, что данные представляются конечному пользователю (визуализируются) в виде четырех или пятимерных гиперкубов. Это невозможно, да и пользователю более привычно и комфортно иметь дело с двухмерным табличным представлением и двухмерной бизнес-графикой.
Закономерен вопрос: "Где же здесь многомерность, откуда она берется и куда исчезает?" Ответ прост. Когда говорится о многомерности, имеется в виду не многомерность визуализации, а многомерное представление при описании структур данных и поддержка многомерности в языках манипулирования данными.
Многомерное представление при описании структур данных
Основными понятиями, с которыми оперирует пользователь и проектировщик в многомерной модели данных, являются:
· Dimension);
· Cell).
Иногда вместо термина "Ячейка" используется термин "Показатель" (Measure).
Измерение - это множество однотипных данных, образующих одну из граней гиперкуба. Например - Дни, Месяцы, Кварталы, Годы - это наиболее часто используемые в анализе временные Измерения. Примерами географических измерений являются: Города, Районы, Регионы, Страны и т.д.
В многомерной модели данных Измерения играют роль индексов, используемых для идентификации конкретных значений (Показателей), находящихся в Ячейках гиперкуба.
В свою очередь, Показатель - это поле (обычно цифровое), значения которого однозначно определяются фиксированным набором Измерений. Взависимости от того, как формируются его значения, Показатель может быть определен, как:
· Variable) - значения таких Показателей один раз вводятся из какого-либо внешнего источника или формируются программно и затем в явном виде хранятся в многомерной базе данных (МБД);
· Formula) - значения таких Показателей вычисляются по некоторой заранее специфицированной формуле. То есть для Показателя, имеющего тип Формула, в БД хранится не его значения, а формула, по которой эти значения могут быть вычислены.
Заметим, что это различие существует только на этапе проектирования и полностью скрыто от конечных пользователей.
В примере на рис. 1 каждое значение поля Объем продаж однозначно определяется комбинацией полей:
Модель автомобиля;
Месяц продаж.
Но в реальной ситуации для однозначной идентификации значения Показателя, скорее всего, потребуется большее число измерений, например:
Модель автомобиля;
Менеджер;
Время (например Год).
Измерения:
Время (Год) - 1994, 1995, 1995
Менеджер - Петров, Смирнов, Яковлев
Показатель:
Объем Продаж
И в терминах многомерной модели речь будет идти уже не о двухмерной таблице, а о трехмерном гиперкубе:
первое Измерение - Модель автомобиля;
второе Измерение - Менеджер, продавший автомобиль;
третье Измерение - Время (Год);
на пересечении граней которого находятся значения Показателя Объем продаж.
Заметим, что, в отличие от Измерений, не все значения Показателей должны иметь и имеют реальные значения. Например, Менеджер Петров в 1994 г. мог еще не работать в фирме, и в этом случае все значения Показателя Объем продаж за этот год будут иметь неопределенные значения.
Гиперкубические и поликубические модели данных
В различных МСУБД используются два основных варианта организации данных:
· Гиперкубическая модель;
· Поликубическая модель.
В чем состоит разница? Системы, поддерживающие Поликубическую модель (примером является Oracle Express Server), предполагают, что в МБД может быть определено несколько гиперкубов с различной размерностью и с различными Измерениями в качестве их граней. Например, значение Показателя Рабочее Время Менеджера, скорее всего, не зависит от Измерения Модель Автомобиля и однозначно определяется двумя Измерениями: День и Менеджер. В Поликубической модели в этом случае может быть объявлено два различных гиперкуба:
Двухмерный - для Показателя Рабочее Время Менеджера;
Трехмерный - для Показателя Объем Продаж.
В случае же Гиперкубической модели предполагается, что все Показатели должны определяться одним и тем же набором Измерений. То есть только из-за того, что Объем Продаж определяется тремя Измерениями, при описании Показателя Рабочее Время Менеджера придется также использовать три Измерения и вводить избыточное для этого Показателя Измерение Модель Автомобиля.
Операции манипулирования Измерениями
Формирование "Среза". Пользователя редко интересуют все потенциально возможные комбинации значений Измерений. Более того, он практически никогда не работает одновременно сразу со всем гиперкубом данных. Подмножество гиперкуба, получившееся в результате фиксации значения одного или более Измерений, называется Срезом (Slice). Например, если мы ограничим значение Измерения Модель Автомобиля = "ВАЗ2108", то получим подмножество гиперкуба (в нашем случае - двухмерную таблицу), содержащее информацию об истории продаж этой модели различными менеджерами в различные годы.
Операция "Вращение". Изменение порядка представления (визуализации) Измерений (обычно применяется при двухмерном представлении данных) называется Вращением (Rotate). Эта операция обеспечивает возможность визуализации данных в форме, наиболее комфортной для их восприятия. Например, если менеджер первоначально вывел отчет, в котором Модели автомобилей были перечислены по оси X, а Менеджеры по оси Y, он может решить, что такое представление мало наглядно, и поменять местами координаты (выполнить Вращение на 90 градусов).
Отношения и Иерархические Отношения. В нашем примере значения Показателей определяются только тремя измерениями. На самом деле их может быть гораздо больше и между их значениями обычно существуют множество различных Отношений (Relation) типа "один ко многим".
Например, каждый Менеджер может работать только в одном подразделении, а каждой модели автомобиля однозначно соответствует фирма, которая ее выпускает:
Менеджер ->Подразделение;
Модель Автомобиля ->Фирма-Производитель.
Заметим, что для Измерений, имеющих тип Время (таких как День, Месяц, Квартал, Год), все Отношения устанавливаются автоматически, и их не требуется описывать.
В свою очередь, множество Отношений может иметь иерархическую структуру - Иерархические Отношения (Hierarchical Relationships). Вот только несколько примеров таких Иерархических Отношений:
День -> Месяц -> Квартал -> Год;
Менеджер -> Подразделение -> Регион -> Фирма -> Страна;
Модель Автомобиля -> Завод-Производитель -> Страна.
И часто более удобно не объявлять новые Измерения и затем устанавливать между ними множество Отношений, а использовать механизм Иерархических Отношений. В этом случае все потенциально возможные значения из различных Измерений объединяются в одно множество. Например, мы можем добавить к множеству значений Измерения Менеджер ("Петров", "Сидоров", "Иванов", "Смирнов"), значения Измерения Подразделение ("Филиал 1", "Филиал 2", "Филиал 3") и Измерения Регион ("Восток", "Запад") и затем определить между этими значениями Отношение Иерархии.
Операция Агрегации. С точки зрения пользователя, Подразделение, Регион, Фирма, Страна являются точно такими же Измерениями, как и Менеджер. Но каждое из них соответствует новому, более высокому уровню агрегации значений Показателя Объем продаж. В процессе анализа пользователь не только работает с различными Срезами данных и выполняет их Вращение, но и переходит от детализированных данных к агрегированным, т.е. производит операцию Агрегации (Drill Up). Например, посмотрев, насколько успешно в 1995 г. Петров продавал модели "Жигули" и "Волга", управляющий может захотеть узнать, как выглядит соотношение продаж этих моделей на уровне Подразделения, где Петров работает. А затем получить аналогичную справку по Региону или Фирме.
Операция Детализации. Переход от более агрегированных к более детализированным данным называется операцией Детализации (Drill Down). Например, начав анализ на уровне Региона, пользователь может захотеть получить более точную информацию о работе конкретного Подразделения или Менеджера.
Проектирование многомерной БД
Данная работа ни в коем случае не посвящена рассмотрению методологии проектирования МБД, и здесь излагаются только самые общие элементы подхода к процессу и способам проектирования. Тем не менее излагаемый подход не только позволит наиболее полно понять как достоинства, так и ограничения многомерного подхода, но и послужит хорошей основой для быстрого построения систем.
Определение вопросов
Основное назначение МСУБД - реализация систем, ориентированных на динамический, многомерный анализ исторических и текущих данных, анализ тенденций, моделирование и прогнозирование будущего. Причем такие системы в большой степени ориентированы на обработку произвольных, заранее не регламентированных запросов, и при их разработке фактически отсутствует этап проектирования регламентированных пользовательских приложений (наиболее ответственный и трудоемкий в традиционных оперативных системах).
Проектирование МБД обычно начинается с определения вопросов (табл. 4), с которыми конечные пользователи хотели бы обратиться к системе. Причем на этом этапе интерес представляют даже не сами тексты вопросов, а понимание того, о каких личностях, местах, событиях и объектах в них спрашивается.
|
Подразделение |
Менеджер |
Временной интервал |
Вопрос |
|
Отдел |
Петров |
3 года |
На сколько процентов увеличились продажи "Жигулей" в Западном регионе после январской рекламной кампании в еженедельнике "Западный Вестник"? |
|
Финансовый отдел |
Смирнов |
5 лет |
Какие региональные подразделения превысили в третьем квартале запланированные расходы на командировки и как это соотносится с ростом их прибыли (в абсолютных и относительных величинах)? |
|
Коммерческий отдел |
Левшин |
10 лет |
Какие два варианта скидок наиболее эффективны в Западном регионе в летний период при продаже автомобилей "Жигули", на основе данных за последние 10 лет? |
|
Отдел развития бизнеса |
Васильева |
5 лет |
Как повлияло на объемы продаж открытие двух новых отделений в Южном регионе и на какой процент могут увеличиться продажи в Северном регионе, если в этом году там будет открыто 3 новых офиса? |
Таблица 4. (Список потенциальных вопросов менеджеров фирмы).
Рассмотрим в качестве примера вопрос сотрудника коммерческого отдела ("Какие два варианта скидок наиболее эффективны в Западном регионе в летний период при продаже автомобилей "Жигули", на основе данных за последние 10 лет?"). Как было сказано выше, на этом этапе мы не собираемся программировать этот вопрос, тем более, что инструментальные средства конечного пользователя позволят легко сформулировать его в интерактивном режиме, без написания строк кода. Сейчас нам важнее понять, какие данные должны быть в МБД, оценить временные интервалы, которые должны отражаться, понять трудоемкость и реальность подготовки и загрузки этих данных.
После того как первичный анализ вопросов выполнен, и получено представление о том, какие данные потенциально могут выступать в качестве Показателей и Измерений (табл. 5), можно переходить к проектированию ее структуры - определению конкретных Измерений, их взаимосвязей и уровней агрегации хранимых данных.
|
Наименование информации |
Временной интервал |
Количество строк |
Тип |
Источник |
|
Месяц |
10 лет |
12 * 10 |
Измерение |
Оперативная система "Продажи", архив |
|
Регион |
10 лет |
5 |
Измерение |
- "" - |
|
Модель автомобиля |
10 лет |
200 |
Измерение |
- "" - |
|
Типы скидок |
10 лет |
4 |
Измерение |
- "" - |
|
Объем продаж в USD |
10 лет |
200 * 12 * 10 * 5 * 4 |
Показатель |
- "" - |
Таблица 5. (Данные, необходимые для ответа на вопрос аналитика коммерческого отдела).
Критерии выбора уровня агрегации
Если спросить пользователя, какой уровень детализации ему желателен, он не задумываясь ответит - максимально возможный. Однако стоит оценить, сколько такое решение может стоить, и попытаться определить возможный экономический эффект от наличия данных на каждом новом уровне детализации.
Например, выбрав в качестве уровня агрегации Год, вы получите возможность проанализировать общие тенденции автомобильного рынка и спрогнозировать динамику его развития. Выбрав же в качестве уровня агрегации Месяц или Неделю, вы, кроме того, сможете спрогнозировать спрос на конкретные модели в конкретные моменты времени. И хотя автомобили - товар не сезонный, скорее всего, весной и летом их покупают больше, чем осенью и зимой. Это позволит отследить возможные сезонные колебания, рациональнее формировать свой склад и более эффективно проводить политику формирования сезонных скидок и распродаж. А если в систему введена информация о затратах на маркетинг, появится возможность проследить эффект от каждого конкретного маркетингового мероприятия.
Выбор в качестве уровня агрегации Номер Контракта/Счета позволит перейти на качественно новый уровень анализа. На этом уровне можно будет учитывать взаимосвязи между конкретным Автомобилем, Менеджером и Покупателем. А поскольку при покупке автомобиля заполняется множество документов, то доступна достаточно детальная информация о каждом конкретном Покупателе (Возраст, Пол, Место жительства, Вид оплаты и т.д.). Теперь вы сможете проанализировать не только рынок, но и заглянуть внутрь своей фирмы и всесторонне проанализировать эффективность работы каждого Менеджера и Подразделения. Но наиболее ценное, что вы получаете, - это информация о Регионах и Покупателях. Например, вы не только сможете оценить, какие Модели автомобилей пользуются наибольшим спросом в конкретном регионе сегодня, но на основе анализа истории и структуры автомобильного рынка в более развитых, с точки зрения автомобилизации, регионах попытаться оценить динамику спроса и перспективы различных Моделей в остальных регионах.
Однако переход на каждый следующий уровень детализации и добавление новых источников данных могут привести к увеличению, иногда более чем на порядок, размера целевой МБД и соответствующему удорожанию и усложнению аппаратного решения.
Рассмотрим в качестве примера Показатель Объем продаж. Анализ предметной области показывает, что он однозначно определяется комбинацией четырех Измерений:
1. {Год | Полугодие | Квартал | Месяц | Неделя | День | Счет}
2. {Страна | Регион | Филиал | Менеджер}
3. {Фирма-Производитель | Завод-Производитель | Модель Автомобиля}
4. {Тип скидки}
Выбрав уровень детализации:
1. День (365 * 10 = 3650 различных значений),
2. Менеджер (300 различных значений),
3. Модель Автомобиля (100 различных значений),
4. Тип Скидки (4 различных значения),
получим куб, состоящий из 438000000 ячеек. Но в основе используемого в МСУБД способа хранения данных лежит предположение о том, что внутри, в данном случае четырехмерного гиперкуба, нет пустот. Данные в МСУБД представлены в виде разреженных матриц с заранее фиксированной размерностью. При этом значения Показателей хранятся в виде множества логически упорядоченных блоков (массивов), имеющих фиксированную длину, причем именно блок является минимальной индексируемой единицей.
Таким образом, в нашей БД будет сразу же зарезервировано место для всех 438 млн. значений Показателя Объем Продаж. Причем цифры "300 менеджеров" и "100 моделей автомобилей" вовсе не означают того, что сегодняшняя номенклатура фирмы - 100 различных моделей, которые продают 300 человек. Цифра 300 говорит о том, что в фирме за 10 лет ее существования работало 300 различных менеджеров. Сегодня же их может быть, например, всего 30.
Попробуем оценить, какой процент ячеек в нашем случае будет содержать реальные значения. Предположим, что в среднем в фирме постоянно работает около 30 менеджеров, менеджер продает в день 10 различных моделей и при продаже каждого автомобиля может быть использован только один вариант скидки. Тогда 3650 * 30 * 10 * 1 = 1095000. То есть только 0,25% ячеек куба будет содержать реальные значения данных. И хотя в МСУБД обычно предполагается, что блоки, полностью заполненные неопределенными значениями, не хранятся, как правило, это не обеспечивает полного решения проблемы.
Загрузка данных
Как уже было сказано выше, основное назначение МСУБД - работа с достаточно стабильными во времени данными, и данные в таких системах достаточно редко вводятся в интерактивном режиме. Обычно загрузка выполняется из внешних источников: оперативных БД, электронных таблиц или из заранее подготовленных плоских файлов.
В OLAP системах загрузка данных может производиться практически из различных внешних источников данных, включая:
различные РСУБД;
плоские файлы с фиксированной структурой записей;
электронных таблиц (Lotus 1-2-3, Ecxell и т.д.);
в интерактивном режиме через специально написанные пользовательские приложения.
Следует заметить, что в данные могут храниться как на постоянной основе, так и загружаться динамически, в тот момент, когда к ним обратится пользователя. Таким образом, имеется возможность постоянно хранить в МБД только ту информацию, которая наиболее часто запрашивается пользователями. Для всех остальных данных хранятся только описания их структуры и программы их выгрузки из центральной (обычно реляционной) БД. И хотя при первичном обращении к таким виртуальным данным, время отклика может оказаться достаточно продолжительным, такое решение обеспечивает высокую гибкость и требует более дешевых аппаратных средств. А если впоследствии оказывается, что интенсивность обращения к данным, имеющим статус временных, высока, их статус может быть легко изменен.
Заключение
В заключение необходимо сказать, что было бы не совсем правильно противопоставлять или говорить о какой-либо серьезной взаимной конкуренции реляционного и многомерного подходов. Правильнее сказать, что эти два подхода взаимно дополняют друг друга. Как отметил Э. Кодд [1], реляционный подход никогда не предназначался для решения на его основе задач, требующих синтеза, анализа и консолидации данных. И изначально предполагалось, что такого рода функции должны реализовываться с помощью внешних по отношению к РСУБД, инструментальных средств.
Но именно на решение таких задач и ориентированы МСУБД. Область, где они наиболее эффективны, это хранение и обработка высоко агрегированных и стабильных во времени данных. И их применение оправдано только при выполнении двух требований.
Уровень агрегации данных в БД достаточно высок, и, соответственно, объем БД не очень велик (не более нескольких гигабайт).
В качестве граней гиперкуба выбраны достаточно стабильные во времени Измерения (с точки зрения неизменности их взаимосвязей), и, соответственно, число несуществующих значений в ячейках гипрекуба относительно невелико.
Поэтому уже сегодня МСУБД все чаще используются не только как самостоятельный программный продукт, но и как аналитические средства переднего плана, к системам Хранилищ Данных или традиционным оперативным системам, реализуемым средствами РСУБД.
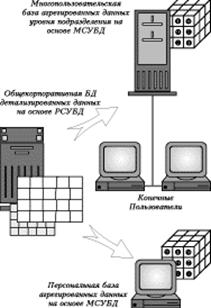
Рисунок 1.(Многоуровневая архитектура).
Причем такое решение позволяет наиболее полно реализовать и использовать достоинства каждого из подходов: компактное хранение детализированных данных и поддержка очень больших БД, обеспечиваемые РСУБД и простота настройки и хорошие времена отклика, при работе с агрегированными данными, обеспечиваемые МСУБД.
Литература
1. Codd, S.B. Codd, C.T. Salley. Providing OLAP (On-Line Analytical Processing) to User-Analysts: An IT Mandate. - E.F.Codd & Associates, 1993.
2. Guide to OLAP Terminology. - Kenan Systems Corporation, 1995