Курсовая. Моделирование работы станка
| Сдавался/использовался | Волгоград, 2005 Руководитель: А.А. Теткин |
| Загрузить архив: | |
| Файл: Моделирование работы станка.doc.zip (246kb [zip], Скачиваний: 1) скачать |
ФГОУ СПО «Волгоградский технологический коледж»
«Проект защитил
с оценкой »
А.И. Сухинин
30.05.05
Моделирование работы станка
с поломками
Курсовой проект
КП 11. 230105. 51. 0535 ПЗ
Разработчик А.И. Сухинин
17.06.11
Рук.проекта А.А. Теткин
17.06.11
Содержание
1. Введение………………………………………………………………………3
2. Моделирование систем массового обслуживания…………………………5
2.1 Структура и параметры эффективности и качества функционирования СМО………………………………………………………………………………5
2.2 Классификация СМО и их основные элементы………………...…………6
2.3 Процесс имитационного моделирования…………………………………12
3. Описание моделируемой системы……………………………………...…..16
3.1Модельное время……………………………………………………….…..17
3.2 Используемые классы и объекты……………...………………….……….17
3.3 События и методы………………………………………………….………19
4. Программная реализация на С++…. ………………………………….……21
5. Анализ результатов работы программы……………………………....……35
6. Заключение……………….……………………………………………...…..38
7. Список использованной литературы…………………………………….…39
ЕСЛИ НУЖНА ПРОГРАММА НА С++ ОБРАЩАЙТЕСЬ: saneek93@mail.ru
Оформление и правка возможна
1. Введение
Во многих областях практической деятельности человека мы сталкиваемся с необходимостью пребывания в состоянии ожидания. Подобные ситуации возникают в очередях в билетных кассах, в крупных аэропортах, при ожидании обслуживающим персоналом самолетов разрешения на взлет или посадку, на телефонных станциях в ожидании освобождения линии абонента, в ремонтных цехах в ожидании ремонта станков и оборудования, на складах снабженческо-сбытовых организаций в ожидании разгрузки или погрузки транспортных средств. Во всех перечисленных случаях имеем дело с массовостью и обслуживанием. Изучением таких ситуаций занимается теория массового обслуживания.
В теории систем массового обслуживания (в дальнейшем просто – CMО) обслуживаемый объект называют требованием. В общем случае под требованием обычно понимают запрос на удовлетворение некоторой потребности, например, обслуживание автомобиля на заправочной станции, разговор с абонентом, посадка самолета, покупка билета, получение материалов на складе и т.д
На первичное развитие теории массового обслуживания оказали особое влияние работы датского ученого А.К. Эрланга (1878-1929).
Теория массового обслуживания – область прикладной математики, занимающаяся анализом процессов в системах производства, обслуживания, управления, в которых однородные события повторяются многократно, например, на предприятиях бытового обслуживания; в системах приема, переработки и передачи информации; автоматических линиях производства и др.
Задача теории массового обслуживания – установить зависимость результирующих показателей работы системы массового обслуживания (вероятности того, что заявка будет обслужена; математического ожидания числа обслуженных заявок и т.д.) от входных показателей (количества каналов в системе, параметров входящего потока заявок и т.д.). Результирующими показателями или интересующими нас характеристиками СМО являются – показатели эффективности СМО, которые описывают способна ли данная система справляться с потоком заявок.
В теории СМО рассматриваются такие случаи, когда поступление требований происходит через случайные промежутки времени, а продолжительность обслуживания требований не является постоянной, т.е. носит случайный характер. В силу этих причин одним из основных методов математического описания СМО является аппарат теории случайных процессов.
Основной задачей теории СМО является изучение режима функционирования обслуживающей системы и исследование явлений, возникающих в процессе обслуживания. Так, одной из характеристик обслуживающей системы является время пребывания требования в очереди. Очевидно, что это время можно сократить за счет увеличения количества обслуживающих устройств. Однако каждое дополнительное устройство требует определенных материальных затрат, при этом увеличивается время бездействия обслуживающего устройства из-за отсутствия требований на обслуживание, что также является негативным явлением. Следовательно, в теории СМО возникают задачи оптимизации: каким образом достичь определенного уровня обслуживания (максимального сокращения очереди или потерь требований) при минимальных затратах, связанных с простоем обслуживающих устройств.
Имитационное моделирование реализуются программно с использованием различных языков, как универсальных - БЕЙСИК, РАСКАЛЬ, С, С++ и т.д., так и специализированных, предназначенных для построения имитационных моделей - СИМСКРИПТ, СТАМ/КЛАСС, GPSS, SLAM, Pilgrim и др.
Целью данной курсовой работы является разработка имитационной модели с регулярным входным потоком, отсутствующей очередью и естественным отсчетом времени т.е моделирование работы больничной палаты. Основой для разработки модели в данной курсовой работе является метод имитационного моделирования. Так же курсовая работа предполагает создание программы на языке C++, обеспечивающей ввод исходной информации, ее обработку, реализацию алгоритма имитации процесса и выдачу необходимой информации.
2. Моделирование систем массового обслуживания
2.1 Структура и параметры эффективности и качества функционирования СМО
Многие экономические задачи связаны с системами массового обслуживания, т.е. такими системами, в которых, с одной стороны, возникают массовые запросы (требования) на выполнение каких-либо услуг, с другой – происходит удовлетворение этих запросов. СМО включает в себя следующие элементы: источник требований, входящий поток требований, очередь, обслуживающие устройства (каналы обслуживания), выходящий поток требований. Исследованием таких систем занимается теория массового обслуживания.
Средства, обслуживающие требования, называютсяобслуживающими устройствами или каналами обслуживания. Например, к ним относятся заправочные устройства на АЗС, каналы телефонной связи, посадочные полосы, мастера-ремонтники, билетные кассиры, погрузочно-разгрузочные точки на базах и складах.
Методами теории массового обслуживания могут быть решены многие задачи исследования процессов, происходящих в экономике. Так, в организации торговли эти методы позволяют определить оптимальное количество торговых точек данного профиля, численность продавцов, частоту завоза товаров и другие параметры. Другим характерным примером систем массового обслуживания могут служить заправочные станции, и задачи теории массового обслуживания в данном случае сводятся к тому, чтобы установить оптимальное соотношение между числом поступающих на заправочную станцию требований на обслуживание и числом обслуживающих устройств, при котором суммарные расходы на обслуживания и убытки от простоя были бы минимальными. Теория массового обслуживания может найти применение и при расчете площади складских помещений, при этом складская площадь рассматривается как обслуживающее устройство, а прибытие транспортных средств под выгрузку – как требование. Модели теории массового обслуживания применяются также при решении ряда задач организации и нормирования труда, других социально-экономических проблем.
Каждая СМО включает в свою структуру некоторое число обслуживающих устройств, называемых каналами обслуживания (к их числу можно отнести лиц, выполняющих те или иные операции, - кассиров, операторов, менеджеров, и т.п.), обслуживающих некоторый поток заявок (требований), поступающих на ее вход в случайные моменты времени. Обслуживание заявок происходит за неизвестное, обычно случайное время и зависит от множества самых разнообразных факторов. После обслуживания заявки канал освобождается и готов к приему следующей заявки. Случайный характер потока заявок и времени их обслуживания приводит к неравномерности загрузки СМО - перегрузке с образованием очередей заявок или недогрузке - с простаиванием ее каналов. Случайность характера потока заявок и длительности их обслуживания порождает в СМО случайный процесс, для изучения которого необходимы построение и анализ его математической модели. Изучение функционирования СМО упрощается, если случайный процесс является марковским (процессом без последействия, или без памяти), когда работа СМО легко описывается с помощью конечных систем обыкновенных линейных дифференциальных уравнений первого порядка, а в предельном режиме (при достаточно длительном функционировании СМО) посредством конечных систем линейных алгебраических уравнений. В итоге показатели эффективности функционирования СМО выражаются через параметры СМО, потока заявок и дисциплины.
Из теории известно, чтобы случайный процесс являлся Марковским, необходимо и достаточно, чтобы все потоки событий (потоки заявок, потоки обслуживаний заявок и др.), под воздействием которых происходят переходы системы из состояния в состояние, являлись пуассоновским, т.е. обладали свойствами последствия (для любых двух непересекающихся промежутков времени число событий, наступающих за один из них, не зависит от числа событий, наступающих за другой) и ординарности (вероятность наступления за элементарным, или малый, промежуток времени более одного события пренебрежимо мала по сравнению с вероятностью наступления за этот промежуток времени одного события). Для простейшего пуассоновского потока случайная величина Т (промежуток времени между двумя соседними событиями) распределена по показательному закону, представляя собой плотность ее распределения или дифференциальную функцию распределения.
Если же в СМО характер потоков отличен от пуассоновского, то ее характеристики эффективности можно определить приближенно с помощью Марковской теории массового обслуживания, причем тем точнее, чем сложнее СМО, чем больше в ней каналов обслуживания. В большинстве случаев для обоснованных рекомендаций по практическому управлению СМО совсем не требует знаний точных ее характеристик, вполне достаточно иметь их приближенные значения.
Каждая СМО в зависимости от своих параметров обладает определенной эффективностью функционирования.
Эффективность функционирования СМО характеризуют три основные группы показателей:
- Эффективность использования СМО – абсолютная или относительная пропускные способности, средняя продолжительность периода занятости СМО, коэффициент использования СМО, коэффициент не использования СМО;
- Качество обслуживания заявок- среднее время (среднее число заявок, закон распределения) ожидания заявки в очереди или пребывания заявки в СМО; вероятность того, что поступившая заявка немедленно примется к исполнению;
- Эффективность функционирования пары CМО потребитель, причем под потребителем понимается как совокупность заявок или их некоторый источник (например, средний доход, приносимый СМО за единицу времени эксплуатации, и др).
2.2 Классификация СМО и их основные элементы
СМО классифицируются на разные группы в зависимости от состава и от времени пребывания в очереди до начала обслуживания, и от дисциплины обслуживания требований.
По составу СМО бывают одноканальные (с одним обслуживающим устройством) и многоканальные (с большим числом обслуживающих устройств). Многоканальные системы могут состоять из обслуживающих устройств как одинаковой, так и разной производительности.
По времени пребывания требований в очереди до начала обслуживания системы делятся на три группы:
1) с неограниченным временем ожидания (с ожиданием),
2) с отказами;
3) смешанного типа.
В СМО с неограниченным временем ожидания очередное требование, застав все устройства занятыми, становится в очередь и ожидает обслуживания до тех пор, пока одно из устройств не освободится.
В системах с отказами поступившее требование, застав все устройства занятыми, покидает систему. Классическим примером системы с отказами может служить работа автоматической телефонной станции.
В системах смешанного типа поступившее требование, застав все (устройства занятыми, становятся в очередь и ожидают обслуживания в течение ограниченного времени. Не дождавшись обслуживания в установленное время, требование покидает систему.
Кратко рассмотрим особенности функционирования некоторых из этих ситем.
1. СМО с ожиданием характеризуется тем, что в системе из n (n>=1) любая заявка, поступившая в СМО в момент, когда все каналы заняты, становится в очередь и ожидает своего обслуживания, причем любая пришедшая заявка обслужена. Такая система может находится в одном из бесконечного множества состояний: sn+к(r=1.2…) –все каналы заняты и в очереди находится r заявок.
2. СМО с ожиданием и ограничением на длину очереди отличается от вышеприведенной тем, что эта система может находиться в одном из n+m+1 состояний. В состояниях s0 ,s1,…, sn очереди не существует, так как заявок в системе или нет или нет вообще и каналы свободны (s0), или в системе есть несколько I (I=1,n) заявок, которого обслуживает соответствующее (n+1, n+2,…n+r,…,n+m) число заявок и (1,2,…r,…,m) заявок , стоящих в очереди. Заявка, пришедшая на вход СМО в момент времени, когда в очереди стоят уже m заявок, получает отказ и покидает систему необслуженной.
Т.о, многоканальная СМО работает по сути как одноканальная, когда все n каналов работают как один с дисциплиной взаимопомощи, называемой все как один, но с более высокой интенсивностью обслуживания. Граф состояний подобной подобной системы содержит всего два состояния: s0 (s1)- все n каналов свободны (заняты).
Анализ различных видов СМО с взаимопомощью типа все как один показывает, что такая взаимопомощь сокращает среднее время пребывания заявки в системе, но ухудшает ряд других таких характеристик, как вероятность отказа, пропускная способность, средние число заявок в очереди и время ожидания их выполнения. Поэтому для улучшения этих показателей используется изменение дисциплины обслуживания заявок с равномерной взаимопомощью между каналами следующим образом:
Методы и модели, применяющиеся в теории массового обслуживания, можно условно разделить на аналитические и имитационные.
Аналитические методы теории массового обслуживания позволяют получить характеристики системы как некоторые функции параметров ее функционирования. Благодаря этому появляется возможность проводить качественный анализ влияния отдельных факторов на эффективность работы СМО. Имитационные методы основаны на моделировании процессов массового обслуживания на ЭВМ и применяются, если невозможно применение аналитических моделей.
В настоящее время теоретически наиболее разработаны и удобны в практических приложениях методы решения таких задач массового обслуживания, в которых входящий поток требований является простейшим (пуассоновским).
Для простейшего потока частота поступления требований в систему подчиняется закону Пуассона, т.е. вероятность поступления за время t ровно k требований задается формулой:
Важная характеристика СМО - время обслуживания требований в системе. Время обслуживания одного требования является, как правило, случайной величиной и, следовательно, может быть описано законом распределения. Наибольшее распространение в теории и особенно в практических приложениях получил экспоненциальный закон распределения времени обслуживания. Функция распределения для этого закона имеет вид:
F(t)=1e-µt
Т.е. вероятность того, что время обслуживания не превосходит некоторой величины t, определяется этой формулой, где µ- параметр экспоненциального обслуживания требований в системе, т.е. величина, обратная времени обслуживания tоб:
µ=1/ tоб
Рассмотрим аналитические модели наиболее распространенных СМО с ожиданием, т.е. таких СМО, в которых требования, поступившие в момент, когда все обслуживающие каналы заняты, ставятся в очередь и обслуживаются по мере освобождения каналов.
Общая постановка задачи состоит в следующем. Система имеет n обслуживающих каналов, каждый из которых может одновременно обслуживать только одно требование.
В систему поступает простейший (пауссоновский) поток требований c параметром . Если в момент поступления очередного требования в системе на обслуживании уже находится не меньше n требований (т.е. все каналы заняты), то это требование становится в очередь и ждет начала обслуживания.
В системах с определенной дисциплиной обслуживания поступившее требование, застав все устройства занятыми, в зависимости от своего приоритета, либо обслуживается вне очереди, либо становится в очередь.
Основными элементами СМО являются: входящий поток требований, очередь требований, обслуживающие устройства, (каналы) и выходящий поток требований.
Изучение СМО начинается с анализа входящего потока требований. Входящий поток требований представляет собой совокупность требований, которые поступают в систему и нуждаются в обслуживании. Входящий поток требований изучается с целью установления закономерностей этого потока и дальнейшего улучшения качества обслуживания.
В большинстве случаев входящий поток неуправляем и зависит от ряда случайных факторов. Число требований, поступающих в единицу времени, случайная величина. Случайной величиной является также интервал времени между соседними поступающими требованиями. Однако среднее количество требований, поступивших в единицу времени, и средний интервал времени между соседними поступающими требованиями предполагаются заданными.
Среднее число требований, поступающих в систему обслуживания за единицу времени, называется интенсивностью поступления требований и определяется следующим соотношением:
где Т - среднее значение интервала между поступлением очередных требований.
Для многих реальных процессов поток требований достаточно хорошо описывается законом распределения Пуассона. Такой поток называется простейшим.
Простейший поток обладает такими важными свойствами:
- Свойством стационарности, которое выражает неизменность вероятностного режима потока по времени. Это значит, что число требований, поступающих в систему в равные промежутки времени, в среднем должно быть постоянным. Например, число вагонов, поступающих под погрузку в среднем в сутки должно быть одинаковым для различных периодов времени, к примеру, в начале и в конце декады.
- Отсутствия последействия, которое обуславливает взаимную независимость поступления того или иного числа требований на обслуживание в непересекающиеся промежутки времени. Это значит, что число требований, поступающих в данный отрезок времени, не зависит от числа требований, обслуженных в предыдущем промежутке времени. Например, число автомобилей, прибывших за материалами в десятый день месяца, не зависит от числа автомобилей, обслуженных в четвертый или любой другой предыдущий день данного месяца.
- Свойством ординарности, которое выражает практическую невозможность одновременного поступления двух или более требований (вероятность такого события неизмеримо мала по отношению к рассматриваемому промежутку времени, когда последний устремляют к нулю).
При простейшем потоке требований распределение требований, поступающих в систему подчиняются закону распределения Пуассона:
вероятность того, что в обслуживающую систему за время t поступит именно k требований:
где. - среднее число требований, поступивших на обслуживание в единицу времени.
На практике условия простейшего потока не всегда строго выполняются. Часто имеет место нестационарность процесса (в различные часы дня и различные дни месяца поток требований может меняться, он может быть интенсивнее утром или в последние дни месяца). Существует также наличие последействия, когда количество требований на отпуск товаров в конце месяца зависит от их удовлетворения в начале месяца. Наблюдается и явление неоднородности, когда несколько клиентов одновременно пребывают на склад за материалами. Однако в целом пуассоновский закон распределения с достаточно высоким приближением отражает многие процессы массового обслуживания.
Кроме того, наличие пуассоновского потока требований можно определить статистической обработкой данных о поступлении требований на обслуживание. Одним из признаков закона распределения Пуассона является равенство математического ожидания случайной величины и дисперсии этой же величины, т.е.
Одной из важнейших характеристик обслуживающих устройств, которая определяет пропускную способность всей системы, является время обслуживания.
Время обслуживания одного требования ()- случайная величина, которая может изменятся в большом диапазоне. Она зависит от стабильности работы самих обслуживающих устройств, так и от различных параметров, поступающих в систему, требований (к примеру, различной грузоподъемности транспортных средств, поступающих под погрузку или выгрузку.
Случайная величина полностью характеризуется законом распределения, который определяется на основе статистических испытаний.
На практике чаще всего принимают гипотезу о показательном законе распределения времени обслуживания.
Показательный закон распределения времени обслуживания имеет место тогда, когда плотность распределения резко убывает с возрастанием времени t. Например, когда основная масса требований обслуживается быстро, а продолжительное обслуживание встречается редко. Наличие показательного закона распределения времени обслуживания устанавливается на основе статистических наблюдений.
При показательном законе распределения времени обслуживания вероятность события, что время обслуживания продлиться не более чем t, равна:
где v - интенсивность обслуживания одного требования одним обслуживающим устройством, которая определяется из соотношения:
,(1)
где - среднее время обслуживания одного требования одним обслуживающим устройством.
Следует заметить, что если закон распределения времени обслуживания показательный, то при наличии нескольких обслуживающих устройств одинаковой мощности закон распределения времени обслуживания несколькими устройствами будет также показательным:
где n - количество обслуживающих устройств.
Важным параметром СМО являетсякоэффициент загрузки , который определяется как отношение интенсивности поступления требований к интенсивности обслуживания v.
(2)
где a - коэффициент загрузки; - интенсивность поступления требований в систему; v - интенсивность обслуживания одного требования одним обслуживающим устройством.
Из (1) и (2) получаем, что
Учитывая, что - интенсивность поступления требований в систему в единицу времени, произведение показывает количество требований, поступающих в систему обслуживания за среднее время обслуживания одного требования одним устройством.
Для СМО с ожиданием количество обслуживаемых устройств п должно быть строго больше коэффициента загрузки (требование установившегося или стационарного режима работы СМО) :
.
В противном случае число поступающих требований будет больше суммарной производительности всех обслуживающих устройств, и очередь будет неограниченно расти.
Для СМО с отказами и смешанного типа это условие может быть ослаблено, для эффективной работы этих типов СМО достаточно потребовать, чтобы минимальное количество обслуживаемых устройств n было не меньше коэффициента загрузки :
2.3 Процесс имитационного моделирования
Как уже было отмечено ранее, процесс последовательной разработки имитационной модели начинается с создания простой модели, которая затем постепенно усложняется в соответствии с требованиями, предъявляемыми решаемой проблемой. В процессе имитационного моделирования можно выделить следующие основные этапы:
- Формирование проблемы : описание исследуемой проблемы и определение целей исследования.
- Разработка модели: логико-математическое описание моделируемой системы в соответствии с формулировкой проблемы.
- Подготовка данных: идентификация, спецификация и сбор данных.
- Трансляция модели: перевод модели на язык, приемлемый для используемой ЭВМ.
- Верификация: установление правильности машинных программ.
- Валидация: оценка требуемой точности и соответствие имитационной модели реальной системе.
- Стратегическое и тактическое планирование: определение условий проведения машинного эксперимента с имитационной моделью.
- Экспериментирование: прогон имитационной модели на ЭВМ для получения требуемой информации.
- Анализ результатов: изучение результатов имитационного эксперимента для подготовки выводов и рекомендаций по решению проблемы.
- Реализация и документирование: реализация рекомендаций, полученных на основе имитации, составление документации по модели и ее использованию.
Рассмотрим основные этапы имитационного моделирования. Первой задачей имитационного исследования является точное определение проблемы и детальная формулировка целей исследования. Как правило, определение проблемы является непрерывным процессом , который обычно осуществляется в течении всего исследования. Оно пересматривается по мере более глубокого понимания исследуемой проблемы и возникновения новых ее аспектов.
Как только сформулировано начальное определение проблемы, начинается этап построения модели исследуемой системы. Модель включает статистическое и динамическое описание системы. В статистическом описании определяются элементы системы и их характеристики, а в динамическом- взаимодействие элементов системы, в результате которых происходит изменение ее состояния во времени.
Процесс формирования модели во многом является искусством. Разработчик модели должен понять структуру системы, выявить правила ее функционирования и суметь выделить в них самое существенное, исключив ненужные детали. Модель должна быть простой для понимания и в то же время достаточно сложной, чтобы реалистично отображать характерные черты реальной системы. Наиболее важными являются принимаемые разработчиком решения относительно того, верны ли принятые упрощения и допущения, какие элементы и взаимодействия между ними должны быть включены в модель. Уровень детализации модели зависит от целей ее создания. Необходимо рассматривать только те элементы, которые имеют существенное значение для решения исследуемой проблемы. Как на этапе формирования проблемы, так и на этапе моделирования необходимо тесное взаимодействие между разработчиком модели и ее пользователями. Кроме того, тесное взаимодействие на этапах формулирования проблемы и разработки модели создает у пользователя уверенность в правильности модели, поэтому помогает обеспечить успешную реализацию результатов имитационного исследования.
На этапе разработки модели определяются требования к входным данным. Некоторые из этих данных могут уже быть в распоряжении разработчика модели, в то время как для сбора других потребуется время и усилия. Обычно значение таких входных данных задаются на основе некоторых гипотез или предварительного анализа. В некоторых случаях точные значения одного (и более) входных параметров оказывают небольшое влияние на результаты прогонов модели. Чувствительность получаемых результатов к изменению входных данных может быть оценена путем проведения серии имитационных прогонов для различных значений входных параметров. Имитационная модель, следовательно, может использоваться для уменьшения затрат времени и средств на уточнение входных данных. После того как разработана модель и собраны начальные входные данные, следующей задачей является перевод модели в форму, доступную для компьютера.
На этапах верификации и валидации осуществляется оценка функционирования имитационной модели. На этапе верификации определяется, соответствует ли запрограммированная для ЭВМ модель замыслу разработчика. Это обычно осуществляется путем ручной проверки вычисления, а также может быть использован и ряд статистических методов.
Установление адекватности имитационной модели исследуемой системы осуществляется на этапе валидации. Валидация модели обычно выполняется на различных уровнях. Специальные методы валидации включают установление адекватности путем использования постоянных значений всех параметров имитационной модели или путем оценивания чувствительности выходов к изменению значений входных данных. В процессе валидации сравнение должно осуществляться на основе анализа как реальных, так и экспериментальных данных о функционировании системы.
Условия проведения машинных прогонов модели определяется на этапах стратегического и тактического планирования. Задача стратегического планирования заключается в разработке эффективного плана эксперимента, в результате которого выясняется взаимосвязь между управляемыми переменными, либо находится комбинация значений управляемых переменных, минимизация или максимизация имитационной модели. В тактическом планировании в отличии от стратегического решается вопрос о том, как в рамках плана эксперимента провести каждый имитационный прогон, чтобы получить наибольшее количество информации из выходных данных. Важное место в тактическом планировании занимают определение условий имитационных прогонов и методы снижения дисперсии среднего значения отклика модели.
Следующие этапы в процессе имитационного исследования- проведение машинного эксперимента и анализ результатов- включают прогон имитационной модели на ЭВМ и интерпретацию полученных выходных данных. Последним этапом имитационного исследования является реализация полученных решений и документирование имитационной модели и ее использование. Ни одни из имитационных проектов не должен считаться законченным до тех пор, пока их результаты не были использованы в процессе принятия решений. Успех реализации во многом зависит от того, насколько правильно разработчик модели выполнил все предыдущие этапы процессов имитационного исследования. Если разработчик и пользователь работали в тесном контакте и достигли взаимопонимания при разработке модели и ее исследовании, то результат проекта скорее всего будет успешно внедряться. Если же между ними не было тесной взаимосвязи, то, несмотря на элегантность и адекватность имитационного моделирования, сложно будет разработать эффективные рекомендации.
Вышеперечисленные этапы редко выполняются в строго заданной последовательности, начиная с определения проблемы и кончая документированием. В ходе имитационного моделирования могут быть сбои в прогонах модели, ошибочные допущения, от которых в дальнейшем приходится отказываться, переориентировки целей исследования, повторные оценки и перестройки модели. Такой процесс позволяет разработать имитационную модель, которая дает верную оценку альтернатив и облегчает процесс принятия решений.
3.Описание моделируемой системы
Схема процесса выполнения заданий на станке и поломок станка показана на
рис. 1. Задания поступают на станок в среднем 1 раз в час. Распределение вели-
чины интервала между ними экспоненциально. При нормальном режиме работы
задания выполняются в порядке их поступления. Время выполнения задания
нормально распределено с математическим ожиданием 0,5 ч и среднеквадратич-
ным отклонением 0,1. Перед выполнением задания производится наладка станка,
время которой распределено равномерно на интервале 0,2-0,5 ч. Задания, вы-
полненные на станке, направляются в другие отделы цеха и считаются покинув-
шими рассматриваемую систему. Станок время от времени ломается. Интервалы
между поломками распределены нормально с математическим ожиданием 20 ч и
среднеквадратичным отклонением 2 ч. При поломке выполняемое задание уда-
ляется со станка и помещается в начало очереди заданий к станку. Выполнение
задания возобновляется с того места, на котором оно было прервано. Когда ста-
нок ломается, начинается процесс устранения неисправности, который состоит
из трех фаз. Продолжительность каждой фазы распределена экспоненциально с
математическим ожиданием, равным 45 мин. Поскольку общая продолжитель-
ность устранения поломки является суммой независимых и одинаково опреде-
ленных случайных величин с одинаковыми параметрами, она имеет эрлангов-
ское распределение.
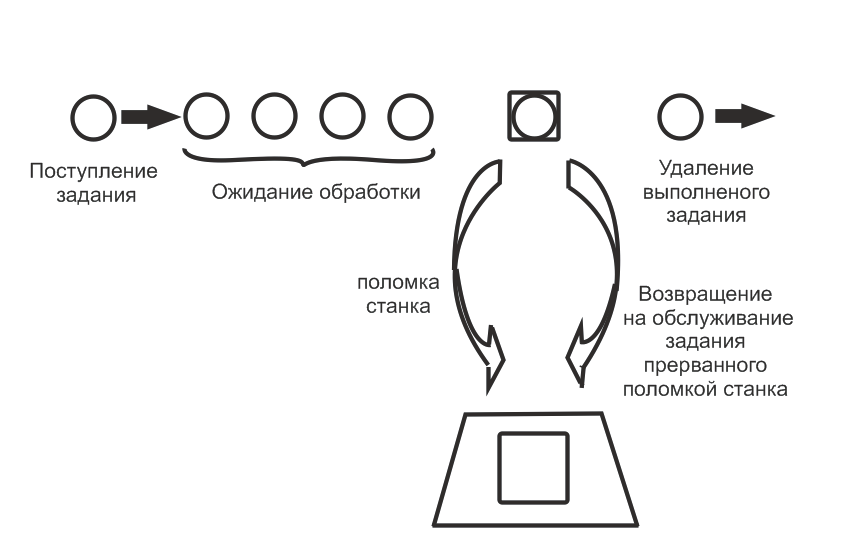
Рис 1. Схема работы станка с поломками
Работа станка анализируется в течение 500 ч для получения информации о за-
грузке станка и времени выполнения задания.
3.1Модельное время
В качестве единицы модельного времени примем одну минуту. К генерации многочисленных случайных величин, входящих в описание системы, будем подхо-
дить избирательно. Чтобы генераторы случайных чисел не работали со слишком
большими или слишком маленькими параметрами и вследствие этого не теряли
точность при численном интегрировании и решении уравнений, будем в одних
случаях задавать параметры распределений в минутах, а в других — в часах, ум-
ножая во втором случае результат на 60 и округляя до ближайшего целого числа,
а именно:
- интенсивность входного потока — 1 заявка в час;
- время обслуживания: среднее — 30 мин, отклонение — 6 мин;
- время наладки станка: среднее — 21 мин, отклонение — 9 мин;
- время безаварийной работы станка после ремонта: среднее — 20 ч, отклонение — 2 ч. Уточним, что в него не входит то время, когда станок не занят обслуживанием;
- время ремонта: средняя продолжительность фазы — 0,75 ч, отсюда параметрраспределения Эрланга равен 1,33.
3.2Используемые классы и объекты
Обобщим первоначальную задачу, предположив, что вместо одного станка у насесть несколько станков (многоканальный узел). Это обобщение необходимо длятого, чтобы выяснить в дальнейшем, как влияет количество (панков на производительность системы. Предположим, что каждый станок обслуживается своими
собственными наладчиком и ремонтником, так что ни одному из станков не при-
ходится ожидать ремонта, когда он ему потребуется. Очередь единственная, и за-
явка попадает на первый свободный станок. Если после поломки станка сущест-
вует хотя бы один свободный и готовый к обслуживанию станок, заявка сразу же
переходит к нему, и обслуживание считается непрерывным. Тогда сформулиро-
ванная задача есть частный случай, когда число каналов (станков) равно едини-
це. Система является открытой, число заявок — переменное. Для моделирования
системы необходимо описать класс Станок (Machine), представленный одним по-
стоянным объектом, и класс Заявка (Client), представленный переменным чис-
лом объектов, которые по ходу моделирования порождаются в системе и уда-
ляются из нее. Поведение заявок в системе полностью моделируется станком,
поэтому класс Clientсобственного метода run( ) не имеет. Отметим существен-
ные особенности системы:
- прерывание обслуживания заявки и возвращение ее на дообслуживание осуществляются с учетом полученного ранее обслуживания;
- усложненное расписание работы сервера (станка), необходимость учета наладок, поломок и ремонтов.
Упорядочим имеющиеся у нас сведения о работе станка. На рис. 2 приведена
диаграмма его состояний и возможные переходы. Каждый переход обозначен названием метода класса Machine, который этот переход обрабатывает.
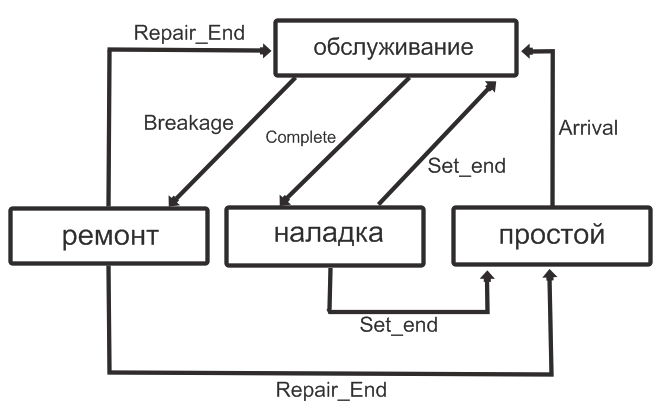
Рис. 2. Диаграмма состояний и переходов станка
Изменяемые поля данных класса Machineдолжны каким-то образом обеспечи-
вать информацию о текущем состоянии объекта и о том, сколько времени оста-
лось до перехода в то или иное состояние. Объект класса Clientпри возвраще-
нии в очередь должен наряду со временем пребывания в системе сохранять
информацию об оставшемся времени дообслуживания, а также — в целях сбора
статистики — изменять значение признака, свидетельствующего о том, что в его
обслуживании был перерыв. Таким образом, класс Clientимеет следующие поля
данных:
- уникальный идентификатор объекта, равный порядковому номеру поступившей заявки;
- текущее время пребывания в системе;
- оставшееся до окончания обслуживания время. Поле данных имеет смысл
только для заявок, вернувшихся в очередь, и только на время их повторногонахождения в ней. Для всех остальных заявок полагаем его равным -1; - признак прерывания (false— непрерывное обслуживание, true— обслуживание прерывалось). Заметим, что значение признака не переключается в единицу, если после поломки станка заявке сразу же удалось перейти на другойсвободный и готовый к обслуживанию станок.
Неизменяемые поля данных класса Machine:
- количество станков (1);
- интенсивность входного потока (1 заявка в час);
- среднее значение времени обслуживания (30 мин);
- среднеквадратичное отклонение времени обслуживания (6 мин);
- среднее значение времени наладки (21 мин);
- максимальное отклонение времени наладки от среднего (9 мин);
- среднее время безаварийной работы (20 ч);
- среднеквадратичное отклонение времени безаварийной работы (2 ч);
- интенсивность одного этапа ремонта (1,33 заявок в час);
- количество этапов ремонта (3);
Изменяемые поля данных класса Machine:
- очередь заявок на обслуживание (список указателей);
- массив указателей на обслуживаемые в текущий момент заявки;
- массив времен, остающихся до окончания обслуживания;
- массив времен, остающихся до окончания наладки;
- массив времен, остающихся до окончания безаварийной работы;
- массив времен, остающихся до окончания ремонта;
- время до прибытия следующей заявки из входного потока;
- текущая длина очереди (вычисляемое поле).
Отметим, что отличными от -1 в некоторых состояниях могут быть сразу два изменяемых поля данных станка — время до окончания обслуживания и время доокончания безаварийной работы.
3.3 События и методы
В системе с каждым из станков могут происходить следующие события:
- поломка станка (Breakage);
- завершение ремонта (Repalr_End);
- завершение наладки (Set_End);
- завершение обслуживания (Complete);
- прибытие новой заявки (Arrival).
Снова обратившись к рис. 2, отметим интересную особенность: между множествами переходов и событий существует связь «многие к одному» — одному пе-
реходу соответствует одно событие, но одному событию могут соответствовать
несколько переходов. Перечисленные пять методов программируются по текстовому описанию системы. Остановимся на некоторых нюансах:
- декремент оставшегося времени безаварийной работы следует производитьтолько в том случае, если станок занят обслуживанием. Разыгрывать это времяследует при обработке события «Завершение ремонта» (в методе RepairEndO);
- при выборке заявки из очереди время ее обслуживания следует разыграть,если это первый сеанс обслуживания, и взять из поля данных заявки — в противном случае (если это поле отлично от -1);
- необходимо предусмотреть возможность наложения событий. В частности,как поступить, если время безаварийной работы и время обслуживания истекут одновременно? С точки зрения логики, станок не может сломаться послетого, как он закончил работать, поломка должна произойти раньше. Поэтомув методе run() (листинг 13.2) мы сначала фиксируем события поломок (тогдазаявка уходит в очередь с временем дообслуживания, равным единице), а затем уже для остальных станков производим декременты остаточного временипребывания в текущем состоянии.
4. Программная реализация на С++
Присоздания имитационной модели очереди с разнотипными заявками (работа порта) был выбран язык программирования C++ и написана программа на этом языке, позволяющая в полной мере отразить функционирование системы.
Листинг программы файл 10.h. Описание классов
#include
#include
#include
#define _USE_MATH_DEFINES
#include
using namespace std;
#include "List.h"
#include "erlang.h"
#include "normal.h"
#include "random.h"
FILE *que; //файл для сбора статистики о длине очереди
FILE *sojourn; //файл для сбора статистики о времени пребывания
//в системе
int entered=0; //счетчик поступлений
int completed=0; //счетчик обслуженных заявок
int completed1=0; //счетчик заявок, не возвращавшихся в очередь
int completed2=0; //счетчик заявок, возвращавшихся в очередь
float ro_ave=0; //переменная для подсчета коэффициента загрузки
//станков
float que_ave=0; //переменная для подсчета средней длины очереди
float soj_ave=0; //переменная для подсчета среднего времени пребывания
//в системе
long int total; //счетчик модельного времени
class Client
{
int id; //уникальный идентификатор
int time; //текущее время пребывания в системе
int to_serve; //остаточное время обслуживания
int interrupt; //признак возврата в очередь
protected:
static int counter; //счетчикзаявок
public:
friend class Machine;
Client();
};
int Client::counter=0; //инициализация статического поля данных вне класса
Client::Client() //конструктор
{
counter++;
id=counter;
time=0;
interrupt=0;
to_serve=-1;
}
class Machine
{
const static int volume=1;
const static int input_rate=1;
const static int serve_median=30;
const static int serve_offset=6;
const static int set_median=21;
const static int set_offset=9;
const static int break_median=20;
const static int break_offset=2;
const static int repair_rate=133;
const static int repair_stages=3;
ListNode
Client **serving; //обслуживаемыезаявки
int *to_serve; //текущее время до окончания обслуживания
int *to_setting; //текущее время до окончания наладки
int *to_break; //оставшееся время безаварийной работы
int *to_repair; //текущее время до окончания ремонта
int to_arrival; //время до прибытия новой заявки
int q_length; //текущая длина очереди
public:
Machine();
~Machine();
void Arrival();
void Complete(int i);
void Breakage(int i);
void Repair_End(int i);
void Set_End(int i);
int Busy();
int FirstAvail();
void run();
};
//Поиск доступного станка. Доступным считается станок, находящийся
//всостояниипростоя
int Machine::FirstAvail()
{
for(int i=0;i if ((serving[i]==NULL)&&(to_repair[i]==-1)&&(to_setting[i]==-1)) return(i); return(-1); } int Machine::Busy() //подсчетколичествазанятыхстанков { int k=0; for(int i=0;i if (serving[i]!=NULL) k++; return(k); } //Конструктор. Исходное состояние - простой Machine::Machine() { queue=NULL; //Выделение памяти под массивы serving=new Client *[volume]; to_serve=new int[volume]; to_setting=new int[volume]; to_break= new int[volume]; to_repair= new int[volume]; to_arrival=(int)(get_exp(input_rate)*60); if (to_arrival==0) to_arrival=1; //Инициализация массивов for(int i=0;i { to_serve[i]=-1; to_setting[i]=-1; to_break[i]=(int)(get_normal(break_median, break_offset, 0.001)*60); if (to_break[i]==0) to_break[i]=1; to_repair[i]=-1; serving[i]=NULL; } q_length=0; } Machine::~Machine() { for(int i=0;i if (serving[i]!=NULL) delete serving[i]; delete [] serving; delete[] to_serve; delete[] to_setting; delete[] to_break; delete[] to_repair; while(queue) queue=ListDelete } void Machine::Arrival() //поступление новой заявки { int k; Client *ptr=NULL; ListNode //Разыгрываем новую длительность интервала между поступлениями to_arrival=(int)(get_exp(input_rate)*60); if (to_arrival==0) to_arrival=1; entered++; //инкремент счетчика поступлений ptr=new Client(); //создание новой заявки k=FirstAvail(); if (k==-1) //поставить поступившую заявку на обслуживание //невозможно { ptr1=new ListNode if (queue==NULL) queue=ptr1; else ListAdd q_length++; } else //новую заявку сразу ставим на обслуживание //на k-йстанок { serving[k]=ptr; to_serve[k]=(int)get_normal(serve_median, serve_offset, 0.001); if (to_serve[k]==0) to_serve[k]=1; } return; } void Machine::Complete(int i) //завершениеобслуживанияна i-мстанке { completed++; to_serve[i]=-1; if (serving[i]->interrupt==0) completed1++; else completed2++; //записьстатистики fprintf(sojourn, "%.3fn", ((float)serving[i]->time)/60); soj_ave=soj_ave*(1-1.0/completed)+(float)(serving[i]->time)/completed; delete serving[i]; serving[i]=NULL; //Станокпереходитвсостояниеналадки to_setting[i]=get_uniform(set_median, set_offset); return; } void Machine::Breakage(int i) //поломка i-гостанка { int k; k=FirstAvail(); if (k==-1) //свободного станка нет, заявка //переходит в очередь { serving[i]->to_serve=to_serve[i]; //сохраняем время дообслуживания //в поле данных заявки serving[i]->interrupt=1; //Заявка "от станка" заносится в голову очереди queue=new ListNode q_length++; } else //свободный станок найден { serving[k]=serving[i]; to_serve[k]=to_serve[i]; } //Вышедший из строя станок переходит в состояние ремонта serving[i]=NULL; to_serve[i]=-1; to_repair[i]=(int)(get_erlang((float)repair_rate/100, repair_stages,0.001)*60); if (to_repair[i]==0) to_repair[i]=1; to_break[i]=-1; return; } void Machine::Repair_End(int i) //завершениеремонта i-гостанка { to_repair[i]=-1; if (q_length==0) return; //очередь пуста, ставить на обслуживание //нечего //Очередь не пуста, заявку из головы очереди ставим на отремонтированный //станок serving[i]=queue->Data(); if (serving[i]->to_serve>0) //эта заявка ранее уже обслуживалась { to_serve[i]=serving[i]->to_serve; serving[i]->to_serve=-1; } else to_serve[i]=(int)get_normal(serve_median, serve_offset, 0.001); if (to_serve[i]==0) to_serve[i]=1; queue=queue->Next(); //сдвигочереди q_length--; //Разыгрываемновоевремябезаварийнойработы to_break[i]=(int)(get_normal(break_median, break_offset, 0.001)*60); if (to_break[i]==0) to_break[i]=1; } void Machine::Set_End(int i) //завершениеналадки i-гостанка //Код этого метода такой же, как и код предыдущего, только время //безаварийной работы не разыгрывается { to_setting[i]=-1; if (q_length==0) return; serving[i]=queue->Data(); if (serving[i]->to_serve>0) { to_serve[i]=serving[i]->to_serve; serving[i]-> to_serve=-1; } else to_serve[i]=(int)get_normal(serve_median, serve_offset,0.001); if (to_serve[i]==0) to_serve[i]==1; q_length--; queue=queue->Next(); } void Machine::run() //диспетчер { int i; ListNode //Фиксируемсломавшиесястанки for(i=0;i { if (serving[i]!=NULL) to_break[i]--; if (to_break[i]==0) Breakage(i); } if (to_arrival>0) to_arrival--; if (to_arrival==0) Arrival(); //Осуществляем, если нужно, переходы станков в новые состояния for(i=0;i { if (serving[i]!=NULL) to_serve[i]--; if (to_serve[i]==0) Complete(i); if (to_setting[i]>0) to_setting[i]--; if (to_setting[i]==0) Set_End(i); if (to_repair[i]>0) to_repair[i]--; if (to_repair[i]==0) Repair_End(i); } //Инкремент времени пребывания у всех заявок, находящихся в системе //...вочереди ptr=queue; while(ptr) { ptr->Data()->time++; ptr=ptr->Next(); } //...иобслуживающихся for(i=0;i if (serving[i]!=NULL) serving[i]->time++; //Запись статистики fprintf(que, "%dn", q_length); que_ave=que_ave*(1-1.0/(total+1))+((float)q_length)/(total+1); ro_ave=ro_ave*(1-1.0/(total+1))+((float)Busy())/(volume*(total+1)); } Листинг программы файл List.h template //к класам и функциям //c парметризированным типом classListNode { private: ListNode Type *data; //указатель на данные хранящиеся в элементе списка public: ListNode(Type *d, ListNode ~ListNode(); //деструктор Type *Data(); //метод для чтения данных ListNode //на следующий элемент voidPutNext(ListNode //на следующий элемент voidPrint(); //печать содержимого элемента списка }; template ListNode } template ListNode delete data; } template Type *ListNode return data; } template ListNode return next; } template void ListNode next=n; } template void ListNode data->Print(); //предпологаетсяналичиеметода Print() длякласса //имя которого будет подставленно в пользовательском коде } //Описание класса-шаблона завершено, далее идут функции-шаблона, работающие //не с отдельным элементом, а со всеми списком template void ListAdd(ListNode //добавление нового элемента li в хвост списка с головой head ListNode //ищем внешний хвост списка for (v=head; v!=NULL; v=v->Next()) old=v; old->PutNext(li); //добавляем в след за найденым хвостом новый элемент списка } template ListNode //удаление элемента li из списка с голоыой head //функция возвращает указатель на голову нового списка //int j; ListNode if (li==head){ //удаляемый элемент может быть головой списка //в этом случае голова у списка меняется o1=head->Next(); delete li; return o1; } //Удаляемый элемент не являеться головой списка. Головаостаетьсяпрежняя for (ListNode //поиск элемента предшедствующего удаляемому old=v; o1=li->Next(); old->PutNext(o1); //предшествующий элеиент теперь «видит» элемент стоящий в списке вслед //за удаленным delete li; returnhead; } //печать всех элементов списка с головой head template void ListPrint(ListNode for (ListNode v->Print(); //подсчет количества элементов в списке с головой head } template int ListCount(ListNode int i; i=0; for (ListNode v->Print(); i++; } return i; } Листинг программы файл random.h #include #include #include float get_exp(float mu) //генераторслучайныхчисел, распределенных //экспоненциально { int r_num; float root, right; r_num=rand(); /*получение случайного целого /числа*/ right=((float)r_num)/(RAND_MAX+1); /*проекция на интервал (0;1)*/ root=-log(1-right)/mu; /*вычисление значения обратной /функции*/ return(root); } int get_uniform(int a, int b) { //Генерация равномерно распределенной величины a+b int x, y; x=rand()%(b+1); y=rand()%2; if (y==0) return(a-x); return(a+x); } float get_triangle(float A, float B, float C) { int r_num; float root, right; r_num=rand(); //получение случайного целого //числа right=((float)r_num)/(RAND_MAX+1); //проекция на интервал (0;1). //Константа RAND_MAX=32767 (215-1) определена в cstdlib if (right<(C-A)/(B-A)) root=A+sqrt(right*(B-A)*(C-A)); else root=B-sqrt((1-right)*(B-A)*(B-C)); return(root); } float get_pareto(float A, float B) { int r_num; float root, right; r_num=rand(); /*получение случайного целого числа*/ right=(float)r_num/RAND_MAX+1; /*проекция на интервал (0;1)*/ root=A/(pow(1-right, (float)1.0/B)); /*вычисление значения обратной функции*/ return(root); } Листинг программы файл normal.h #include #include #include float get_normal(float mean, float disp, float eps); float simpson(float A, float B, float mean, float disp); float equ(float bottom_bound, float top_bound, float mean, float disp, float almost_all, float eps, float right); float function(float mean, float disp, float x); float get_normal(float mean, float disp, float eps) { int r_num; float root, bottom_bound, top_bound, almost_all, right; /*вычисление конечных аппроксимаций пределов интегрирования в соответствии с заданной точностью*/ bottom_bound=mean-disp*sqrt(-log(2*M_PI*eps*eps*disp*disp)); top_bound=mean+disp*sqrt(-log(2*M_PI*eps*eps*disp*disp)); /*вычисление интеграла в этих пределах*/ almost_all=simpson(bottom_bound, top_bound, mean, disp); r_num=rand(); right=(float)r_num/32768; root=equ(bottom_bound, top_bound, mean, disp, almost_all, eps, right); return(root); } float simpson(float A, float B, float mean, float disp) { float k1, k2, k3, s, x, h1, h; /*шаг интегрирования принимается равным 0.01. В "товарных" реализациях метода применяется процедура автоматического выбора шага с помощью апостериорных оценок*/ h=0.01; s=0; h1=h/1.5; k1=function(mean, disp, A); for(x=A; (x { k2=function(mean, disp, x+h/2); k3=function(mean, disp, x+h); s=s+k1+4*k2+k3; k1=k3; } s=s*h/6; return(s); } float function(float mean, float disp, float x) { float result; result=(1.0/(disp*sqrt(2*M_PI)))*exp(-0.5*((x-mean)/disp)*((x-mean)/disp)); return(result); } float equ(float bottom_bound, float top_bound, float mean, float disp, float almost_all, float eps, float right) { float edge1, edge2, middle, cover, value; edge1=bottom_bound; edge2=top_bound; if (right>almost_all) return(top_bound); else; if (right<(1-almost_all)) return(bottom_bound); else; cover=0; /*введена для повышения производительности. В новой точке вычисление интеграла производится не от bottom_bound, а от edge1, в то время как значение интеграла от bottom_bound до edge1 уже накоплено в cover*/ while((edge2-edge1)>eps) { middle=(edge1+edge2)/2; value=simpson(edge1, middle, mean, disp); if ( (cover+value-right)<0 ) { edge1=middle; cover=cover+value; } else edge2=middle; } return((edge1+edge2)/2); } Листинг программы файл erlang.h #include #include #include float get_erlang(float mu, int k, float eps); float equ(float mu, float right, int k, float eps); float function(float mu, int k, float x); float get_erlang(float mu, int k, float eps) { int r_num; float root, right; r_num=rand(); right=(float)r_num/32768; root=equ(mu, right, k, eps); return(root); } /*вычисление функции F(t) - левой части уравнения - в заданной точке t*/ float function(float mu, int k, float t) { float prod, s; int i; prod=1; s=1; for(i=1;i { prod=prod*mu*t/i; s+=prod; } s=s*exp(-mu*t); return(1-s); } float equ(float mu, float right, int k, float eps) { float edge1, edge2, middle, value; /*инициализация отрезка, на котором ищется корень. Правая граница - среднее плюс десятикратное среднеквадратичное отклонение*/ edge1=0.0; edge2=(float)k/mu+10*sqrt((float)k)/mu; /*если длина начального отрезка все-таки мала - удваиваем его, пока корень уравнения не окажется внутри отрезка*/ while(function(mu, k, edge2) /*итерируем, пока не достигнута заданная точность*/ while((edge2-edge1)>eps) { middle=(edge1+edge2)/2; value=function(mu, k, middle); /*вычисляем значение левой части в середине текущего интервала локализации корня*/ /*корень лежит в правой половине текущего интервала*/ if ( (value-right)<0 ) edge1=middle; /*корень лежит в левой половине текущего интервала*/ else edge2=middle; } return((edge1+edge2)/2); } Листингпрограммыфункция main() #include "stdafx.h" #include "iostream" #include "10.h" int main() { int i,j; int N = 0; setlocale(LC_ALL, "Russian"); cout << "Введите время моделирования = "; cin >> N; int s = 1; cout << "Введите количество станков = "; cin >> s; Machine *m = new Machine[s]; que=fopen("que", "wt"); sojourn=fopen("sojourn", "wt"); srand((unsigned)time(0)); for(total=0L;total for(j=0;j m[j].run(); fclose(sojourn); fclose(que); cout << "Всегопоступилозаявок " << entered << endl; cout << "Всего завершило обслуживание " << completed << " заявок" << endl; cout << "Долязаявок, прервавшихобслуживание " << ((float)completed1)/completed << endl; cout << "Долязаявок, прервавшихобслуживание " << ((float)completed2)/completed << endl; cout << "Средняя длина очереди " << que_ave << endl; cout << "Среднее время пребывания " << soj_ave/60 << endl; cout << "Коэффициент загрузки станков " << ro_ave << endl; _gettch(); } 5.Анализ результатов работы программы Моделирование системы при заданных условиях (1 станок, 500 ч) дало следу- Рис. 3. Снимок работы программы На рис. 4 и 5 приведены примеры реализаций случайной величины и слу- Рис. 4. Пример реализации случайной величины — среднего времени пребываниязаявки в системе Мы видим, что при среднем времени обслуживания 30 мин заявка проводит Таким образом, добавление второго станка полностью решает проблемы — среднее время пребывания заявки в системе становится практически равным среднему времени обслуживания. Поэтому добавлять третий станок не имеет смысла. Рис. 5. Пример реализации случайной функции — длины очереди 6. Заключение Сам напиши Список использованной литературы
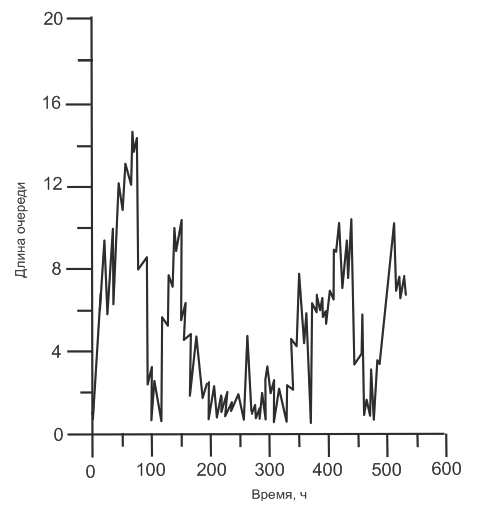
ющие результаты: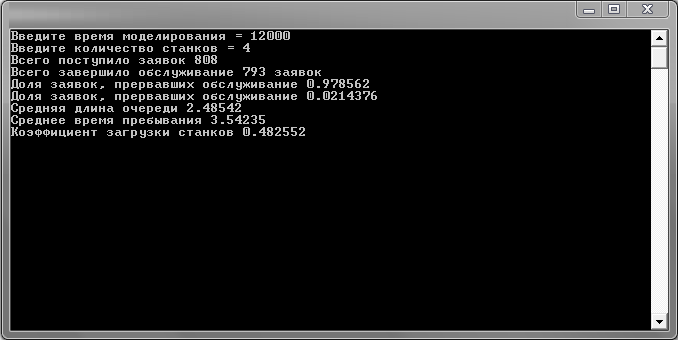
чайной функции — соответственно, времени пребывания заявок в системе и длины
очереди к станку. Периодические всплески на этих графиках связаны с поломка-
ми станка. В самом деле, если обратиться к рис. 5 и провести горизонтальную
линию приблизительно на уровне шести (напомним, что среднее значение — 3.65),
то зафиксируем приблизительно 11-12 всплесков, доходящих до этого уровня.
Количество поломок на протяжении 500 часов также устойчиво показывает при
имитационных экспериментах значение 11-12.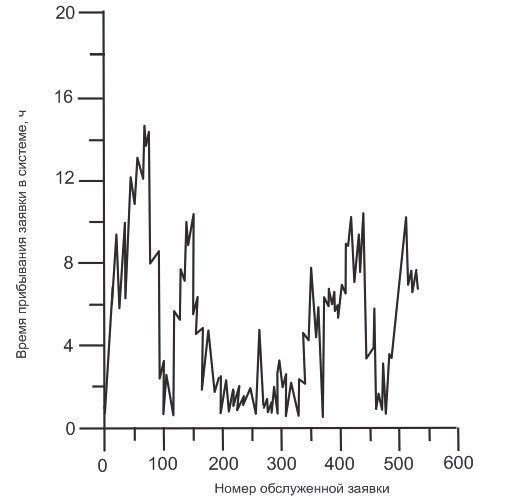
в системе в среднем довольно много времени — 4 ч. Насколько улучшится ситуа-
ция, если добавить второй станок? Вот результаты: