Программирование на языке Турбо Паскаль
| Загрузить архив: | |
| Файл: ref-12171.zip (61kb [zip], Скачиваний: 74) скачать |
Лекция 1. Структура программы на языке Turbo Pascal
Приведём простейший пример программы, единственная цель которой – вывести на экран какое-нибудь приветствие:
program Hello;
begin
writeln('Hello, world!');
readln;
end.
Первая строка ничего не делает, она просто содержит название программы. Затем, после слова begin начинаются собственно действия. В нашей программе их два: первое – это вывод строчки «Hello, world»на экран, а второе – ожидание нажатия клавиши «Enter», оно нужно для того, чтобы можно было увидеть результат программы, а затем уже нажать «Enter» и вернуться в Турбо-Паскаль. И, наконец, слово end с точкой в последней строке говорит о том, что программа закончилась. Действия, из которых состоит программа, называются операторами, они отделяются друг от друга точкой с запятой.
А теперь приведём пример, в котором программа уже не «глухая», то есть может запрашивать какие-либо данные у пользователя. Пусть требуется спросить у пользователя два числа, после этого вывести на экран их произведение:
program AxB;
var a,b: integer;
begin
writeln('Введите a и b');
readln(a,b);
writeln('Произведение равно ',a*b);
readln;
end;
В этой программе перед словом begin появляется новая строчка, начинающаяся словом var. В ней мы указываем, что программе понадобится две переменные (a и b), в которых можно хранить целые числа (слово integer).
О том, что делает первый оператор, нам известно: он выводит на экран строчку 'Введите a и b'. При выполнении второго оператора программа будет ждать, пока пользователь не введет число с клавиатуры и не нажмёт «Enter»; это число программа запишет в переменную a, затем тоже самое делается для переменной b. Третьим оператором выводим на экран сначала надпись «Произведение равно », а потом значение выражения a×b («*» – знак умножения). Четвёртый оператор пояснений не требует.
А теперьрассмотрим структуру программы в общем виде. Любая программа на Турбо-Паскале состоит из трех блоков: блока объявлений, блока описания процедур и функций и блока основной программы. Ниже эти блоки расписаны более подробно.
Блок объявлений:
program ... (название программы)
uses ... (используемые программой внешние модули)
const ... (объявления констант)
type ... (объявления типов)
var ...(объявления переменных)
Блок описания процедур и функций:
procedure (function)
begin
...
end;
...
Блок основной программы:
begin
... (операторы основной программы) ...
end;
Рассмотрим наиболее важные части вышеописанных блоков. Под заголовком программы понимается имя, помогающее определить её назначение. Имя, или идентификатор, строится по следующим правилам: оно может начинаться с большой или малой буквы латинского алфавита или знака «_», далее могут следовать буквы, цифры или знак «_»; внутри идентификатора не может стоять пробел. После имени программы следует поставить «;», этот знак служит в Паскале для разделения последовательных инструкций. Заметим, что имя программы может не совпадать с именем соответствующего файла на диске.
После слова const помещаются описания постоянных, которые будут использованы в программе, например:
const Zero = 0;
pi = 3.1415926;
my_const = -1.5;
Hello = 'Привет !';
За словом var следуют объявления переменных, которые понадобятся нам при написании программы. Переменные Паскаля могут хранить данныеразличной природы: числа, строки текста, отдельные символы и т. п. Ниже приводится часть типов переменных, которые можно применять.
|
Название типа |
Возможные значения |
Примеры значений |
|
integer |
целые: -32768 ... 32767 |
12, -10000 |
|
real |
действительные (по модулю): 2,9x10-39... 1,7x1038 |
-9.81, 6.02e-23 |
|
string[n] |
строка до n символов длиной, если [n] не указано, то до 255 |
‘abcde’, ‘привет’ |
|
char |
одиночный символ |
‘F’, ‘!’, ’_’,’ю’ |
Объявления переменных записываются в следующей форме: var <переменная> : <тип>;
Если описываются несколько переменных одного типа, то достаточно записать их имена через запятую, а после двоеточия поставить общий тип.
Примеры объявления:
var Number: integer;
d,l: real;
Name: string[20];
Line: string;
Key1,Key2: char;
Блок основной программы. Здесь, между словами begin и end. располагаются команды (точнее, операторы), которые будут выполняться один за другим при запуске программы. Рассмотрим простейшие типы операторов на следующем примере:
program First;
const a2 = 3;
a1 = -2;
a0 = 5;
var x,f: real;
begin
write(‘Введите значение х ’);
readln(x);
f:=a2*x*x+a1*x+a0;
writeln(‘Значение квадратного трехчлена: ’,f);
end.
Первая строка исполняемой (основной) части программы выводит на экран надпись «Введите значение х », для этого используется процедура write написанная разработчиками Турбо Паскаля, то есть набор команд, невидимый для нас, но существующий реально в недрах системы Турбо Паскаль. В качестве параметра этой процедуры используется наша строчка. Параметры всегда записываются в круглых скобках, апострофы означают, что параметр имеет строковый тип. Итак, в первой строке мы видим так называемый оператор вызова процедуры. Каждый оператор отделяется от следующего знаком «;». Во второй строке вызывается процедура ввода readln(x), которая ждет, пока пользователь наберет значение x с клавиатуры и нажмет клавишу «Enter», а затем переводит курсор на следующую строку (ln ó Line – строка). В третьей строке вычисляется значение трехчлена и записывается в переменную f; этот оператор называется оператором присваивания, и обозначается символом ":=". В последней строке на экран выводится строка «Значение квадратного трехчлена: » и значение переменной f. Несложно заметить, что здесь процедуре writeln передается уже не один, а два параметра, причем они могут иметь разные типы. Вообще, процедуры ввода и вывода (т.е. write, writeln, read, readln)могут иметь любое число параметров различных типов, параметрами могут являться переменные, литералы (т.е. непосредственно записанные числа, строки; в нашем примере дважды были использованы строковые литералы), а также выражения. Используя выражение при выводе, можно заменить две последние строчки нашей программы одной:
writeln('Значение квадратного трехчлена: ', a2*x*x+a1*x+a0);
В арифметических выражениях на Паскале используются следующие знаки для обозначения операций: +, -, *, /. Для определения порядка действий используются круглые скобки согласно общепризнанным математическим правилам.
Замечание об именах. Для обозначения переменных запрещается использование ряда слов, называемых зарезервированными, они играют в языке особую роль. Нам уже встречался ряд зарезервированных слов: program, begin, end, string, const, var, и т.п.
Лекция 2. Процедуры ввода-вывода. Некоторые встроенные функции Турбо-Паскаля.
1. Процедуры ввода-вывода. Почти каждая программа должна общаться с пользователем, то есть выводить результаты своей работы на экран и запрашивать у пользователя информацию с клавиатуры. Для того чтобы это стало возможным, в Турбо-Паскале имеются специальные процедуры (то есть небольшие вспомогательные программы), называются он процедурами ввода-вывода. Для того чтобы заставить процедуруработать в нашей программе, нужно написать её имя, за которым в скобках, через запятую перечислить параметры, которые мы хотим ей передать. Для процедуры вывода информации на экран параметрами могут служить числа или текстовые сообщения, которые должна печатать наша программа на экран. Опишем назначение этих процедур.
· write(p1,p2,... pn);– выводит на экран значения выражений p1,p2,... pn, количество которых (n) неограничено. Выражения могут быть числовые, строковые, символьные и логические. Под выражением будем понимать совокупность некоторых действий, применённых к переменным, константам или литералам, например: арифметические действия и математические функции для чисел, функции для обработки строк и отдельных символов, логические выражения и т.п. Возможен форматный вывод, т.е. явное указание того, сколько выделять позиций на экране для вывода значения. Пример для вещественных типов: write(r+s:10:5); – вывести значение выражения r+s с выделением для этого 10 позиций, из них 5 – после запятой. Для других типов все несколько проще: write(p:10); – вывести значение выражения p, выделив под это 10 позиций. Вывод на экран в любом случае производится по правому краю выделенного поля.
· writeln(p1,p2,... pn); –аналогично write,выводит значения p1,p2,... pn, после чего переводит курсор на новую строку. Смысл параметров – тот же, замечания о форматном выводе остаются в силе. Существует вариант writeln; (без параметров), что означает лишь перевод курсора на начало новой строки.
· readln(v1,v2,...vn); –ввод с клавиатуры значений переменных v1,...vn. Переменные могут иметь строковый, символьный или числовой тип. При вводе следует разделять значения пробелами, символами табуляции или перевода строки (т.е., нажимая Enter).
· read(v1,v2,...vn); – по назначению сходно с readln; отличие состоит в том, что символ перевода строки (Enter), нажатый при завершении ввода, не «проглатывается», а ждет следующего оператора ввода. Если им окажется оператор ввода строковой переменной или просто readln; то строковой переменной будет присвоено значение пустой строки, а readln без параметров не станет ждать, пока пользователь нажмет Enter, а среагирует на уже введенный.
Пример. Программа просит пользователя ввести с клавиатуры два целых числа и печатает на экране их сумму:
program PrintSum;
var a,b: integer;
begin
write('Введите два числа:');
readln(a,b);
writeln('Сумма a и b равна ',a+b);
readln;
end.
2. Функции числовых параметров.
|
Название |
Значение |
|
abs(x) |
модуль x |
|
cos(x) |
косинусx |
|
frac(x) |
дробная часть x |
|
int(x) |
целая часть x (т.е. ближайшее целое, не превосходящее x) |
|
pi |
число p |
|
round(x) |
x, округлённое до целого |
|
sin(x) |
синус x |
|
sqr(x) |
квадрат x |
|
sqrt(x) |
квадратный корень из x |
|
trunc(x) |
число, полученное из x отбрасыванием дробной части |
Лекция 3. Операторы условного выполнения.
1. Оператор if.
Иногда требуется, чтобы часть программы выполнялась не всегда, а лишь при выполнении некоторого условия (а при невыполнении этого условия выполнялась другая часть программы). В этом случае пользуются оператором условного выполнения, который записывается в следующем виде:
if <условие>then <оператор1>else <оператор2>;
Под оператором понимается либо одиночный оператор (например, присваивания, вызова процедуры), либо т.н. составной оператор, состоящий из нескольких простых операторов, помещённых между словами begin и end. Важно заметить, что перед else не ставится точка с запятой.Часть else может и отсутствовать.
Пример 1: пусть требуется найти число m=max(a,b). Этой задаче соответствует следующий фрагмент программы на Паскале:
if a>b then m:=a else m:=b;
Пример 2: (без else) пусть дано целое число i. Требуется оставить его без изменения, если оно делится на 2, и вычесть из него 1, если это не так.
var i: integer;
.......
if i mod 2 = 1 then i:=i-1;{else - ничего не делать}
Примечание: в примере использована операция нахождения остатка от деления (mod), для нахождения неполного частного в Турбо-Паскале используется div.
Пример 3: (с использованием составного оператора). Пусть даны две переменные типа real. Требуется поменять местамизначения этих переменных, если a1>a2.
var a1,a2,buf :real;
.........
if a1>a2 then begin
buf:=a1;
a1:=a2;
a2:=buf;
end;
Следующий пример использует вложенные операторы if.
Пример 4: Поиск корней квадратного уравнения.
program SqEquation;
var a,b,c,d: real;
begin
writeln;
write('Введите коэффициенты a,b,c квадратного уравнения : ');
readln(a,b,c);
d:=sqr(b)-4*a*c;
if d>=0 then
if d=0 then writeln('Единственный корень: x=',-b/(2*a):8:3)
else writeln('Два корня : x1=',(-b+sqrt(d))/(2*a):8:3,
', x2=',(-b-sqrt(d))/(2*a):8:3)
else {d<0} writeln('Корней нет');
readln;
end.
Чтобы не запутаться в структуре этой программы, следует помнить такое правило: else всегда относится к последнему оператору if. Если же в программе требуется, чтобы else относилось к одному из предыдущих if,то придется воспользоваться составным оператором:
Пример 5:пользователь вводит натуральное число, задача программы — поставить слово «ученик» в нужную форму в сочетании с числительным (например: 1 ученик, 3 ученика, 9 учеников и т.п.)
begin
write('Число учеников (1..20) --> '); readln(n);
write(n,' ученик');
if n<5 then begin
if n>1 then writeln('а');
end
else
writeln('ов');
readln;
end.
В этом примере пришлось использовать составной оператор (begin ... end;) для того чтобы часть else относилась не к оператору if n>1, а к if n<5.
2. Оператор выбора (case)
Кроме оператора условного выполнения и циклов в Турбо Паскале имеется ещё одна управляющая конструкция, одно из названий которой — оператор выбора. На самом деле это усложнённый оператор if, он позволяет программе выполняться не двумя способами, в зависимости от выполнения условия, а несколькими, в зависимости от значения некоторого выражения. В общем виде этот оператор выглядит так:
caseВыражение of
Вариант1: Оператор1;
Вариант2: Оператор2;
...
ВариантN: ОператорN;
[else ОператорN1;]
end;
(Пояснение: квадратные скобки означают то, что часть else может отсутствовать).
Выражение в простейших случаях может быть целочисленным или символьным. В качестве вариантов можно применять:
1. case. Константное выражение отличается от обычного тем, что не содержит переменных и вызовов функций, тем самым оно может быть вычислено на этапе компиляции программы, а не во время выполнения.
2. 'a'..'z'.
3.
Выполняется оператор case следующим образом: вычисляется выражение после слова case и по порядку проверяется, подходит полученное значение под какой-либо вариант, или нет. Если подходит, то выполняется соответствующий этому варианту оператор, иначе — есть два варианта. Если в операторе case записана часть else, то выполняется оператор после else, если же этой части нет, то не происходит вообще ничего.
Рассмотрим пример. Пусть пользователь вводит целое число от 1 до 10, программа должна приписать к нему слово «ученик» с необходимым окончанием (нулевое, «а» или «ов»).
program SchoolChildren;
var n: integer;
begin
write('Число учеников --> '); readln(n);
write(n,' ученик');
case n of
2..4:write('а');
5..10: write('ов');
end;
readln;
end.
Можно также усовершенствовать программу для произвольного натурального n:
write(n,' ученик');
case n mod 100 of
11..19: write('ов');
else case n mod 10 of
2..4: write('а');
0,5..9: write('ов');
end;
end;
Лекция 4. Операторы циклов в Паскале
В реальных задачах часто требуется выполнять одни и те же операторы несколько раз. Возможны различные варианты: выполнять фрагмент программы фиксированное число раз, выполнять, пока некоторое условие является истинным, и т. п. В связи с наличием вариантов в Паскале существует 3 типа циклов.
1. Цикл с постусловием (Repeat)
На Паскале записывается следующим образом: repeat <оператор> until <условие>. (По-русски: повторять что-то пока_не_выполнилось условие). Под обозначением <оператор> здесь понимается либо одиночный, либо последовательность операторов, разделённых точкой с запятой. Цикл работает следующим образом: выполняется оператор, затем проверяется условие, если оно пока еще не выполнилось, то оператор выполняется вновь, затем проверяется условие, и т. д. Когда условие, наконец, станет истинным выполнение оператора, расположенного внутри цикла, прекратится, и далее будет выполняться следующий за циклом оператор. Под условием, вообще говоря, понимается выражение логического типа.
Пример (подсчет суммы натуральных чисел от 1 до 100):
var i,sum: integer;
begin
sum:=0; i:=0;
repeat
i:=i+1;
sum:=sum+i;
until i=100;
writeln('Сумма равна: ',sum);
readln;
end.
Важно заметить, что операторы стоящие внутри цикла repeat(иначе – в теле цикла) выполняются хотя бы один раз (только после этого проверяется условие выхода).
2. Цикл с предусловием (While)
Этот цикл записывается так: while <условие> do <оператор>. (Пока условие истинно, выполнять оператор). Суть в следующем: пока условие истинно, выполняется оператор (в этом случае оператор может не выполниться ни разу, т.к. условие проверяется до выполнения). Под оператором здесь понимается либо простой, либо составной оператор (т.е. несколько операторов, заключёных в begin ... end).
Рассмотрим тот же пример, выполненный с помощью while:
var i,sum: integer;
begin
sum:=0; i:=0;
while i<100 do begin
i:=i+1;
sum:=sum+i;
end;
writeln('Сумма равна: ',sum);
readln;
end.
3. Цикл со счетчиком (For)
Записывается так: for <переменная>:=<нач> to <кон> do <оператор>. Вместо toвозможно слово downto. Рассмотрим такой пример: требуется вывести на экран таблицу квадратов натуральных чисел от 2 до 20.
var i: integer;
begin for i:=2 to 20 do writeln(i,' ',sqr(i)); end.
При выполнении цикла происходит следующее: переменной i присваивается начальное значение (2), затем выполняется оператор (простой или составной), после этого к i прибавляется 1, и проверяется, не стало ли значение i равно конечному (20). Если нет, то вновь выполняется оператор, добавляется 1, и т. д. В случае, когда вместо toиспользуется downto, все происходит наоборот: единица не прибавляется, а вычитается. Например, следующий цикл выведет ту же таблицу, но в обратном порядке:
for i:=20 downto 2 do writeln(i,' ',sqr(i));
В завершение запишем программу о подсчете суммы чисел от 1 до 100 с помощью for:
var i, sum: integer;
begin
sum:=0;
for i:=1 to 100 do sum:=sum+i;
writeln(sum);
end.
Лекция 5. Символьные и строковые переменные
В математике под переменной обычно понимают некую величину, значения которой могут быть только числами. В языках программирования почти все данные, с которыми работают программы, хранятся в виде переменных. В частности, бывают переменные для хранения текстовых данных: предложений, слов и отдельных символов.
1. Символьный тип
Тип данных, переменные которого хранят ровно один символ (букву, цифру, знак препинания и т.п.) называется символьным, а в Паскале — char. Объявить переменную такого типа можно так:var ch: char;. Для того чтобы положить в эту переменную символ, нужно использовать оператор присваивания, а символ записывать в апострофах, например: ch:='R';. Для символьных переменных возможно также использование процедуры readln, например:
write(‘Выйти из игры? (Да/Нет)’); readln(ch);
if ch=’Д’ then ...{выходить}...
else ...{продолжать}...;
Символьные переменные в памяти компьютера хранятся в виде числовых кодов, иначе говоря, у каждого символа есть порядковый номер. К примеру, код пробела равен 32, код ‘A’ — 65, ‘B’ — 66, ‘C’ — 67, код символа ‘1’ — 48, ‘2’ — 49, ‘.’ — 46 и т. п. Некоторые символы (с кодами, меньшими 32) являются управляющими, при выводе таких символов на экран происходит какое либо действие, например, символ с кодом 10 переносит курсор на новую строку, с кодом 7 — вызывает звуковой сигнал, с кодом 8 — сдвигает курсор на одну позицию влево. Под хранениесимвола выделяется 1 байт (байт состоит из 8 бит, а бит может принимать значения 0 или 1), поэтому всего можно закодировать 28=256 различных символов.Кодировка символов, которая используется Турбо-Паскале, называется ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией).
Для того чтобы получить в программе код символа нужно использовать функцию chr, например:
var i: byte; {число, занимающее 1 байт, значения — от 0 до 255}
ch: char;
...
readln(i); writeln('символ с кодом ',i,' — это ',chr(i));
Если в качестве кода используется конкретное число, а не выражение и не переменная, то можно использовать символ «#», скажем так: ch:=#7;.Для того перехода от кода к символу используется функция ord (от слова ordinal — порядковый). Имеющиеся знания позволяют нам написать программу, которая выдаёт на экран таблицу с кодами символов:
program ASCII;
var ch: char;
begin
for ch:=#32 to #255 do write(ord(ch),'—>',ch,'');
readln;
end.
В этой программе в качестве счётчика цикла была использована символьная переменная, это разрешается, поскольку цикл for может использовать в качестве счётчика переменные любого типа, значения которого хранятся в виде целых чисел.
С использованием кодов работают ещё две функции, значения которых символьные:
1. succ (от succeedent — последующий), она выдаёт символ со следующим кодом.
2. pred (от predecessor — предшественник), выдаёт символ с предыдущим кодом.
Если попытаться в программе получить succ(#255) или pred(#0), то возникнет ошибка. Пользуясь этими функциями можно переписать предыдущую программу и по-другому:
...
ch:=#32;
while ch<>#255 do begin
write(ord(ch),'—>',ch,'');
ch:=succ(ch);
end;
...
Сравнение символов. Также как и числа, символы можно сравнивать на =, <>, <, >, <=, >=. В этом случае Паскаль сравнивает не сами символы, а их коды. Таблица ASCII составлена таким образом, что коды букв (латинских и большинства русских) возрастают при движении в алфавитном порядке, а коды цифр расположены по порядку: ord(‘0’)=48, ord(‘1’)=49, ... ord(‘9’)=57. Сравнения символов можно использовать везде, где требуются логические выражения: в операторе if, в циклах и т.п.
2. Строковый тип
Для хранения строк (то есть последовательностей из символов) в Турбо-Паскале имеется тип string. Значениями строковых переменных могут быть последовательности различной длины (от нуля и более, длине 0 соответствует пустая строка). Объявить строковую переменную можно двумя способами: либо var s: string; (максимальная длина строки — 255 символов), либо var s: string[n]; (максимальная длина — n символов, n — константа или конкретное число).
Для того чтобы положить значение в строковую переменную используются те же приёмы, что и при работе с символами. В случае присваиванияконкретной строки, это строка должна записываться в апострофах (s:='Hello, world!'). Приведём простейший пример со строками: программа спрашивает имя у пользователя, а затем приветствует его:
program Hello;
var s: string;
begin
write('Как Вас зовут: ');
readln(s);
write('Привет, ',s,'!');
readln;
end.
Хранение строк. В памяти компьютера строка хранится в виде последовательности из символьных переменных, у них нет индивидуальных имён, но есть номера, начинающиеся с 1). Перед первым символом строки имеется ещё и нулевой, в котором хранится символ с кодом, равным длине строки. Нам абсолютно безразлично, какие символы хранятся в байтах, находящихся за пределами конца строки. Рассмотрим пример. Пусть строка s объявлена как string[9], тогда после присваивания s:=’Привет’; она будет хранится в следующем виде:
|
Номер байта |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
Содержимое |
#6 |
‘П’ |
‘р’ |
‘и’ |
‘в’ |
‘е’ |
‘т’ |
‘ю’ |
‘s’ |
‘%’ |
Для того чтобы в программе получить доступ к n-му символу строки используется запись s[n]. Если поменять значение s[0] то это отразится на длине строки. В следующем примере из строки 'Привет' мы сделаем 'Привет!': s[0]:=#7; s[7]:='!';.
Сравнение строк. Строки сравниваются последовательно, по символам. Сравниваются первые символы строк, если они равны — то вторые, и т. д. Если на каком-то этапе появилось различие в символах, то меньшей будет та строка, в которой меньший символ. Если строки не различались, а затем одна из них закончилась, то она и считается меньшей. Примеры: 'ананас'<'кокос', 'свинья'>'свинина', ''<'A', 'hell'<'hello'.
Склеивание (конкатенация) строк. К строкам можно применять операцию «+», при этом результатом будет строка, состоящая из последовательно записанных «слагаемых». Пример: после действия s:= 'abc'+'def'+'ghi'; переменная s будет содержать ‘abcdefghi’.
Процедуры и функции для работы со строками. Наиболее часто употребляется функция length(s: string): integer (после двоеточия записан тип значения, возвращаемого функцией, в нашем случае — целое число).Эта функция возвращает длину строки s.
Другие процедуры и функции приведены в таблице:
|
Процедура или функция |
Назначение |
Пример |
|
функция Copy(s:
string; start: integer; |
Возвращает вырезку из строковой переменной s, начиная с символа с номером start, длина которой len |
s:=’Бестолковый’; s1:=Copy(s,4,4); {в s1 станет ‘толк’} |
|
функция Pos(s1: string; s: string): byte |
Ищет подстроку s1 в строке s. Если находит, то возвращает номер символа, с которого начинается первое вхождение s1 в s; если s1 не входит в s, то функция возвращает 0 |
n:=pos(‘министр’, ‘администратор’); {=3} n:=pos(‘abc’, ‘stuvwxyz’);{=0} |
|
процедура Insert(s1:
string; s:string; |
Вставляет строку s1 в строковую переменную s начиная с символа с номером start. |
S:=‘кот’; insert(‘мпо’,s,3); {в s станет ‘компот’} |
|
процедура Delete(s:
string; start: integer; |
Удаляет из строковой переменной s фрагмент, начинающийся с символа с номером start и длиной len |
s:= ‘треугольник’; delete(s,4,7); {в s останется ‘трек’} |
Лекция 6. Перечисляемый и ограниченный типы
1. Перечисляемый тип
Предположим, что нам требуется переменная для хранения дня недели. В этом случае можно воспользоваться целым типом (например byte) и хранить дни недели в виде чисел 1, 2, ... 7, но это будет не очень наглядно. Турбо Паскаль предоставляет более удобный вариант, а именно создание перечислимого типа, например, такого:
type Days = (Mon, Tue, Wed, Thu, Fri, Sat, Sun);
После этого можно завести переменную этого типа (var day: Days;)и использовать её. Ниже приведены примеры использования:
day:=Wed;
...
if day>Fri then writeln('Сегодня выходной');
...
if day=Mon then writeln('Началась рабочая неделя');
Как вы уже заметили значения перечислимого типа можно сравнивать, при этом меньшим считается то, которое объявлено раньше (левее) в определении типа.
Для переменных перечисляемых типов возможно применение функций succ и pred, например, succ(Wed) дает Thu, Pred(Sun) дает Sat. Если попытаться написать Pred(Mon) или Succ(Sun), то уже на этапе проверки программы компилятором произойдет ошибка.
Хранение значений перечисляемого типа устроено внутри довольно просто: хранятся целые числа от 0 до n, в нашем случае n=6. Существует функция Ord, которая позволяет получить то число, в виде которого хранится какое-либо значение перечисляемого типа, например Ord(Wed) дает 2. При необходимости можно получить значение перечисляемого типа по его численному представлению, например, Days(1) есть Tue. После всего сказанного можно заметить, что при сравнении величин перечисляемого типа в действительности сравниваются их порядковые номера (Ord).
Пример использования перечисляемых типов:
Пусть корабль может двигаться только по четырем направлениям: на север, на запад, на юг и на восток, то есть текущее направление движения определяется переменной типа Directions = (North, West, South, East);. Этому кораблю можно подавать приказы следующих типов: вперёд, назад, влево, вправо, то есть любой приказ задать переменной типа Orders = (Ahead, Back, Left, Right);. Пусть корабль двигался по направлению d1, после чего ему дали приказ p. Программа должна определить, в каком направлении корабль будет двигаться после выполнения приказа.
program Ship;
type Courses = (North, West, South, East);
Orders= (Ahead, Back, Left, Right);
var d1, d2: Courses;
p: Orders;
i: integer;
s: string;
begin
{Запрашиваем у пользователя информацию о курсе и приказе}
writeln('Введите первоначальный курс корабля ');
write('(0-север, 1-запад, 2-юг, 3-восток) ');
readln(i);
d1:=Courses(i);
writeln('Введите приказ, данный кораблю ');
write('(0-прямо, 1-назад, 2-влево, 3-вправо) ');
readln(i);
p:=Orders(i);
{Определяем новый курс}
case p of
Ahead : d2:=d1;
Back: d2:=Courses((ord(d1)+2) mod 4);
Left: d2:=Courses((ord(d1)+1) mod 4);
Right : d2:=Courses((ord(d1)+3) mod 4);
{-1 - нельзя, так как (Ord(North)-1) mod 4 = -1}
end;
{Выводим результат на экран}
case d2 of
North : s:='север';
West: s:='запад';
South : s:='юг';
East: s:='восток';
end;
writeln('Теперь корабль движется на '+s);
readln;
end.
2. Ограниченный тип
Этот тип также рассмотрим на примере. Пусть в некоторой переменной нужно хранить текущее число, то есть номер дня в месяце. В Турбо Паскале можно задать тип DaysInMonth = 1..31;. Переменные и константы этого типа могут принимать только такие значения, если попытаться задать что-либо другое, то компилятор выдаст ошибку. В качестве границ могут употребляться и отрицательные числа, например Temperature=-60..50;
В качестве базового типа (то есть типа, из которого выбирается диапазон значений) могут использоваться почти все порядковые типы, то есть те, которые хранятся в виде целых чисел. К порядковым типам относятся: все целые типы (byte, integer, и т. п.), char, boolean, перечисляемые типы и ограниченные типы. В качестве базового типа нельзя использовать лишь сам ограниченный тип (трудно представить, как это можно сделать). С учетом этого правила допустимы такие объявления типов:
type SmallLatin = 'a'..'z'; {малые латинские буквы}
MyBoolean = True..False; {хотя это и бессмысленно}
Holidays = Sat..Sun; {выходные}
Нельзя в качестве базового типа употребить какой-либо вещественныйтип, следующее объявление приведет к ошибке:
type Wrong = -1.25..1.25;
Заметим, что функции Ord, Succ и Pred могут применяться к любым порядковым типам, и, в частности, к ограниченным.
Лекция 7. Массивы
1. Понятие массива. Одномерные массивы
Массивы являются представителями структурированных типов данных, то есть таких, переменные которых составлены из более простых элементов согласно определённому порядку. Для массивов характерно то, что они являются совокупностью некоторого числа одинаковых элементов. В простейшем случае эти элементы могут быть занумерованы натуральными числами из некоторого диапазона. Рассмотрим пример такой переменной в Турбо Паскале:
var a: array [1..10] of real;
Переменная a состоит из десяти ячеек типа real, можно записывать и извлекать значения из них, пользуясь записьюa[<номер ячейки>].
Пример 1. Поиск наибольшего числа среди элементов массива.
program FindMaximumInArray;
var a: array[1..10] of real;
i,max: integer;
begin
for i:=1 to 10 do begin
write('Введите элемент номер ',i,' -> ');
readln(a[i]);
end;
max:=a[1];
for i:=2 to 10 do
if a[i]>max then max:=a[i];
writeln('Максимум равен ',max);
readln;
end.
В качестве типа элементов массива можно использовать все типы, известные нам на данный момент (к ним относятся все числовые, символьный, строковыйи логический типы).
Нумеровать элементы массивов можно не только от единицы, но и от любого целого числа. Вообще для индексов массивов подходит любой порядковый тип, то есть такой, который в памяти машины представляется целым числом. Единственное ограничение состоит в том, что размер массива не должен превышать 64 Кб. Рассмотрим некоторые примеры объявления массивов.
var Numbers: array [0..1000] of integer;
Names: array [1..10] of string;
Crit: array[shortint] of boolean;
CountAll: array[char] of integer;
Count: array['a'..'z'] of integer;
В следующем примере показано для чего может понадобиться последний тип.
Пример 2. Подсчет количества различных букв в строке.
program CountLetters;
var s: string;
count: array['a'..'z'] of byte;
ch: char;
i: byte;
begin
write('Введите строку > ');
readln(s);
for i:=1 to length(s) do
if (s[i]>='a')and(s[i]<='z') then inc(count[s[i]]);
writeln('Количество различных букв в строке: ');
for ch:='a' to 'z' do
if count[ch]<>0 then
writeln(ch,': ',count[ch]);
readln;
end.
2. Многомерные массивы
При необходимости можно нумеровать массивы не одним индексом а двумя и более. Двумерному массиву соответствует матрица в математике, то есть прямоугольная таблица.
Примеры описаний многомерных массивов:
var Matrix: array[1..4,1..3] of real;
Cube3D: array[1..5,1..5,1..5] of integer;
Рассмотрим пример использования двумерного массива.
Пример 3. Построить календарь на следующий год, то есть при вводе номера месяца и числа выдавать день недели.
program Calendar;
type tWeekDay = (Mon,Tue,Wed,Thu,Fri,Sat,Sun,NoDay);
{NoDay - нет дня (например, 30.02)}
tCalendar = array [1..12,1..31] of tWeekDay;
var CL: tCalendar;
m,d: byte; {месяц и число}
wd: tWeekDay; {день недели}
begin
{Строим массив:}
{1. Заполним весь календарь значениями "нет дня":}
for m:=1 to 12 do
for d:=1 to 31 do CL[m,d]:=NoDay;
{2. Строим массив-календарь:}
m:=1; d:=1;
wd:=Mon;
repeat
CL[m,d]:=wd;
case m of
4,6,9,11: if d=30 then begin m:=m+1; d:=1; end else d:=d+1;
1,3,5,7,8,10,12: if d=31 then begin m:=m+1; d:=1; end else d:=d+1;
2: if d=28 then begin m:=m+1; d:=1; end else d:=d+1;
end;
wd:=tWeekDay((ord(wd)+1) mod 7);
until m=13;
{Выводим на экран:}
repeat
write('Номер месяца > '); readln(m);
write('Число > '); readln(d);
case CL[m,d] of
Mon: writeln('Понедельник');
Tue: writeln('Вторник');
Wed: writeln('Среда');
Thu: writeln('Четверг');
Fri: writeln('Пятница');
Sat: writeln('Суббота');
Sun: writeln('Воскресенье');
NoDay: writeln('Такого дня нет в календаре');
end;
until false;
end.
3. Сортировка и поиск
В прикладных программах широко распространены два типа операций, связанных с массивами:
1.
2.
Рассмотрим простейший вариант сортировки массива (сортировка выбором). Пусть есть массив из n элементов; сначала найдём в нём самый маленький среди элементов с номерами 2,3,...n и поменяем местами с первым элементом, затем среди элементов с номерами 3,4,...n найдём наименьший и обменяем со вторым, и т. д. В результате наш массив окажется отсортированным по возрастанию.
program SelectSort;
const n = 10;
var a: array [1..n] of integer;
i,j,jmin,buf: integer;
{jmin - номер наименьшего элемента,
buf используется при обмене значений двух элементов}
begin
for i:=1 to 10 do begin
write('Введите элемент номер ',i,' -> ');
readln(a[i]);
end;
for i:=1 to n-1 do begin
jmin:=i;
for j:=i+1 to n do
if a[j] buf:=a[i]; a[i]:=a[jmin]; a[jmin]:=buf; end; write('Результат:
'); for i:=1 to 10 do write(a[i],' '); readln; end. Другой способ — пузырьковая сортировка, он работает чуть
быстрее, чем предыдущий. На первом этапе двигаемся от n-го элемента до 2-го и для каждого из
них проверяем, не меньше ли он предыдущего; если меньше, то меняем местами
текущий и предыдущий. В итоге первый элемент будет наименьшим в массиве. На
втором этапе также проходим элементы от n-го до 3-го, на третьем — от n-го
до 4-го, и т. д. В итоге массив будет отсортирован по возрастанию. program BubbleSort; ... var i,j: integer; buf:
integer; begin ... for i:=2 to n do for j:=n downto i do if a[j]
buf:=a[j];
a[j]:=a[j-1];
a[j-1]:=buf; end; end. Тип запись, также как и массив, является структурированным
типом данных, то есть таким, переменные которого составлены из нескольких
частей. В Турбо-Паскале существует возможность объединить в одну переменную
данные разных типов (тогда как в массиве все элементы имеют одинаковый тип).
Приведём пример такого типа. Пусть в переменной требуется хранить сведения о
некотором человеке: ФИО, пол, адрес, телефон. Тогда для хранения этих данных
будет удобен такой тип: type tPerson = record
Name,Surname,SecondName: string[30]; Male: boolean; Address:
string; Phone:
longint; end; Объявление
переменной типа запись выполняется стандартно, с помощью var. Части записи (в нашем случае: Name, Surname, SecondName, Male,
Address, Phone)называются полями. Обращение к полю записи в
программе производится с помощью знака ‘.’
(точка). Пример обращения к полям: var p: tPerson; ... begin ... p.Surname:=’Иванов’; p.Name:=’Иван’; p.SecondName:=’Иванович’; ... if(p.Phone<0) or(p.Phone>999999) thenwriteln(‘Ошибка’); ... end. Заметим, что в этом примере постоянно приходится обращаться
к полям одной и той же переменной типа запись, и, следовательно, постоянно
писать её имя. Есть возможность избавиться от этого неудобства. В Турбо Паскале
есть оператор присоединения (with), который позволяет один
раз указать, какой записью мы пользуемся и в дальнейшем писать только имена
полей. Обычно этот оператор выглядит так: with <имя_записи> do <оператор>; Чаще всего в качестве оператора
используется составной оператор. Пример: with p do begin Surname:=’ Иванов’; Name:=’Иван’; ... end; Записи можно включать в состав более сложных переменных,
например массивов и других записей. При необходимости хранения информации о
сотрудниках некоторой организации может оказаться полезным массив: const N = 30; typetStaff = array [1..N] of tPerson; Рассмотрим другой пример, где иллюстрируется использование
вложенных записей. Пусть прямоугольник определяется координатами точки,
являющейся его левым верхним углом, шириной, высотой и цветом линий. На Турбо
Паскале эти сведения можно объединить в такую запись: type
tPoint = record x,y: integer; end; tRectangle = record LeftTop: tPoint; Width, Height: integer; Color: integer; end; Для такой записи можно применять ещё одну форму оператора with,
которая может «присоединять» несколько имён записей, например: var rect: tRect; with rect, LeftTop do begin x:=100; y:=150; Color:=11; ... end; Без использования with появились бы выражения вида rect.Color, rect.LeftTop.x,
rect.LeftTop.y и т. п. Покажем теперь, как можно использовать массивы внутри
записей. Предположим, что требуется хранить информацию уже не о прямоугольнике,
а о произвольном многоугольнике. В этом случае потребуется задать количество
точек в нём и список всех этих точек, то есть массив. Требуется предусмотреть
возможность хранения сведений о многоугольниках с различным числом вершин,
поэтому сделаем массив довольно большим, а реальное число вершин будем хранить
в отдельном поле записи. Всё это будет выглядеть следующим образом: const MaxVertex = 200; type
tPolygon = record size: integer; V: array [1..MaxVertex] of
tPoint; Color: tColor; end; Существует разновидность записей, которая содержит так
называемую вариантную часть. Для
лучшего понимания рассмотрим их на примере. Пусть запись должна хранить полную
информацию о геометрической фигуре: цвет, положение и размеры (для окружности —
координаты центра и радиус, для прямоугольника — координаты левой верхней и
правой нижней вершин, для квадрата — координаты левой верхней вершины и длина
стороны). В принципе, можно было бы включить в запись все перечисленные выше
поля, но в таком случае большинство из них часто оставались бы незанятыми,
поэтому удобнее будет такое решение: type tFKind = (fCir,fRect,fSqr); tFigure
= record
Color: integer; case kind: tFKind of
fCir:(Center: tPoint; r:
integer);
fRect: (LeftTop,RightBottom: tPoint);
fSqr:(LT: tPoint; size:
integer); end; В этой записиимеется
одно обычное поле (Color),
а остальные 6и представляют собой
вариантную часть. Для окружности в ней имеются поля Center и r, для прямоугольника — LeftTop и RightBottom, для квадрата — LT и size.Фраза kind:
tFKind не является обязательной, она служит для понимания того, какие
поля к каким фигурам относятся. Можно написать просто case integer of ... и нумеровать
варианты целыми числами. Заметим также, что в объявлении нашей записи нет слова
end, относящегося к case. Байты: Color R RightBottom LeftTop size LT Center Мы можем обращаться к любому полю вариантной части, однако
следует помнить, что при записи данных в поле для одной фигуры поля для
другихфигур могут измениться. Чтобы
понять, почему так происходит, достаточно рассмотреть способ хранения
переменной типа tFigure: Из рисунка видно, что вариантная часть хранится в одной
части памяти, то есть поля могут накладываться друг на друга. Процедура – последовательность действий (записанных
на Паскале), названная каким-либо именем. Для того чтобы выполнить эту
последовательность, нужно в соответствующем месте программы указать её имя
(так, например, для очистки экрана при работе с графикой мы указываем ClearDevice;). Кроме того,
что программа становится при использовании процедур короче и понятнее,
процедуры можно вызывать из разных мест программы (в противном случае пришлось
бы повторять в тексте программы одинаковые последовательности действий
несколько раз). Те действия, которые входят в процедуру, записываются до
начала основной программы в следующем виде: program ... const ... type ... var ... procedure MyProc; begin {действия} end; begin {основная программа} end. Рассмотрим пример нахождения максимума из трёх чисел: program Max1; var a,b,c,m: integer; begin
write('Введите a: '); readln(a);
write('Введите b: '); readln(b);
write('Введите c: '); readln(c); if a>b then m:=a else m:=b; if c>m then m:=c;
writeln('Максимум = ',m); readln; end. Перепишем его с использованием процедуры: program Max2; var a,b,c,m: integer; procedure FindMax; begin if a>b then m:=a else m:=b; if c>m then m:=c; end; begin
write('Введите a: '); readln(a);
write('Введите b: '); readln(b);
write('Введите c: '); readln(c); FindMax;
writeln('Максимум = ',m); readln; end. Этот вариант можно улучшить. Пока наша процедура может
искать минимум только среди значений конкретных переменных a, b
и c. Заставим её искать минимум среди любых трёх целых чисел и
помещать результат в нужную нам переменную, а не всегда в m. Чтобы была видна польза от такой процедуры, рассмотрим
пример программы для поиска максимума среди чисел a+b, b+c и a+c: program Max3; var a,b,c,m: integer; procedure FindMax(n1,n2,n3: integer; var
max: integer); begin if n1>n2 then max:=n1 else
max:=n2; if n3>max then max:=n3; end; begin
write('Введите a: '); readln(a);
write('Введите b: '); readln(b);
write('Введите c: '); readln(c);
FindMax(a+b,b+c,a+c,m);
writeln('Максимум из сумм = ',m); readln; end. В скобках после имени процедуры (в её описании) записаны так
называемые параметры. Эта запись обозначает, что внутри процедуры можно
использовать целые числа, обозначенные n1, n2 и n3,
а также заносить значения в переменную типа integer, которая внутри процедуры называется max (а реально во время работы программы
все действия производятся над переменной m). Параметры, в которых хранятся числа (n1,n2,n3)называются параметрами-значениями;
а те, которые обозначают переменные (max) –параметрами-переменными,
перед ними в описании ставится слово var.Параметры, на
которые имеются ссылки внутри процедуры (n1, n2, n3, max), называются формальными,
а те, которые реальноиспользуются
при вызове (a+b, b+c, a+c, m)
— фактическими. Процедуры последнего вида оказываются достаточно удобными.
Можно один раз написать такую процедуру, убедиться в её работоспособности и
использовать в других программах. Примерами таких процедур являются процедуры
для работы со строками, встроенные в Турбо-Паскаль. В нашем примере можно переписать программу и по-другому.
Максимум из трёх чисел определяется по ним однозначно, или, говоря
математическим языком, является функцией этих трёх чисел. Понятие функции есть
также и в Паскале. Рассмотрим такую программу: program Max4; var a,b,c,m: integer; function Max(n1,n2,n3: integer) : integer; var m: integer; begin if n1>n2 then m:=n1 else m:=n2; if n3>m then m:=n3; Max:=m; end; begin
write('Введите a: '); readln(a);
write('Введите b: '); readln(b);
write('Введите c: '); readln(c); writeln('Максимум
= ',Max(a+b,b+c,a+c)); readln; end. Нам уже известно как вызывать функцию из программы (например
sqrt, sin и т. п.).
Рассмотрим описание функции. Оно очень похоже на описание процедур, но есть два
отличия: 1. 2. Max:=m;). В записанной выше функции используется так называемая локальная переменная m,
то есть переменная, которая «видна» только нашей функции, а другие процедуры и
функции, а также главная программа её «не видят». Кроме локальных переменных в
Турбо-Паскале можно определять локальные константы и типы. Приведём другие примеры
процедур и функций. 1. function Cube(x: real): real; begin
Cube:=x*x*x; end; 2. function Square(a,b,c: real):
real; var p: real; begin
p:=(a+b+c)/2;
Square:=sqrt(p*(p-a)*(p-b)*(p-c)); end; 3. procedure SqEquation(a,b,c: real; var
RootsExist: boolean; var x1,x2: real); var d: real; begin
d:=sqr(b)-4*a*c; if d>=0 then begin
RootsExist:=true;
x1:=(-b+sqrt(d))/(2*a);
x2:=(-b-sqrt(d))/(2*a); end else RootsExist:=false; end; Можно вместо процедуры написать и функцию, по логическому
значению которой мы определяем, есть ли корни, а сами корни передаются также
как и в процедуре: function EqHasRoots(a,b,c: real; var
x1,x2: real) : boolean; var d: real; begin
d:=sqr(b)-4*a*c; if d>=0 then begin
EqHasRoots:=true;
x1:=(-b+sqrt(d))/(2*a);
x2:=(-b-sqrt(d))/(2*a); end else EqHasRoots:=false; end; Использовать такую функцию даже проще чем последнюю
процедуру: if EqHasRoots(1,2,1,r1,r2) then writeln(r1,' ',r2) else
writeln('Нет корней'); Модуль CRT
- набор средств для работы с экраном в текстовом режиме, клавиатурой и
для управления звуком. Для того чтобы использовать эти средства требуется после
заголовка программы записать: uses
CRT;. В текстовом режиме экран представляется разбитым на
маленькие прямоугольники одинакового размера, в каждом из которых может
находиться какой-либо символ из набора ASCII. Для символов можно задавать цвет самого символа и цвет
прямоугольника, в котором он рисуется (цвет фона). Строки экрана нумеруются
сверху вниз, а столбцы слева направо, нумерация и строк, и столбцов начинается
с единицы. Наиболее
распространённым в настоящее время является текстовый режим 80x25 при 16 возможных цветах текста и
фона. Многие графические адаптеры позволяют использовать другие режимы,
например: 40x25, 80x43, 80x50 и т. д. В управлении текстовым экраном важную роль играет курсор.
Вывод символов на экран (т.е. write и writeln)
осуществляется начиная с позиции курсора, когда все символы выведены, курсор
останавливается в следующей позиции после последнего символа. Ввод также будет
производиться начиная с позиции курсора. Ниже приведены основные
процедуры и функции для управления экраном в текстовом режиме. Название Назначение InsLine Вставить строку в том месте где
находится курсор, все строки ниже курсора сдвигаются вниз на одну позицию.
Курсор остаётся на том же месте. DelLine Удалить строку в позиции курсора.
Курсор остаётся на том же месте. GotoXY(x,y: byte) Переместить курсор в позицию (x,y); x — номер строки, y —
номер столбца. ClrEOL Очистить строку от курсора и до
правого края экрана. Курсор остаётся на прежнем месте HighVideo Устанавливает повышенную яркость
для вывода текста LowVideo Пониженная яркость NormVideo Нормальная яркость TextColor(color: byte) Устанавливаетцвет для вывода текста. Значения цветов — обычно
числа от 0 до 15. Вместо этих чисел можно указывать и существующие константы
(black, white, red, green,
blue, magenta, cyan, brown, lightgray и т. п.). При необходимости
можно заставить текст мерцать прибавляя к номеру цвета число 128 или
константу Blink. TextBackGround(color:
byte) Устанавливает цвет для фона. ClrScr Очистить экран и поместить курсор
в левый верхний угол, т.е. в позицию (1,1) — 1-я строка, 1-й столбец. При очистке экран заполняется цветом
фона (см. TextBackground) WhereX: byte Эта функция возвращает номер
строки, в которой находится курсор. WhereY: byte Номер столбца, в котором находится
курсор При работе с клавиатурой компьютер помещает всю информацию о
нажатии клавиш в очередь до тех пор, пока эта информация не потребуется
программе (например, для вывода на экран, для движения объектов в играх и
т.п.). Для работы с клавиатурой важны 2 функции: 1.
KeyPressed:
boolean — возвращает
true, если очередь клавиатуры не пуста (то есть была нажата).
Простейший пример использования — повторять какие либо действия, пока не нажата
клавиша: repeat ... until KeyPressed;. 2. ReadKey: char — возвращает символ, соответствующий нажатой
клавише (из очереди клавиатуры). Если пользователь нажал клавишу, для которой
имеется код ASCII, то в очередь будет положен один
соответствующий символ, а если это специальная клавиша (F1, F2,
... F12, клавиши управления курсором, Ins, Del, Home, End, PgUp,
PgDn), то сначала в очередь будет положен символ с кодом 0, а затем
дополнительный символ. Если очередь клавиатуры пуста, то Readkey будет
ждать, пока пользователь не нажмёт какую-либо клавишу. Для демонстрации работы ReadKey можно
написать такую программу: uses Crt; var c: char; begin repeat
c:=ReadKey;
writeln(ord(c)); until c=#27 {клавиша Escape}; end. При нажатии вышеперечисленных специальных клавиш эта
программа будет выводить по два кода сразу. При необходимости организации задержек в программе можно
использовать процедуру Delay(time:
word). Параметр time — время в
миллисекундах, на которое нужно приостановить программу. Ещё одна возможность модуля CRT — работа ссистемным динамиком. Для включения звука нужна процедура Sound(f: word) (f — частота в герцах). После включения требуется задержка (Delay) на необходимое время
звучания, затем — выключение с помощью NoSound. Если не воспользоваться NoSound, то звук будет слышен
даже после выхода из программы на Паскале. В отличие от уже знакомого текстового режима, экран в
графическом режиме разбит на большое количество точек, каждая из которых может
иметь определённый цвет. Точки считаются одинаковыми и прямоугольными, все они
плотно «уложены» на экране, то есть для любой точки можно указать, в какой
строке и в каком столбце она находится. Номера строк и столбцов в графическом
режиме используются как координаты точки, следовательно, координаты всегда
целочисленные. В графическом режиме начало координат находится в левом верхнем
углу экрана, ось x направлена вправо, ось y направлена
вниз. Заметим, что существуют разные графические режимы, они
отличаются количеством точек по горизонтали и вертикали(разрешением), а также количеством возможных цветов,
например: 320x200x16,
640x480x16, 640x200x16, 800x600x256 и т. п. Все средства для работы с графикой содержаться в стандартном
модуле Graph, поэтому его нужно будет
упоминать после слова uses. Для включения графического режима
используется процедура InitGraph(driver,mode,path)опишем назначение её
параметров: driver – переменная
типа integer, в котором
задаётся тип видеоадаптера, установленного в компьютере. В модуле определены
константы для различных адаптеров, которые избавляют нас от необходимости
запоминать числа. Имеются такие константы:
CGA, EGA, EGA64,
EGAMono, VGA, MCGA, IBM8514 и т. п. Для нас наиболее важной будет
константа detect, при
указании которой InitGraph
сама подыщет наиболее мощный тип адаптера, совместимый с тем адаптером, который
установлен на компьютере. mode –
также переменная типа integer,
задаёт режим, в котором работает выбранный видеоадаптер (здесь также определены
константы). Почти каждый видеоадаптер может работать в нескольких режимах,
например, у VGA есть
640x200x16 (VGALo), 640x350x16 (VGAMed), 640x480x16 (VGAHi).Если в первом параметре было указано
значение detect, то InitGraph не обращает
внимания на mode, а
устанавливает наилучший, на её взгляд, режим. path – строковый
параметр. Для каждого видеоадаптера (или для группы сходных видеоадаптеров)
существует программа-драйвер, с помощью которой модуль Graph общается с видеоадаптером.Такие
драйверы хранятся в файлах с расширением «bgi». В параметре path указывается каталог, в котором хранятся драйверы. Если они
находятся в текущем каталоге, то этот параметр равен пустой строке. Обычно для включения графики мы будем использовать InitGraph в таком виде: const gpath = ‘Y:WIN_APPSBPBGI’ var gd,gm: integer; ... begin ... gd:=Detect; InitGraph(gd,gm,gpath); ... Для завершения работы с графикой и выхода в текстовый режим
используется процедура CloseGraph. Система координат при работе с графикой имеет начало (точку
(0,0)) в левом верхнем углу экрана. Ось x направлена вправо, ось y –
вниз. Очевидно, что все точки экрана имеют целочисленные координаты. При построении простейших
элементов изображений используются следующие процедуры и функции: Название Назначение PutPixel(x,y:
integer; c:word); Поставить
точку (x,y),
используя цвет c.
Значение цвета обычно меняется от 0 до 15, вместо номера цвета можно
употреблять цветовые константы модуля Graph. SetColor(c:
word); Установить
текущий цвет для рисования отрезков, окружностей и т. п. Все линии после
употребления этого оператора будут рисоваться установленным цветом. SetBkColor(c:
word); Установить
текущий цвет для фона (то есть цвет всего экрана). GetMaxX;
GetMaxY; Эти
функции возвращают максимальные допустимые значения координат x и y, соответственно. Line(x1,y1,x2,y2:
integer); Рисовать
отрезок из (x1,y1)в (x2,y2) текущим цветом. Rectangle(x1,y1,x2,y2:
integer); Рисует
текущим цветом прямоугольник, левый угол которого – (x1,y1), а правый нижний –(x2,y2).
Circle(x,y:
integer; r: word); Рисует
текущим цветом окружность с центром в точке (x,y) радиуса r. Arc (x,y:
integer; a1,a2,r:word); Рисует
дугу окружности. a1 и
a2 – начальный
и конечный углы (в градусах), соответственно. Угол отсчитывается традиционно,
против часовой стрелки, угол величиной 0° соответствует лучу y=0, x>0. Ellipse(x,y: integer; a1,a2,xr,yr:word); Рисует
дугу эллипса с полуосями xr и
yr от угла a1 до a2. DrawPoly(n: word; P); Рисует
многоугольник, количество сторон в котором – n, а информация о вершинах
хранится в нетипизированном параметре P. В качестве P
удобнее всего использовать массив из записей, каждая из которых содержит
поля x,y: integer; MoveTo(x,y:
integer); Эта
процедура опирается на понятие текущей позиции. Она «запоминает» позицию (x,y) на экране, а в
дальнейшем из этой позиции можно рисовать отрезки. LineTo(x,y:
integer); Рисует
отрезок из текущей позиции в точку (x,y). При этом текущая позиция перемещается в конец нарисованного
отрезка. MoveRel(dx,dy:
integer); Перемещает
текущий указатель из прежнего положения (x,y)в точку (x+dx,y+dy). LineRel(dx,dy:
integer); То же,
что и предыдущая процедура, но при перемещении рисует отрезок от (x,y)до (x+dx,y+dy). GetX; GetY; Возвращают
координаты текущего указателя (по отдельности). ClearDevice; Очищает
экран. Все приведённые выше процедуры для рисования выполняют
только контурные рисунки (не закрашивая прямоугольник, окружность или эллипс
внутри). По умолчанию рисование происходит с использованием тонкой сплошной
линии, однако толщину и вид линии можно менять с помощью процедуры SetLineStyle(style,pattern,width:
word). Рассмотрим назначение параметров этой процедуры. 1. style – вид
линии. Здесь удобно задавать не конкретные числа, а константы: SolidLn, DottedLn, CenterLn, DashedLn, UserBitLn. Первая
обозначает сплошную линию, следующие три – разные виды
прерывистых линий, последняя – линию, вид которой определяется
пользователем (см. ниже). 2. pattern – образец
для вида линии, определяемого пользователем. Этот параметр вступает в действие
лишь тогда, когда в предыдущем указано UserBitLn. Образец – это фрагмент линии, заданный в виде
числа. Переход от конкретного фрагмента к числу выполняется, например, так: Удобнее всего
переводить полученное число в шестнадцатеричный вид, в нашем примере получится $999C. При изображении линии
закодированный нами фрагмент будет повторяться столько раз, сколько нужно. 3. width – толщина
линии. Можно использовать числа, однако определены 2 константы: NormWidth и ThickWidth (нормальная и толстая линии). Перейдём теперь к рисованию
закрашенных фигур. По умолчанию внутренняя область фигуры будет закрашиваться
белым цветом, причём закраска будет сплошной. Для управления цветом и видом
закраски используется процедура SetFillStyle(style, color: word); Также как и
для стиля линии, для style предусмотрены константы: EmptyFill,
SolidFill, LineFill, LtSlashFill, SlashFill, BkSlashFill, LtBkSlashFill,
HatchFill, XHatchFill, InterleaveFill, WideDotFill, CloseDotFill, UserFill.
Первая обозначает отсутствие закраски, вторая – сплошную,
последующие –
различные специфические виды закраски, самая последняя – закраску,
задаваемую пользователем. Чтобы задать пользовательский образец закраски, нужно
использовать процедуру SetFillPattern(Pattern: FillPatternType; Color: Word);
FillPatternType определяется как array[1..8] of byte, каждый элемент массива
кодирует одну строчку образца закраски (как и для линий), а всего таких строчек
8. В результате закраска выполняется с помощью одинаковых квадратиков 8x8.
Ниже
приводятся процедуры рисования закрашенных фигур. Название Назначение Bar(x1,y1,x2,y2: integer); Рисует
закрашенный прямоугольник. FillEllipse(x,y: integer; xr,yr: word); Закрашенный
эллипс. FillPoly(n: word; P); Закрашенный
многоугольник. PieSlice(x,y: integer; a1,a2,r:word); Закрашенный
круговой сектор. Sector (x,y: integer; a1,a2,xr,yr:word); Закрашивает
эллиптический сектор. FloodFill(x,y: integer; Cborder: word); Выливает
краску в точку (x,y),
откуда она растекается во все стороны, пока не достигнет границы цвета Cborder. Если такой границы
нет или она незамкнута, то краска может залить весь экран. Для вывода текста на экран используются две процедуры: 1.
OutText(s: string). Эта процедура выводит
строку s начиная с
текущей позиции, то есть левый верхний угол выводимой строки находится в
текущей позиции (по умолчанию это так). Текущая позиция задаётся, например, с
помощью MoveTo. 2. OutTextXY(x,y: integer; s: string). Используется для вывода строки в
конкретной позиции. Если требуется вывести какие либо числа, то предварительно
требуется преобразовать их в строку, например, с помощью процедуры Str. Пример: var r: integer; s: string; ............... Str(r,s); OutTextXY(100,200,’Результат=’+s); Турбо Паскаль позволяет использовать несколько различных
шрифтов для вывода текста.Кроме
того, можно менятьнаправление вывода текста, а также размер
символов. В этих целях используется процедура SetTextStyle(Font, Direction, CharSize : word).
Перечислим возможные константы и значения для параметров этой процедуры.
Font (шрифт): DefaultFont – шрифт 8x8 (по умолчанию) TriplexFont – полужирный
шрифт SmallFont – тонкий
шрифт SansSerifFont – шрифт без
засечек GothicFont – готический
шрифт. Direction (ориентация и направление
вывода символов): 0 – привычный
вывод слева направо 1 – снизу
вверх (надпись «положена на бок») 2 – слева
направо, но «лежачими» буквами. Size –
размер шрифта (целые числа от 0 до 10). Другая возможность при работе с текстом –
это выравнивание его относительно задаваемых координат вывода. Для этого
используется процедура SetTextJustify(horiz,wert: word). Horiz указывет
как текст расположен относительно заданной позиции по горизонтали, а vert
–
по вертикали. Возможные константы: для horiz: LeftText –
указанная позиция является левым краем строки CenterText – позиция является
серединой выводимой строки RightText –
правым краем строки; для vert: BottomText –
позиция находится на нижнем крае изображения CenterText –
по центру TopText –
позиция является верхним краем изображения. Ниже будут обсуждаться способы взаимодействия программы на
Паскале с текстовыми файлами, записанными на каком-либо диске. Примерами
текстовых файлов могут служить тексты программ на Паскале, простые текстовые
документы и т.п. Любой текст в файле хранится в виде последовательности
символов (char), для
разбиения текста на строки используются невидимые при просмотре символы конца
строки. Для того чтобы программа могла работать с текстовым файлом,
нам потребуется переменная специального файлового типа text: var f: text; Эта переменная не содержит в себе весь текст из файла, она
служит для чтения данных из файла и для записи новых данных в него. Прежде чем работать с конкретным файлом на диске, файловую
переменную следует связать с этим файлом, используя такую процедуру: assign(TxtFile: text, name: string); Первый параметр (TxtFile)— файловая переменная, второй — строка,
содержащая имя файла на диске. Если файл лежит в текущем каталоге, то
достаточно указать только его имя и расширение, если в каком-либо другом, то
потребуется указывать путь к этому файлу, например: assign(f,'Z:SCHOOLtext1.txt'); Перед тем как рассматривать процедуры чтения, заметим что
файл можно обходить только последовательно. Хорошей аналогией файла может
послужить магнитная лента, с которой головка может читать информацию только по
порядку, а для возврата к началу блока данных требуется дополнительное усилие
(перемотка). Чтобы открыть для чтения файл, который был указан при вызове
assign, нужно
использовать процедуру reset(TxtFile: text); После такого действия «читающая
головка» будет установлена на начало файла. Разумеется, указанный файл должен
существовать на диске, в противном случае в программе возникнет ошибка. После открытия файла можно начинать чтение данных. Для этого
используются процедуры read и
readln, которые
используются в следующем формате: read(TxtFile: text, v1: type1, v2: type2, ... vN:
typeN); readln(TxtFile: text, v1: type1, v2: type2, ... vN:
typeN); Первая процедура читает
последовательно из файла значения и помещает их в переменные v1, v2, ... vN. После каждого
прочитанного значения указатель файла
(«читающая головка») смещается к началу следующего значения. Процедура readln делает то же самое,
после чего перемещает указатель на начало следующей строки; readln с одним лишь первым параметром
переводит указатель на начало новой строки. В качестве параметров для процедур read и readln можно использовать переменные
следующих типов: ·integer, byte, shortint, word, longint; ·real, single, double, extended, comp; ·string); ·char). При чтении строковых значений из файла берётся вся
последовательность символов от позиции указателя до конца строки. Если после
этого попытаться вновь прочитать строку, то результат будет пустой строкой ( '' ). Если попытаться прочитать число, когда
указатель файла стоит в конце строки, то будет прочитан 0. При чтении чисел read и readln
работают так: сначала указатель пропускает все пробелы и символы табуляции, а
затем, найдя первый значащий символ, пытается прочитать число. Если это
невозможно (встретилась буква или число записано неверно), то произойдёт
ошибка. Пример использования процедуры чтения: var f: text; s: string; n: integer; ... readln(f,n,s); Необходимо помнить, что если файл не был открыт для чтения с
помощью reset, то любая
попытка прочитать из него данные приведёт к ошибке. Довольно часто в программе бывает необходимо определить,
дошёл ли указатель файла до конца строки или до конца файла. В этом случае
полезно использовать такие функции: eoln(TxtFile: text): boolean; eof(TxtFile: text): boolean; Первая принимает значение true (истина),
если указатель стоит на конце строки, вторая — то же самое для конца
файла. После того как все операции чтения закончены, файл
необходимо закрыть с помощью процедуры close(TxtFile: text); если этого не сделать, то содержимое
файла может оказаться испорченным после выполнения нашей программы. Пример 1 (процедуры
чтения). Пусть имеется текстовый файл, например программа на Паскале. Требуется
распечатать его содержимое на экране: program ShowFile; var f: text; c: char; begin
assign(f,'showfile.pas'); reset(f); while not eof(f) do begin while not
eoln(f) do begin read(f,c);
write(c); end;
readln(f); writeln; end; close(f); readln; end. А теперь перейдём к процедурам записи в файл. Перед тем как
что-либо записывать, нужно создать новый (пустой) файл или стереть содержимое
существующего. Для этого используется процедура rewrite(TxtFile: text); До её вызова файловая должна быть привязана к имени файла на
диске с помощью assign.
Если файл не существовал, то rewrite
создаст его,если
существовал, то содержимое будет стёрто. В любом случае файл будет пустым, а указатель записи стоит на начале файла. Для записи используются процедуры write(TxtFile: text, p1: type1, p2: type2, ... pN:
typeN); writeln(TxtFile: text, p1: type1, p2: type2, ...
pN: typeN); Здесь в качестве параметров p1, p2, ... pN можно
использовать не только переменные, но и выражения: числовых типов, строковые,
символьные и логические (boolean).
В отличие от write, writeln после записи в файл
значений p1, p2, ... pN
переводит указатель записи на начало новой строки; writeln с одним параметром (текстовый
файл) лишь переводит указатель на новую строку. Так же как и в случае с чтением из файла, после того как все
данные записаны файл нужно закрыть с помощью close. Пример 2 (запись в
файл). Пусть дан произвольный текстовый файл, требуется получить другой
файл, в каждой строке которого записана длина соответствующей строки исходного
файла: program WriteLength; var f1,f2: text; s: string; begin
assign(f1,'writelen.pas'); reset(f1);
assign(f2,'result.txt'); rewrite(f2); while not eof(f1) do begin
readln(f1,s);
writeln(f2,length(s)); end; close(f1);
close(f2); end. Ещё один способ записи — это открытие для добавления
информации в конец файла. Для этого используется процедура append(TxtFile: text); Если файл открыт с помощью append, то всё его содержимое
сохраняется. При завершении дописывания в конец файла его также следует закрыть
с помощью close. Двоичный файл представляет собой последовательность
одинаковых элементов, записанных на диске. В отличие от текстовых файлов, в
двоичных нет разбиения на строки, файл напоминает массив, с той лишь разницей,
что доступ к элементам может быть только последовательным. Для того, чтобы
определить, достигнут ли конец файла, по-прежнему используется функция eof. Функция eoln, очевидно, здесь неприменима. Для всех обсуждаемых ниже файлов можно выполнять те же
процедуры открытия, закрытия и привязки, что и для текстовых: Append, Assign,
Close, Reset, Rewrite.
Кроме того, появляется процедура Truncate(var f: file), которая уничтожает всё содержимое файла,
находящееся после текущего указателя чтения. Двоичные файлы будем делить на типизированные и нетипизированные. Файлы этого вида состоят из элементов одинакового типа, то
есть в них нельзя записывать (или читать) значения переменных разных типов, в
отличие от текстовых файлов. Объявляются типизированные файлы так: var f: file of тип_элемента; В качестве типа элемента можно
использовать как простые типы, так и структурированные (массивы, записи и
т.п.). Нетипизированный файл, в отличие от типизированного,
используется для хранения разнородной информации, а не одинаковых элементов. В
него можно записывать (а также читать) значения переменных практически любого
типа (простых типов, массивов, записей, и т. п.). Описываются переменные,
соответствующие нетипизированным файлам, следующим образом: var f: file; Для чтения и записи процедуры read и write не подходят. Используются такие
процедуры: 1. f: file; var buf; count: word
[; var result: word]); –
читает в переменную Buf count записей
из файла, переменная result
показывает сколько записей было скопировано в действительности. Под записью
понимается «кусок» файла в несколько байт, размер записи можно установить при
открытии файла, например: reset(f,1). 2. file; var buf; count: word [; var result: word]); –записывает
указанное количество записей в файл. Если для открытия используется rewrite, то во втором её
параметре также можно указать размер записи. В Турбо Паскале допускается разбивать программы на части и
хранить эти части в отдельных файлах на диске. Кроме основной программы
появляются так называемые модули, которые предоставляют основной программе или
другим модулям свои переменные, константы, типы, процедуры, функции и
т.п. Чтобы использовать модуль в программе, нужно указать его имя после uses. При написании модуля сначала описывается то, что он
предоставляет для общего пользования (секция интерфейса), а затем –
как он устроен (секция реализации). Иногда существует секция инициализации, где
записаны действия, которые выполняются при подключении этого модуля.
Записывается это всё следующим образом: unit MyUnit; interface (*Интерфейсная
секция*) uses ...;
const ...; type ...; procedure ...;{Только function ...; заголовки} implementation (*Секция реализации*) uses ...; const ...; type ...; procedure ...;{Реализация
всех описанных begin процедур и функций} ... end; function ...; begin ... end; [begin] (*Секция
инициализации*) end. Рассмотрим части модуля подробнее. Uses в интерфейсной секции может быть
нужен, если в ней используются какие-либо ресурсы из других модулей. Процедуры
и функции здесь только описываются, но не реализуются, то есть не записываются
тела процедур и функций (begin
... end;). В секции реализации можно также подключать другие модули;
создавать переменные, константы, типы, процедуры и функции, которые «видны»
только внутри этого модуля, никакой другой модуль или программа на можетими пользоваться. Здесь же обязательно должны
быть записаны все процедуры и функции (полностью). Параметры (в скобках) после
имени процедуры и функции в секции реализации можно не указывать. Секция инициализации содержит те действия, которые должны
выполняться когда наш модуль подключается к программе, то есть до того как
начнёт работать сама программа. Модуль graph, например устанавливает в секции инициализации значения по
умолчанию цвета линий и фона, стиль линий, стиль заливки т.п. При сохранении модуля ему нужно дать такое же имя, как и
после unit в тексте
модуля. Имена файлов, содержащих модули, должны иметь расширение «pas»,
также как и программы. Рассмотрим пример. Наш модуль предназначается для операций с
трехмерными векторами: unit Vectors; interface type tVec3D = record
x,y,z: real; end; procedure VecAdd(a,b: tVec3D; var c: tVec3D); procedure VecSub(a,b: tVec3D; var c: tVec3D); procedure VecMultNum(k: real; a:
tVec3D; var b: tVec3D); function ScalarProduct(a,b: tVec3D):
real; implementation procedure VecAdd(a,b: tVec3D; var
c: tVec3D); begin
c.x:=a.x+b.x;
c.y:=a.y+b.y;
c.z:=a.z+b.z; end; procedure VecSub(a,b: tVec3D; var
c: tVec3D); begin
c.x:=a.x-b.x;
c.y:=a.y-b.y;
c.z:=a.z-b.z; end; procedure VecMultNum(k: real; a: tVec3D; var
b: tVec3D); begin b.x:=k*a.x; b.y:=k*a.y; b.z:=k*a.z; end; function ScalarProduct(a,b: tVec3D): real; begin
ScalarProduct:=a.x*b.x+a.y*b.y+a.z*b.z; end; end. В программе наш модуль можно использовать, например, так: program xxx; uses Vectors; var v1,v2,res: tVec3D; ... begin ...
VecMultNum(0.2,v1,res);
VecSub(v2,res,res); {в результате res = v2-0.2×v1} ... end. В случаях, когда несколько модулей содержат объекты с
одинаковыми именами, обращаться к ним нужно с указанием имени модуля: <имямодуля>.<имя объекта> . Пусть, например, модули unit1 и unit2 содержат процедуры с одинаковыми
именами proc1, тогда
обращаться к ним следует так: unit1.proc1;
и unit2.proc2; . Преимущества модулей: 1. те
же фрагменты. 2. Переменные, процедуры и другие объекты можно
скрыть в секции реализации, если их необдуманное выполнение может испортить
программу. 3. 4. Все известные нам на данный момент переменные являются статическими, это означает, что память
под них выделяется один раз при запуске программы, и в течение всего времени её
работы переменные занимают отведённые им участки. Иногда такой подход может
оказаться невыгодным. Например, при хранении табличных данных в виде массива,
приходится заводить массив большого размера, поскольку заранее неизвестно,
сколько строк содержится в таблице. В результате часть памяти, занятая под
массив, не используется. В подобных задачах хотелось бы использовать столько
памяти, сколько необходимо в каждый конкретный момент времени, то есть
распределять память динамически. В Турбо Паскале есть возможность создания динамических переменных (то есть таких,
которые можно заводить и уничтожать во время работы программы по мере
необходимости). Для этого в программе объявляют не саму переменную нужного нам
типа, а указатель на эту переменную, например: var p: ^real; здесь p – имя
переменной-указателя; знак "^" показывает, что p является не обычной переменной, а указателем; real – тип той
переменной, на которую указывает p. Переменная p представляет собой не что иное как адрес того
места в памяти, где будет храниться сама динамическая переменная (в нашем
случае число типа real). Для всех динамических переменных в памяти отводится
пространство, называемое динамической областью,
или кучей. Перед тем как пользоваться
динамической переменной, требуется выделить для неё место в куче. Это делается
с помощью процедуры New, например: New(p); В результате такого действия в куче выделено место под
переменную типа real,
обратиться к ней можно, записав p^,
например p^:=123.5. Если потребуется изменить значение указателя, например,
заставить его указывать на другую переменную, то старую переменную следует
уничтожить, то есть объявить занимаемую старой переменной память свободной.
Если этого не сделать, то при изменении указателя сама переменная станет мусором (место в памяти объявлено
занятым, а получить к нему доступ уже невозможно). Уничтожение динамической переменной
выполняется процедурой Dispose:
Dispose(p); Рассмотрим теперь операции, которые можно выполнять над
указателями. 1. nil, которое
означает «ни на что не указывает». В указатель можно также положить адрес
какой-либо переменной, например: p:=Addr(a); или p:=@a;
хотя необходимость в этом возникает редко. 2. nil,
с адресами переменных. С динамическими переменными можно выполнять все действия,
разрешённые для статических переменных, например: if p^>=q^ then p^:=q^; Рассмотрим теперь несколько искусственный пример использования
динамических переменных: пусть требуется сложить два числа, не используя
статических переменных: var pa,pb: ^real; begin new(pa);
new(pb);
write('Введите a: '); readln(pa^);
write('Введите b: '); readln(pb^);
writeln('a+b=',pa^+pb^);
dispose(pa); dispose(pb); readln; end. Кроме описанных указателей существуют ещё так называемые нетипизированные указатели (тип pointer), которые могут
служить указателями на переменные любых типов, однако необходимость в них возникает
редко, поэтому рассматривать их подробно мы не будем. . .
. Data List Data Data Data Вернёмся теперь к вопросу об экономии памяти при хранении
табличных данных. С использованием указателей можно отказаться от массива и
использовать динамические структуры. Самой простой из них является список, который схематично изображается
так: Прямоугольники на этой схеме –
динамические переменные типа запись, Data –
поле (или поля), содержащие полезную информацию (например фамилии и
номера телефонов), поле, которое изображено ниже Data–
это указатель на следующую запись. Переменная List также является указателем на
запись. Жирная точка в поле «следующий элемент» в самой последней записи
означает, что там лежит значение nil, чтобы показать, что эта запись – последняя
в списке. Для описания списка на Паскале достаточно описать тип
указателя на запись и тип самой записи. Выглядит всё это так: type tItemPtr = ^tItem; {указатель
на элемент} tItem = record Data:
tData; {полезные данные} Next: tItemPtr;
{указатель на следующий элемент
списка} end; В первой строке этого объявления бросается в глаза
использование неопределённого типа tItem. Такое исключение из правил в Турбо Паскале сделано
умышленно, в противном случае не было бы возможности строить списки и другие
связанные структуры из динамических переменных. Объявить сам список можно как указатель на элемент: var List : tItemPtr; пока наш
список пуст, в List следуетположить значение nil. При создании первого элемента будем
выполнять действия New(List);
List^.Next:=nil. В списках всегда хранится ровно столько элементов, сколько
нужно; если какой-либо элемент данных потерял свою ценность, то его всегда
можно удалить из списка;
если появились новые данные, то можно добавить новый элемент. Напишем теперь модуль для работы со списками. В нём
содержатся процедуры первоначальной подготовки списка; добавления элемента в
начало списка; удаления элемента, следующего за указанным; нахождения элемента
с заданным номером; подсчета элементов и очистки списка. unit Lists; interface typetData = record
Name: string[50];
Phone: longint; end;
tItemPtr = ^tItem; tItem =
record Data:
tData; Next:
tItemPtr; end; procedure InitList(var l:
tItemPtr); procedure AddItemToHead(var l:
tItemPtr; d: tData); functionDeleteItemAfter(var l: tItemPtr; num: word): boolean; functionCount(l: tItemPtr): word; functionGetItem(l: tItemPtr; num:
word; var d: tData): boolean; procedure ClearList(var l:
tItemPtr); {---------------------------------------------------------------} implementation procedure InitList(var l:
tItemPtr); begin l:=nil end; procedure AddItemToHead(var l:
tItemPtr; d: tData); var p: tItemPtr; begin new(p); p^.data:=d; p^.next:=l; l:=p; end; function DeleteItemAfter(var l:
tItemPtr; num: word): boolean; var p,q: tItemPtr; i: word; begin i:=1; p:=l; while (i<>num)and(p<>nil) do begin i:=i+1;
p:=p^.next; end; if p<>nil then begin if p^.next<>nil then begin
q:=p^.next^.next; dispose(p^.next);
p^.next:=q;
DeleteItemAfter:=true; end else DeleteItemAfter:=false; {не
удалён} end else DeleteItemAfter:=false; end; function Count(l: tItemPtr): word; var p: tItemPtr; i: word; begin i:=0; p:=l; while p<>nil do begin i:=i+1;
p:=p^.next; end; count:=i; end; function GetItem(l: tItemPtr; num: word; var d: tData): boolean; var p: tItemPtr; i: word; begin i:=1; p:=l; while (i<>num)and(p<>nil) do begin i:=i+1; p:=p^.next; end; if p<>nil then begin
d:=p^.data;
GetItem:=true; end else GetItem:=false; end; procedure ClearList(var l:
tItemPtr); var p: tItemPtr; begin while (l<>nil) do begin
p:=l^.next;
dispose(l); l:=p; end; end; end. Кроме рассмотренных списков возможны более сложные варианты,
связанные с наличием двух дополнительных свойств: 1. 2. next в
последнем элементе указывает на первый элемент. Иначе такие списки называются
кольцевыми. Этот вид позволяет упростить процедуру удаления элемента списка и
другие операции. С учётом этих свойств возможны четыре различных типа
списков. Для примера рассмотрим описание и реализацию кольцевого
двунаправленного списка: type tItemPtr = ^tItem tItem = record data:
tData;
next,prev: tItemPtr; end; var List: tItemPtr; {список -
указатель на один из элементов} ........ {Удалить
после указанного:} procedure DelAfter(p: tItemPtr); var q: tItemPtr; begin if (p<>nil)and(p^.next<>p) then begin
q:=p^.next^.next;
dispose(p^.next);
p^.next:=q;
q^.prev:=p; end; end; {Вставить
перед указанным:} procedure InsertBefore(p: tItemPtr; d: tData); var q: tItemPtr; begin if p<>nil then begin new(q);
q^.data:=d;
q^.next:=p;
q^.prev:=p^.prev;
p^.prev:=q;
q^.prev^.next:=q; end; end; Стеком называется
такой способ хранения данных, при котором элемент, записанный в хранилищеданных,
последним всегда извлекается первым (дисциплина LIFO– «last in - first out»).
При извлечении элемента происходит его удаление со стека. Рассмотрим простейший пример использования стека.
Предположим, что имеется строка, состоящая из одних лишь открывающих и
закрывающих скобок. Требуется определить, является ли она правильным скобочным
выражением (то есть для каждой открывающей скобки должна найтись закрывающая).
Заведём массив и переменную для хранения номера последнего значимого элемента в
массиве (то есть вершины стека), в который при проходе по строке будем
складывать все открывающиеся скобки (с увеличением номера вершины на 1), а при
встрече с закрывающей будем удалять соответствующую открывающую (попросту
уменьшать номер вершины стека). Если окажется, что «пришла» закрывающая скобка,
а стек пуст (то есть номер вершины равен 0), то выражение ошибочно. Это же
можно сказать и в случае, когда строка закончилась, а стек не пуст. Очевидно, что для реализации такого стека массив
использовать не обязательно, достаточно хранить в некоторой переменной лишь
число открывающих скобок. При поступлении закрывающей скобки из этой переменной
вычитается 1. Ошибка возникает, если значение переменной стало отрицательным,
или при достижении конца строки оно не равно нулю. Для данных более сложного вида стек можно организовать с
помощью однонаправленного некольцевого списка. Чтобы положить элемент в стек,
нужно добавить его в начало списка, чтобы извлечь со стека –
получить данные первого элемента, после чего удалить его из списка. Любая реализация стека должна содержать следующие процедурыи
функции: procedure InitStack –
инициализация стека; procedure Push(d: tData) –
положить элемент в стек; procedure Pop(var d: tData) –
извлечь элемент с вершины стека; function NotEmpty: boolean –
проверка стека на пустоту; Очередь отличается
от стека тем, что последний пришедший в неё элемент будет извлечён последним, а
первый –
первым («FIFO»). С помощью списков её можно организовать
следующим образом: будем хранить не только указатель на «голову» списка, но и
на «хвост»; добавлять будем в «хвост», а извлекать – из
«головы». Любая реализация очереди (не обязательно с помощью списков)
должна «уметь» выполнять такие действия: procedure InitQueue –
инициализация очереди; procedure AddQueue(d: tData) –
поставить элемент в очередь; procedureSubQueue(var
d: tData) –
извлечь элемент из очереди; function NotEmpty: boolean –
проверка очереди на пустоту; ........... ..... Tree Data Data Data Data Data Data Data Деревьями называются структуры данных следующего вида: Элементы дерева называются вершинами. Вершина Tree^
называется корнем дерева, а
всё множество вершин, связанных с некоторой вершиной с помощью одного из
указателей называется поддеревом.
Вершины, у которых все указатели равны nil, иногда называют листьями. Подробнее мы рассмотрим вариант двоичного дерева, то есть такого, в котором каждая вершина имеет
два поддерева (любое из
них может оказаться пустым).
Такие деревья оказываются очень удобными для решения задачи поиска, когда ключи
для наших данных (например фамилии при поиске телефонных номеров) можно
сравнивать на "=", "<"и ">". В каждую вершину
дерева заносится элемент данных, причём делается это таким образом, чтобы для
любой вершины все ключи данных (или сами данные в простейшем случае) из левого
поддерева были меньше ключа этой вершины, а все ключи из правого –
больше. Выполнения такого требования можно достигнуть при последовательном
добавлении элементов (то есть построении дерева, начиная с «нуля», точнее с nil). При описанном построении дерева поиск оказывается довольно
простым делом: сначала
мы сравниваем искомый ключ с ключом корня дерева. Если эти два ключа совпадают,
то элемент найден, в противном случае выполняем поиск в левом поддереве, иначе –
в правом, далее в выбранном поддереве вновь выполняем сравнение его корня с
искомым ключом, и т. д. Этот процесс закончится либо когда мы нашли ключ, либо
когда очередное поддерево оказалось пустым (это означает, что такой ключ в
дереве отсутствует). Для реализации двоичного дерева сначала рассмотрим его
описание на Паскале: type tNodePtr = ^tNode; {указатель
на вершину} tNode = record data:
tMyData;
left,right: tNodePtr; end; tTree =
tNodePtr; {для
доступа к дереву достаточно хранить указатель на
его корень} Под данными (tMyData) будем понимать запись, состоящую из
ключа, необходимого для сравнений, и собственно данных: type tMyData = record key:
tKey; data:
tData; end; Для того чтобы реализовать действия с двоичным дерево, нам
понадобятся так называемые рекурсивные процедуры. Функция или процедура
называется рекурсивной, если она вызывает сама себя. Такой вариант
рекурсии называется прямым. Кроме
того, бывает и косвенная рекурсия,
когда одна процедура вызывает другую, а та в свою очередь вызывает первую. В качестве примера рассмотрим функцию для вычисления
факториала, в которой мы заменим цикл (или итерацию)
рекурсией. Её идея проста: если аргумент равен нулю, то возвращаем значение 1,
в противном случае возвращаем значениеаргумента, умноженное на факториал (то есть ту
же функцию) от числа, на единицу меньшего. На Паскале всё это будет выглядеть
следующим образом: function factorial(x: byte): longint; begin if x=0 then factorial:=1 else factorial:=x*factorial(x-1); end; Подобным образом можно применить рекурсию для вычисления n-го числа Фибоначчи, хотя
этот способ требует много лишних действий: function fib(n: integer): integer; begin if n<=1 then fib:=1 else
fib:=fib(n-1)+fib(n-2); end; Косвенная рекурсия может появиться, например при проверке
правильности арифметических выражений. Подробно рассматривать этот вопрос
сейчас мы не будем. Возвращаясь к деревьям, заметим, что добавление элемента
является рекурсивной процедурой: procedure InsertNode(t: tTree; key: tKey; data: tData); begin if t=nil then begin new(t);
t^.key:=key;
t^.data:=data; end else if key else InsertNode(t^.right,key,data); end; После того как дерево построено, можно выполнять поиск
(также рекурсивный): function Search(t: tree; key: tKey; var
data: tData): boolean; {возвращает
значение найден / не найден} begin if t=nil then Search:=false else if key = t^.key then begin
data:=t^.data;
Search:=true; end else if key else Search:=Search(t^.right,key,data); end; Легко заметить, что элементы данных, «уложенные» в двоичное
дерево можно выводить в отсортированном порядке: procedure Traversal(t: tTree); {обход
дерева} begin if t<>nil then begin
Traversal(t^.left);
writeln('Key:',t^.key,' Data:',t^.data);
Traversal(t^.right); end; end; Таблицей будем называть структуру данных, пригодную для
хранения набора данных, имеющих одинаковые типы. Простейшим примером такой
структуры может служить массив, поскольку тип всех его элементов один и тот же.
Чаще всего элемент таблицы состоит из нескольких частей, одна из которых имеет
наибольшее значение (называется ключом), а остальные содержат
информацию, связанную с этим ключом, или собственно данные. Если всё это
изобразить графически, то получится то, что называется таблицей в обычном
смысле: Ф.
И. О. Адрес Телефон Год
рождения Петров Ф. М. Северная 99-88 29-29-29 1962 Иванов П. С. Мира 111-222 77-88-99 1976 Козлов Н. В. Октябрьская 135-246 45-67-89 1970 ................. Здесь ключом является фамилия, а все остальные элементы —
полезная информация о человеке с такой фамилией. В случае, когда наша таблица
становится довольно большой, найти данные о нужном нам человеке становится
довольно сложно. Алгоритмы, предназначенные для поиска в таблице данных с
указанным ключом, называются алгоритмами поиска.Поиск
может быть удачным (если элемент с искомым ключом имеется в массиве) и неудачным
(в противном случае). При использовании языка Паскаль для работы с табличными
данными довольно удобно использовать записи в качестве элементов данных. В
нашем примере таблица будет состоять из элементов следующего типа: type tItem {элемент}= record
surname: string[30]; {фамилия, ключевое поле}
address: string; {адрес}
phone: longint; {телефон}
birth: word; {год
рождения} end; При рассмотрении алгоритмов поиска мы будем пользоваться
более общей формой для записи типа элемента: type tItem = record
key:tKey;{ключ} data:tData; {данные} end; Типы tKey и
tData зависят от
конкретной задачи, которую нужно решать. В нашем примере tKey — строка до 30 символов длиной, а tData можно сделать записью
из трёх полей (address, phone и
birth). Рассмотрим теперь некоторые способы реализации всей таблицы: Это наиболее простой вариант и довольно удобный, поскольку
положение элемента в таблице однозначно определяется номером элемента в
массиве. Если размер таблицы меняется в ходе работы с ней (данные время от
времени добавляются или удаляются), то массив оказывается не очень экономичным:
поскольку точное количество элементов заранее неизвестно, приходится заводить
массив из большого количества элементов, часть из которых не будет
использоваться, но будет занимать место в памяти. Для того чтобы хранить таблицу, нам потребуется запись из
двух полей: сам массив и целочисленное поле, обозначающее текущий размер
массива: const maxsize = 2000; {максимальный
размер таблицы} type tTable = record a: array[1..maxsize] of tItem; {это сам
массив} n:
integer;{а это - реальное число элементов} end; var Table: tTable; Предполагается, что в любой момент времени данные таблицы
хранятся в первых n
элементахмассива, а остальные считаются пустыми. Этот вариант более экономичен в плане расхода памяти, так
как всегда будет занято ровно столько места, сколько нужно под данные. В отличие
от массива, мы не можем легко просматривать данные произвольного элемента, для
перехода от одного элемента к другому нужно долго двигаться по цепочке указателей;
это является недостатком списка. Как выглядит такая таблица на Паскале нам уже известно: type tItemPtr = ^tItem; {указатель
на элемент списка} tItem = record {элемент списка}
key:tKey; data:
tData; next:
tItemPtr; end; tList:tItemPtr;{задаётся указателем на первый элемент} var Table: tList {таблица является списком} Как хранить и искать данные в двоичном дереве, мы уже знаем,
а таблицу можно задать так: type tItemPtr = ^tItem; {указатель на элемент} tItem = record {элемент}
key: tKey;
data: tData; left,
right: tItemPtr; end; tTree =
tItemPtr; var Table: tTree;{таблица является деревом} Пусть таблица представлена в виде массива. Тогда первое, что
приходит в голову по поводу поиска элемента — это обход всех элементов, начиная
с первого, до тех пор, пока не будет найден элемент с искомым ключом, или пока
массив не кончится. Такой способ называется линейным поиском в неупорядоченном
массиве. Оформим его на Паскале в виде процедуры: procedure LinearSearch(var
T:tTable; k:tKey; var
index:integer); var i: integer; begin i:=1;
index:=0; while (i<=T.n)and(index=0) do begin if T.a[i].key=k then index:=i; i:=i+1; end; end; Рассмотрим подробнее части этой процедуры. Параметрами
процедуры являются таблица (T),
в которой нужно искать элемент, искомое значение ключа (k) и выходной параметр (index), в котором процедура
должна указать номер элемента, если он найден, и 0 в противном случае. В списке
параметров таблица T
описана как параметр переменная, хотя процедура и не должна менять какие-либо
данные из таблицы. Это нужно для того, чтобы не создаватькопию таблицы в стеке при передаче параметра
процедуре, поскольку таблица может иметь большой размер. Возможен более рациональный вариант: вместо того чтобы
всякий раз проверять, не закончился ли массив, можно использовать массив с
фиктивным элементом номер 0, перед поиском записывать в него искомое значение
ключа, и двигаться по массиву от последнего элемента к первому. Такой способ
называется линейным поиском с барьером (барьер — нулевой элемент): procedure LinearSearch2(var
T:tTable; k:tKey; var
index:integer); var i: integer; begin T.a[0]:=k; index:=T.n;
index:=0; while T.a[index]<>k do index:=index-1; end; В таком варианте становится значительно меньше сравнений,
следовательно, алгоритм работает быстрее предыдущего. Следующий алгоритм также применяется для таблицы,
представленной в виде массива, кроме того, массив должен быть отсортированным
по значениям ключа (для определённости — по возрастанию). Тогда при поиске
можно использовать следующие соображения: возьмём элемент, находящийся в
середине массива, если его ключ равен искомому ключу, то мы нашли нужный
элемент, если меньше — продолжаем поиск в первой половине массива, если меньше
— то во второй. Под продолжением понимаем аналогичный процесс: вновь берём
средний элемент из выбранной половины массива, сравниваем его ключ с искомым
ключом, и т. д. Этот цикл закончится, когда часть массива, в которой
производится поиск, не будет содержать ни одного элемента. Так как этот
алгоритм многократно разбивает массив на две части, то он называется алгоритмом
двоичного поиска. Ниже приведена соответствующая процедура на Паскале. procedure BinarySearch(var
T:tTable; k:tKey; var
index:integer); var l,c,r: integer; begin index:=0; l:=1;
r:=T.n; while (index=0)and(l<=r) do begin c:=(l+r) div 2; if T.a[c].key=k then index:=c else if T.a[c].key>k then r:=c-1 else l:=c+1; end; end; Переменные l,r и c обозначают соответственно
номер левого края, центра и правого края части массива, в которой мы ищем
элемент с заданным ключом. Поиск прекращается либо если элемент найден (index <> 0), либо если
часть массива, в которой нужно искать, была исчерпана (то есть номер левого
края превысил номер правого). Внутри цикла находим номер середины части массива
(c), затем сравниваем
ключ этого среднего элемента с искомым ключом. Если выполнилось равенство, то
элемент найден, если средний больше искомого, то устанавливаем правую границу
части массива равной c-1,
если больше — меняем левую границу на c+1. Пусть теперь данные таблицы содержатся в списке. В этом
случае можно использовать для поиска алгоритм, очень похожий на алгоритм
линейного поиска в массиве. Отличие лишь в том, что изменение номера текущего
элемента заменяется переходом к указателю на следующий элемент списка: procedure SearchInList(T: tTable; k: tKey; var p: tItemPtr); var notfound: boolean; begin
notfound:=true; p:=T; while (p<>nil) and (notfound) do begin if p^.key=k then notfound:=false;
p:=p^.next; end; end; Параметр T в
этом случае не нужно делать параметром-переменной, поскольку он является только
указателем на начало таблицы, а сама таблица лежит в динамической памяти.
Вместо номера найденного элемента будем возвращать пользователю нашей процедуры
указатель на него (если поиск был удачным) или nil, если поиск неудачен. Сокращать число проверок в цикле с помощью барьера было бы
неразумно: каждый раз барьер придётся ставить в «хвост» списка, а для этого
нужно сначала обойти весь список, начиная с головы, затрачивая при этом много
времени. Наиболее очевидным способом хранения таблицы является
массив, в котором несколько первых элементов представляют собой полезные
данные, а остальные элементы считаются пустыми. Ниже будет рассмотрен другой
вариант применения массива для реализации таблицы. Позволим данным располагаться в любых элементах массива, а
не только в первых n. Чтобы отличать пустые элементы от занятых
нам понадобится специальное значение ключа, которое мы будем заносить в
ключевое поле всех пустых ячеек. Если ключ — число, а все полезные ключи
положительны,то можно в качестве ключа
пустой ячейки использовать 0, если ключи — строки, содержащие фамилии, то
ключом пустой ячейки можно сделать пустую строку и т. п. Пусть в ключами
являются строки, тогда для таблицы потребуются такие объявления: const empty = '';
nmax= 1000; type tKey = string;
tData= .....;
tItem= record
key:tKey;
data: tData;
end; tTable =
array[0..nmax-1] of tItem; Перед тем как помещать данные в массив заполним ключевые
поля всех его элементов «пустыми» значениями. Заносить в таблицу будем не все
данные сразу, а один за другим,по
очереди. Для того, чтобы определить номер ячейки массива, в которую нужно
поместить добавляемыйэлемент
данных,напишем функцию, значение
которой зависит только от ключа добавляемого элемента. В такой ситуации поиск
можно будет осуществлять довольно просто: находим значение функции на искомом
ключе, и смотрим на элемент массива с полученным номером. Если ключ элемента
равен искомому ключу, мы нашли то, что искали, иначе — поиск оказался
неудачным. Реализованная описанным способом таблица называется перемешанной (или hash-таблицей),
а функция — функцией расстановки
ключей (hash-функцией). Такие названия
связаны с тем, что данные беспорядочно разбросаны по массиву. Теперь покажем, как всё сказанное воплотить в программу на
Паскале. В качестве ключей в наших примерах используются строки, поэтому можно
предложить такой вариант хэш-функции: сложить коды всех символов строки, и,
чтобы полученное число не выходило за максимально возможный индекс массива,
возьмём остаток от деления на размер массива: function hash(key: tKey):integer; var i: integer; begin sum:=0; for i:=1 to length(key) do
sum:=sum+ord(key[i]); hash := sum
mod nmax; end; Процедура добавления элемента в таблицу в предварительном
варианте будет выглядеть так: procedure AddItem(var t: tTable;
item: tItem); var h: integer; begin
h:=hash(item.key);
t[h]:=item.key; end; У написанной процедуры есть один существенный недостаток:
если элемент, номер которого указала нам хэш-функция был занят, то новые данные
будут записаны на место старых, а старые бесследно исчезнут. Чтобы решить эту
проблему будем пытаться найти какой-либо другой свободный элемент для добавляемых
данных. Здесь понадобится ещё одна функция (вторичная хэш-функция), которая по
номеру занятого элемента и по значению ключа добавляемых данных укажет номер
другой ячейки, если и там будет занято, вызовем вторичную функцию ещё раз, и т.
д. до тех пор пока свободная ячейка не найдется. Наиболее простая хэш-функция будет добавлять к номеру занятой
ячейки какое-нибудь постоянное число: const HC = 7; function hash2(n: integer, key: tKey): integer; begin hash2 := (n
+ HC) mod nmax; end; Остаток от деления на nmax понадобилось вычислять по той же причине, что и в первичной
хэш-функции. Сейчас можно написать окончательный вариант процедуры
добавления элемента данных в таблицу: procedure AddItem(var t: tTable;
item: tItem); var h: integer; begin
h:=hash(item.key);
while t[h].key<>empty do
h:=hash2(h,item.key);
t[h].key:=item.key; t[h].data:=item.data; end; Пусть в хэш-таблицу занесены все необходимые данные и
требуется отыскать данные с некоторым ключом. Для этого будем действовать по
такой схеме: вычисляем значение хэш-функции на данном ключе, если ячейка с
полученным номером свободна, то элемент не найден, если занята, то сравниваем
её ключ с искомым. В случае совпадения мы нашли нужный элемент, иначе — находим
значение вторичной функции и смотрим на ключ в ячейке с полученным номером.
Если он равен «пустому» значению, то поиск неудачен, если равен искомому ключу
— то удачен, иначе — вновь находим значение вторичной хэш функции и т. д. На
Паскале всё это выглядит так: const notfound = -1;
continue = -2; procedure Search(var t: tTable;
key: tKey; var index: integer); var h: integer; begin
h:=hash(key);
index:=continue; repeat if t[h].key = key then index:=h else if t[h].key = empty then
index:= notfound else h:=hash2(h,key); until index<>сontinue; end; Процедура выдаёт ответ о результатах поиска через
параметр-переменную index.
При удачном поиске там будет лежать номер найденного элемента, при неудачном —
константа notfound.
Константа continue означает
«пока не найден» и используется только внутри процедуры. При поиске сначала
вычисляется значение первичной хэш-функции, а в index заносится значение continue Затем выполняется
проверка на равенство ключей, если оно выполняется, то ячейка массива найдена,
и мы записываем её номер вindex, иначе, если ячейка
пуста, то элемент не найден (в index
записываем notfound),
в третьем случае находим значение вторичной функции. Эти действия продолжаются
до тех пор, пока index не
перестанет быть равным continue. Лекция 8. Тип запись

Лекция 9. Процедуры и функции

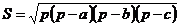 p
–
полупериметр треугольника, a,b,c
–
длины сторон.
p
–
полупериметр треугольника, a,b,c
–
длины сторон.Лекция 10. Модуль
CRT
1. Управление экраном
2. Работа с клавиатурой
3. Другие возможности
Лекция 11. Графика в Турбо Паскале
1. Включение и выключение графического
режима.
2. Построение элементарных изображений

3. Вывод текстовой информации.
Лекция 12. Текстовые файлы
1. Объявление файловой переменной и привязка к файлу на
диске
2. Чтение данных из файла
3. Запись данных в файл
Лекция 13. Двоичные файлы
1. Типизированные файлы
2. Нетипизированные файлы
Лекция 14. Модули в Турбо Паскале
Лекция 15. Динамические переменные
Динамические структуры данных


Лекция 16. Динамические переменные:
другие виды списков, стек и очередь.
1. Другие виды списков
2. Стек и очередь
Лекция 17. Деревья и поиск в деревьях

Лекция 18. Таблицы и простейшие
алгоритмы поиска.
1. Определения и описания структур
данных
1. Массив
2. Список
3. Дерево
2. Алгоритмы
1. Линейный поиск в массиве
2. Двоичный поиск
3. Линейный поиск в списке
Лекция 19. Перемешанные таблицы