ЛИСП
| Примечание | Методическое пособие |
| Загрузить архив: | |
| Файл: 240-1818.zip (132kb [zip], Скачиваний: 63) скачать |
Введение.
В последнее время особый интерес приобрела технология искусственного интеллекта (ИИ). Вычислительные устройства, обладающие в той или иной степени «интеллектуальными способностями, стали встраивать даже в бытовые приборы.
С развитием ИИ появилось большое количество специализированных языков программирования: Лисп, Пролог, Лого, Конивер и другие. Они постоянно развивались, оказывали взаимное влияние друг на друга, многие, не долго просуществовав, исчезали, но порождали идеи, которые давали новый толчок к мощному языкотворчеству в своей области.
Ведущее место среди языков ИИ занимает Лисп, а точнее, множество его диалектов. Длительное время не существовало стандарта этого языка. Но такое разнообразие не доставляло неприятностей, пока язык использовался лишь в исследованиях. Даже напротив, идеи Лиспа таким образом могли постоянно развиваться и поэтому в язык вошли новые, оказавшиеся полезными свойства, в том числе и из других языков. Однако недостатки, возникающие из-за несовместимости между диалектами становились все более существенными по мере роста числа практических приложений Лиспа.
В конечном счете стандарт языка был разработан. Им стал CommonLisp. Этот диалект содержит важнейшие черты современных Лисп-систем: разнообразные типы данных, возможности определения типов, управляющие структуры, макросы с помощью которых легко определяются новые синтаксические формы, функционалы, замыкания, последовательности, а также синтаксический интерпретатор и транслятор. Можно сказать, что CommonLisp содержит почти все, что на сегодняшний день могут дать другие известные языки программирования, и кроме того, он предусматривает средства для расширения.
Особенностям языка Лисп и посвящена данная дипломная работа, целью которой является разработка лабораторных работ по курсу «Системы искусственного интеллекта» для студентов специальности «Компьютерные и интеллектуальные системы и сети», а также расширение Лисп-библиотек для интегрированной среды dlisp.
В первой части дипломной работы проведен анализ языков программирования искусственного интеллекта. Особое место уделено анализу диалектов языка Лисп. В конце раздела подводятся итоги анализа и обосновывается выбор конкретного диалекта Лиспа и вырабатывается постановка задачи.
Вторая часть дипломной работы посвящена конкретно языку Лисп. Здесь рассматриваются общие особенности и понятия языка, присущие всем диалектам Лиспа.
Третья часть содержит комплекс лабораторных работ, включающий в себя тексты лабораторных работ, задания и контрольные вопросы, позволяющие оценить уровень знаний студента по каждой теме, а также примеры выполнения некоторых заданий.
В четвертый разделе дипломной работы затрагиваются вопросы техники безопасности, а точнее, вопросы инженерной психологии, применительно к отработке программ.
В заключении работы подводятся итоги проделанной работы.
1 Литературный обзор.
1.1 Краткая история развития искусственного интеллекта.
Искусственный интеллект (ИИ) - это область исследований, находящаяся на стыке наук, специалисты, работающие в этой области, пытаются понять, какое поведение, считается разумным (анализ), и создать работающие модели этого поведения (синтез). Практической целью является создание методов и техники, необходимой для программирования «разумности» и ее передачи вычислительным машинам (ВМ), а через них всевозможным системам и средствам.[1]
В 50-х годах исследователи в области ИИ пытались строить разумные машины, имитируя мозг. Эти попытки оказались безуспешными по причине полной непригодности как аппаратных так и программных средств.
В 60-х годах предпринимались попытки отыскать общие методы решения широкого класса задач, моделируя сложный процесс мышления. Разработка универсальных программ оказалась слишком трудным и бесплодным делом. Чем шире класс задач, которые может решать одна программа, тем беднее оказываются ее возможности при решении конкретной проблемы.[5]
В начале 70-х годов специалисты в области ИИ сосредоточили свое внимание на разработке методов и приемов программирования, пригодных для решения более специализированных задач: методов представления (способы формулирования проблемы для решения на средствах вычислительной техники (ВТ)) и методах поиска (способы управления ходом решения так, чтобы оно не требовало слишком большого объема памяти и времени).
И только в конце 70-х годов была принята принципиально новая концепция, которая заключается в том, что для создания интеллектуальной программы ее необходимо снабдить множеством высококачественных специальных знаний о некоторой предметной области. Развитие этого направления привело к созданию экспертных систем (ЭС).[6]
В 80-х годах ИИ пережил второе рождение. Были широко осознаны его большие потенциальные возможности как в исследованиях, так и в развитии производства. В рамках новой технологии появились первые коммерческие программные продукты. В это время стала развиваться область машинного обучения. До этих пор перенесение знаний специалиста-эксперта в машинную программу было утомительной и долгой процедурой. Создание систем, автоматически улучшающих и расширяющих свой запас эвристических (не формальных, основанных на интуитивных соображениях) правил - важнейший этап в последние годы. В начале десятилетия в различных странах были начаты крупнейшие в истории обработки данных национальные и международные исследовательские проекты, нацеленные на «интеллектуальные ВМ пятого поколения».[1]
Исследования по ИИ часто классифицируются, исходя из области их применения, а не на основе различных теорий и школ. В каждой из этих областей на протяжении десятков лет разрабатывались свои методы программирования, формализмы; каждой из них присущи свои традиции, которые могут заметно отличаться от традиций соседней области исследования. В настоящее время ИИ применяется в следующих областях:
n обработка естественного языка;
n экспертные системы (ЭС);
n символьные и алгебраические вычисления;
n доказательства и логическое программирование;
n программирование игр;
n обработка сигналов и распознавание образов;
n и др.
1.2 Языки программирования ИИ.
1.2.1 Классификация языков и стилей программирования.
Все языки программирования можно разделить на процедурные и декларативные языки. Подавляющее большинство используемых в настоящее время языков программирования (Си, Паскаль, Бейсик и т. п.) относятся к процедурным языкам. Наиболее существенными классами декларативных языков являются функциональные (Лисп, Лого, АПЛ и т. п.) и логические (Пролог, Плэнер, Конивер и др.) языки (рис.1).
На практике языки программирования не являются чисто процедурными, функциональными или логическими, а содержат в себе черты языков различных типов. На процедурном языке часто можно написать функциональную программу или ее часть и наоборот. Может точнее было бы вместо типа языка говорить о стиле или методе программирования. Естественно различные языки поддерживают разные стили в разной степени.[1]
Процедурная программа состоит из последовательности операторов и предложений, управляющих последовательностью их выполнения. Типичными операторами являются операторы присваивания и передачи управления, операторы ввода-вывода и специальные предложения для организации циклов. Из них можно составлять фрагменты программ и подпрограммы. В основе процедурного программирования лежат взятие значения какой-то переменной, совершение над ним действия и сохранения нового значения с помощью оператора присваивания, и так до тех пор пока не будет получено (и, возможно, напечатано) желаемое окончательное значение.[2]
 ЯЗЫКИ ПРОГРАММИРОВАНИЯ
ЯЗЫКИ ПРОГРАММИРОВАНИЯ
 |
 |
||

 ПРОЦЕДУРНЫЕ ЯЗЫКИ ДЕКЛАРАТИВНЫЕ ЯЗЫКИ
ПРОЦЕДУРНЫЕ ЯЗЫКИ ДЕКЛАРАТИВНЫЕ ЯЗЫКИ
 Паскаль, Си, Фортран,
...
Паскаль, Си, Фортран,
...
 |
 |
 ЛОГИЧЕСКИЕ ЯЗЫКИ ФУНКЦИОНАЛЬНЫЕ ЯЗЫКИ
ЛОГИЧЕСКИЕ ЯЗЫКИ ФУНКЦИОНАЛЬНЫЕ ЯЗЫКИ
Пролог, Mandala... Лисп, Лого, АРЛ, ...
Рис.1 Классификация языков программирования
Логическое программирование - это один из подходов к информатике, при котором в качестве языка высокого уровня используется логика предикатов первого порядка в форме фраз Хорна. Логика предикатов первого порядка - это универсальный абстрактный язык предназначенный для представления знаний и для решения задач. Его можно рассматривать как общую теорию отношений. Логическое программирование базируется на подмножестве логики предикатов первого порядка, при этом оно одинаково широко с ней по сфере охвата. Логическое программирование дает возможность программисту описывать ситуацию при помощи формул логики предикатов, а затем, для выполнения выводов из этих формул, применить автоматический решатель задач (т. е. некоторую процедуру). При использовании языка логического программирования основное внимание уделяется описанию структуры прикладной задачи, а не выработке предписаний компьютеру о том, что ему следует делать. Другие понятия информатики из таких областей, как теория реляционных баз данных, программная инженерия и представление знаний, также можно описать (и, следовательно, реализовать) с помощью логических программ.[8].
Функциональная программа состоит из совокупности определений функций. Функции, в свою очередь, представляют собой вызовы других функций и предложений, управляющих последовательностью вызовов. Вычисления начинаются с вызова некоторой функции, которая в свою очередь вызывает функции, входящие в ее определение и т. д. в соответствии с иерархией определений и структурой условных предложений. Функции часто либо прямо, либо опосредованно вызывают сами себя.[2]
Каждый вызов возвращает некоторое значение в вызывавшую его функцию, вычисление которой после этого продолжается; этот процесс повторяется до тех пор пока запустившая вычисления функция не вернет конечный результат пользователю.
«Чистое» функциональное программирование не признает присваиваний и передач управления. Разветвление вычислений основано на механизме обработки аргументов условного предложения. Повторные вычисления осуществляются через рекурсию, являющуюся основным средством функционального программирования.[1]
1.2.2 Сравнительные характеристики языков ИИ.
На первом этапе развития ИИ (в конце 50-х - начале 60-х годов) не существовало языков и систем, ориентированных специально на области знаний. Появившиеся к тому времени универсальные языки программирования казались подходящим инструментом для создания любых (в том числе и интеллектуальных ) систем, поскольку в этих языках можно выделить декларативную и процедурную компоненты. Казалось, что на этой базе могут быть интерпретированы любые модели и системы представления знаний. Но сложность и трудоемкость таких интерпретаций оказались настолько велики, что прикладные системы для реализации были недоступны. Исследования показали, что производительность труда программиста остается постоянной независимо от уровня инструментального языка, на котором он работает, а соотношение между длиной исходной и результирующей программ примерно 1:10. Таким образом, использование адекватного инструментального языка повышает производительность труда разработчика системы на порядок, и это при одноступенчатой трансляции. Языки предназначенные для программирования интеллектуальных систем содержат иерархические (многоуровневые) трансляторы и увеличивают производительность труда в 100-ни раз. Все это подтверждает важность использования адекватных инструментальных средств.[7]
1.2.2.1 Языки обработки символьной информации.
Лисп.
Язык Лисп был разработан в Стэнфорде под руководством Дж. Маккарти в начале 60-х годов. По первоначальным замыслам он должен был0 включать наряду со всеми возможностями Фортрана средства работы с матрицами, указателями и структурами из указателей и т. п. Но для такого проекта не хватило средств. Окончательно сформированные принципы положенные в основу языка Лисп: использование единого спискового представления для программ и данных; применение выражений для определения функций; скобочный синтаксис языка.[4]
Лисп является языком низкого уровня, его можно рассматривать как ассемблер, ориентированный на работу со списковыми структурами. Поэтому на протяжении всего существования языка было много попыток его усовершенствования за счет введения дополнительных базисных примитивов и управляющих структур. Но все эти изменения , как правило, не становились самостоятельными языками. В новых своих редакциях Лисп быстро усваивал все ценные изобретения своих конкурентов.[2]
После создания в начале 70-х годов мощных Лисп-систем Маклисп Интерлисп попытки создания языков ИИ, отличных от Лиспа, но на той же основе, сходят на нет. Дальнейшее развитие языка идет, с одной стороны, по пути его стандартизации (Стандарт-Лисп, Франц-Лисп, Коммон Лисп), а с другой - в направлении создания концептуально новых языков для представления и манипулирования знаниями в Лисп среде. В настоящее время Лисп реализован на всех классах ЭВМ, начиная с ПЭВМ и кончая высоко производительными вычислительными системами.
Лисп - не единственный язык, используемый для задач ИИ. Уже в середине 60-х годов разрабатывались языки, предлагающие другие концептуальные основы. Наиболее важные из них в области обработки символьной информации - СНОБОЛ и Рефал.
СНОБОЛ.
Это язык обработки строк, в рамках которого впервые появилась и была реализована в достаточно полной мере концепция поиска по образцу. Язык СНОБОЛ был одной из первых практических реализаций развитой продукционной системы. Наиболее известная и интересная версия этого языка - Снобол-4 Здесь техника задания образцов и работа с ними существенно опередили потребности практики. По существу, он так и остался «фирменным» языком программирования, хотя концепции СНОБОЛа, безусловно, оказали влияние и на Лисп, и на другие языки программирования задач ИИ.
Рефал.
Язык Рефал - алгоритмический язык рекурсивных функций. Он был создан Турчиным в качестве метаязыка, предназначенного для описания различных, в том числе и алгоритмических, языков и различных видов обработки таких языков. При этом имелось в виду и использование Рефалав качестве метаязыка над самим собой. Для пользователя это язык обработки символьной информации. Поэтому, помимо описания семантики алгоритмических языков, он нашел и другие применения. Это выполнение громоздких аналитических выкладок в теоретической физике и прикладной математике, интерпретация и компиляция языков программирования, доказательство теорем, моделирование целенаправленного поведения, а в последнее время и задачи ИИ. Общим для всех этих применений являются сложные преобразования над объектами, определенными в некоторых формализованных языках.
В основу языка Рефал положено понятие рекурсивной функции, определенной на множестве произвольных символьных выражений. Базовой структурой данных этого языка являются списки, но не односвязные, как в Лиспе, а двунаправленные. Обработка символов ближе к продукционной парадигме. Приэтом Активно используется концепция поиска по образцу, характерная для СНОБОЛа.
Программа написанная на Рефале, определяет некоторый набор функций, каждая из которых имеет один аргумент. Вызов функции заключается в функциональные скобки.
Во многих случаях возникает необходимость из программ, написанных на Рефале, вызывать программы, написанные на других языках. Это просто, так как с точки зрения Рефала первичные функции (Функции, описанные не на Рефале, но которые тем не менее можно вызывать из программ, написанных на этом языке.) - это просто некоторые функции, внешние по отношению к данной программе, поэтому, вызывая какую-либо функцию, можно даже и не знать, что это - первичная функция.
Семантика Рефал-программы описывается в терминах абстрактной Рефал-машины. Рефал-машина имеет поле памяти и поле зрения. В поле памяти Рефал-машиныпомещается программа, а в поле зрения - данные, которые будут обрабатываться с ее помощью, т. е. перед началом работы в поле памяти заносится описание набора функций, а в поле зрения - выражение, подлежащее обработке.
Часто бывает удобно разбить Рефал-программу на части, которые могут обрабатываться компилятором Рефала независимо друг от друга. Наименьшая часть Рефал-программы, которая может быть обработана компилятором независимо от других, называется модулем. Результат компиляции исходного модуля на Рефале представляет собой объектный модуль, который перед исполнением Рефал-программы должен быть объединен с другими модулями, полученными компиляцией с Рефала или других языков это объединение выполняется с помощью редактора связей и загрузчиков. Детали зависят от используемой ОС.
Таким образом, Рефал вобрал в себя лучшие черты наиболее интересных языков обработки символьной информации 60-х годов. В настоящее время язык Рефал используется для автоматизации построения трансляторов, систем аналитических преобразований, а также, подобно Лиспу, в качестве инструментальной среды для реализации языков представления знаний.[7]
Пролог.
В начале 70-х годов появился новый язык составивший конкуренцию Лиспу при реализации систем, ориентированных на знания - Пролог. Этот язык не дает новых сверхмощных средств программирования по сравнению с Лиспом, но поддерживает другую модель организации вычислений. Его привлекательность с практической точки зрения состоит в том, что, подобно тому, как Лисп скрыл от программиста устройство памяти ЭВМ, Пролог позволил ему не заботится о потоке управления в программе.[8]
Пролог - европейский язык, был разработан в Марсельском университете в 1971 году. Но популярность он стал приобретать только в начале 80-х годов. Это связано с двумя обстоятельствами: во-первых, был обоснован логический базис этого языка и, во-вторых, в японском проекте вычислительных систем пятого поколения он был выбран в качестве базового для одной из центральных компонент - машины вывода.
Язык Пролог базируется на ограниченном наборе механизмов, включающих в себя сопоставление образцов, древовидное представление структур данных и автоматический возврат. Пролог особенно хорошо приспособлен для решения задач, в которых фигурируют объекты и отношения между ними.[9]
Пролог обладает мощными средствами, позволяющими извлекать информацию из баз данных, причем методы поиска данных, используемые в нем, принципиально отличаются от традиционных. Мощь и гибкость баз данных Пролога, легкость их расширения и модификации делают этот язык очень удобным для коммерческих приложений.
Пролог успешно применяется в таких областях как: реляционные базы данных (язык особенно полезен при создании интерфейсов реляционных баз данных с пользователем); автоматическое решение задач; понимание естественного языка; реализация языков программирования; представление знаний; экспертные системы и др. задачи ИИ.[9]
Теоретической основой Пролога является исчисление предикатов. Прологу присущ ряд свойств, которыми не обладают традиционные языки программирования. К таким свойствам относятся механизм вывода с поиском и возвратом, встроенный механизм сопоставления с образцом. Пролог отличает единообразие программ и данных. Они являются лишь различными точками зрения на объекты Пролога. В языке отсутствуют указатели, операторы присваивания и безусловного перехода. Естественным методом программирования является рекурсия.
Пролог программа состоит из двух частей: базы данных (множество аксиом) и последовательности целевых утверждений, описывающих в совокупности отрицание доказываемой теоремы. Главное принципиальное отличие интерпретации программы на Прологе от процедуры доказательства теоремы в исчислении предикатов первого порядка состоит в том, что аксиомы в базе данных упорядочены и порядок их следования весьма существенен, так как на этом основан сам алгоритм, реализуемый Пролог-программы. Другое существенное ограничение Пролога в том, что в качестве логических аксиом используются формулы ограниченного класса - так называемые дизъюнкты Хорна. Однако при решении многих практических задач этого достаточно для адекватного представления знаний. Во фразах Хорна после единственного заключения следует ноль и более условий.
Поиск «полезных» для доказательства формул - комбинаторная задача и при увеличении числа аксиом число шагов вывода катастрофически быстро растет. Поэтому в реальных системах применяют всевозможные стратегии, ограничивающие слепой перебор. В языке Пролог реализована стратегия линейной резолюции, предлагающая использование на каждом шаге в качестве одной из сравниваемых формул отрицание теоремы или ее «потомка», а в качестве другой - одну из аксиом. При этом выбор той или иной аксиомы для сравнения может сразу или через несколько шагов завести в «тупик». Это принуждает вернуться к точке, в которой производился выбор, чтобы испытать новую альтернативу, и т. д. Порядок просмотра альтернативных аксиом не произволен - его задает программист, располагая аксиомы в базе данных в определенном порядке. Кроме того в Прологе предусмотрены достаточно удобные «встроенные» средства для запрещения возврата в ту или иную точку в зависимости от выполнения определенных условий. Таким образом процесс доказательства в Прологе более прост и целенаправлен чем в классическом методе резолюций.
Смысл программы языка Пролог может быть понят либо с позиций декларативного подхода, либо с позиций процедурного подхода.[8]
Декларативный смысл программы определяет, является ли данная цель истинной (достижимой) и, если да, при каких значениях переменных она достигается. Он подчеркивает статическое существование отношений. Порядок следования подцелей в правиле не влияет на декларативный смысл этого правила. Декларативная модель более близка к семантике логики предикатов, что делает Пролог эффективным языком для представления знаний. Однако в декларативной модели нельзя адекватно представить те фразы, в которых важен порядок следования подцелей. Для пояснения смысла фраз такого рода необходимо воспользоваться процедурной моделью.
При процедурной трактовке Пролог-программы определяются не только логические связи между головой предложения и целями в его теле, но еще и порядок, в котором эти цели обрабатываются. Но процедурная модель не годится для разъяснения смысла фраз, вызывающих побочные эффекты управления, такие как остановка выполнения запроса или удаление фразы из программы.[9]
Для решения реальных задач ИИ необходимы машины, скорость которых должна превышать скорость света, а это возможно лишь в параллельных системах. Поэтому последовательные реализации следует рассматривать как рабочие станции для создания программного обеспечения будущих высокопроизводительных параллельных систем, способных выполнять сотни миллионов логических выводов в секунду. В настоящее время существуют десятки моделей параллельного выполнения логических программ вообще и Пролог-программ в частности. Часто это модели, использующие традиционный подход к организации параллельных вычислений: множество параллельно работающих и взаимодействующих процессов. В последнее время значительное внимание уделяется и более современным схемам организации параллельных вычислений - потоковым моделям. В моделях параллельного выполнения рассматриваются традиционный Пролог и присущие ему источники параллельности.
На эффективности Пролога очень сильно сказываются ограниченность ресурсов по времени и пространству. Это связано с неприспособленностью традиционной архитектуры вычислительных машин для реализации прологовского способа выполнения программ, предусматривающего достижение целей из некоторого списка. Вызовет ли это трудности в практических приложениях, зависит от задачи. Фактор времени практически не имеет значения, если пролог-программа, запускаемая по несколько раз в день, занимает одну секунду, а соответствующая программа на другом языке - 0.1 секунды. Но разница в эффективности становится существенной, если эти две программы требуют 50 и 5 минут соответственно.
С другой стороны, во многих областях применения Пролога он может существенно сократить время разработки программ. Программы на Прологе легче писать, легче понимать и отлаживать, чем программы, написанные на традиционных языках, т. е. язык Пролог привлекателен своей простотой. Пролог-программу легко читать, что является фактором, способствующим повышению производительности при программировании и увеличению удобств при сопровождении программ. Поскольку Пролог основан на фразах Хорна, исходный текст Пролог-программ значительно менее подвержен влиянию машинно-зависимых особенностей, чем исходные тексты программ, написанных на других языках. Кроме того в различных версиях языка Пролог проявляется тенденция к единообразию, так что программу, написанную для одной версии, легко можно преобразовать в программу для другой версии этого языка. Кроме того Пролог прост в изучении.[8]
При выборе языка Пролог как базового языка программирования в японском проекте вычислительных систем пятого поколения в качестве одного из его недостатков отмечалось отсутствие развитой среды программирования и неприспособленность Пролога для создания больших программных систем. Сейчас ситуация несколько изменилась, хотя говорить о действительно ориентированной на логическое программирование среде преждевременно.
Среди языков, с появлением которых возникали новые представления о реализации интеллектуальных систем, необходимо выделить языки, ориентированные на программирование поисковых задач.
1.2.2.2 Языки программирования интеллектуальных решателей.
Группа языков, которые можно назвать языками интеллектуальных решателей, в основном ориентирована на такую подобласть ИИ, как решение проблем, для которой характерны, с одной стороны, достаточно простые и хорошо формализуемые модели задач, а с другой - усложненные методы поиска их решения. Поэтому основное внимание в этих языках было уделено введению мощных структур управления, а не способам представления знаний. Это такие языки как Плэнер, Конивер, КюА-4, КюЛисп.
Плэнер.
Этот язык дал толчок мощному языкотворчеству в области ИИ. Язык разработан в Массачуссетском технологическом институте в 1967-1971гг. Вначале это была надстройка над Лиспом, в таком виде язык реализован на Маклиспе под названием Микро Плэнер. В дальнейшем Плэнер был существенно расширен и превращен в самостоятельный язык. В СССР он реализован под названием Плэнер-БЭСМ и Плэнер-Эльбрус. Этот язык ввел в языки программирования много новых идей: автоматический поиск с возвратами, поиск данных по образцу, вызов процедур по образцу, дедуктивный метод и т. д.
В качестве своего подмножества Плэнер содержит практически весь Лисп (с некоторыми модификациями) и во многом сохраняет его специфические особенности. Структура данных (выражений, атомов и списков), синтаксис программ и правила их вычисления в Плэнере аналогичны лисповским. Для обработки данных в Плэнере в основном используются те же средства, что и в Лиспе: рекурсивные и блочные функции. Практически все встроенные функции Лиспа, в том числе и функция EVAL, включены в Плэнер. Аналогично определяются новые функции. Как и в Лиспе , с атомами могут быть связаны списки свойств.
Но между Лиспом и Плэнером существуют и различия. Отметим некоторые из них. В Лиспе при обращении к переменной указывается только ее имя, например Х, сам же атом как данное указывается как ‘X. В Плэнере используется обратная нотация: атомы обозначают самих себя, а при обращении к переменным перед их именем ставится префикс. При этом префикс указывает как должна быть использована переменная. Отличается от лисповского и синтаксис обращения к функциям, которое в Плэнере записывается в виде списка не с круглыми, а с квадратными скобками.
Для обработки данных в Плэнере используются не только функции, но и образцы и сопоставители.
Образцы описывают правила анализа и декомпозиции данных и поэтому их применение облегчает написание программ и сокращает их тексты.
Сопоставители определяются также, как функции, только их определяющее выражение начинается с ключевого слова, а в качестве тела указывается образец. Их выполнение заключается не в вычислении какого либо значения, а в проверке, обладает ли сопоставляемое с ним выражение определенным свойством.
Рассмотренное подмножество Плэнера можно использовать независимо от других его частей: оно представляет собой мощный язык программирования, удобный для реализации различных систем символьной обработки. Остальные части Плэнера ориентируют его на область ИИ, предоставляя средства для описания задач (исходных ситуаций, допустимых операций, целей), решения которых должна искать система ИИ, реализуемая на Плэнере, и средства, упрощающие реализацию процедур поиска решения этих задач.
На Плэнере можно программировать описывая то, что имеется и то что надо получить, без явного указания, как это делать. Ответственность же за поиск решения описываемой задачи берет на себя встроенный в язык дедуктивный механизм (механизм автоматического достижения целей), в основе которого лежит вызов теорем по образцу. Однако только вызова теорем по образцу не достаточно для такого механизма. Необходим механизм перебора, и такой механизм - режим возвратов - введен в язык.
Выполнение программы в режиме возвратов удобно для ее автора тем, что язык берет на себя ответственность за запоминание развилок и оставшихся в них альтернатив, за осуществление возвратов к ним и восстановления прежнего состояния программы - все это делается автоматически. Но такой автоматизм не всегда выгоден, так как в общем случае он ведет к «слепому» перебору. И может оказаться так, что при вызове теорем наиболее подходящая из них будет вызвана последней, хотя автор программы заранее знает о ее достоинствах. Учитывая это Плэнер предоставляет средства управления режимом возвратов.[7]
Конивер.
Язык Конивер был разработан в 1972 году, реализован как надстройка над языком Маклисп. Авторы языка Конивер выступили с критикой некоторых идей языка Плэнер. В основном она относилась к автоматическому режиму возвратов, который в общем случае ведет к неэффективным и неконтролируемым программам, особенно если она составляется неквалифицированными пользователями. Авторы Конивер отказались от автоматического режима возвратов, считая, что встраивать в язык какие-то фиксированные дисциплины управления (кроме простейших - циклов, рекурсий) не следует и что автор программы должен сам организовывать нужные ему дисциплины управления, а для этого язык должен открывать пользователю свою структуру управления и предоставлять средства работы с ней. Эта концепция была реализована в Конивер следующим образом.
При вызове процедуры в памяти отводится место, где хранится информация, необходимая для ее работы. Здесь, в частности, располагаются локальные переменные процедуры, указатели доступа (ссылка на процедуру, переменные которой доступны из данной) и возврата (ссылка на процедуру, которой надо вернуть управление). Обычно эта информация скрыта от пользователя, а в языке Конивер такой участок памяти (фрейм) открыт: пользователь может просматривать и менять содержимое фрейма. В языке фреймы представляют специальный тип данных, доступ к которым осуществляется по указателям.
Недостаток языка в том, что хотя пользователь и получает гибкие средства управления, одновременно на него ложится трудная и кропотливая работа, требующая высокой квалификации. Язык Конивер хорош не для реализации сложных систем, а как база, на основе которой квалифицированные программисты готовят нужные механизмы управления для других пользователей.
Учитывая сложность реализации дисциплин управления, авторы языка были вынуждены включить в него ряд фиксированных механизмов управления, аналогов процедур-развилок и теорем языка Плэнер. Но в отличии от Плэнера, где разрыв между выбором альтернативы в развилке и ее анализом, а в случае необходимости выработкой неуспеха может быть сколь угодно велик, в языке Конивер этот разрыв сведен к минимуму. Этим Конивер избавляется от негативных последствий глобальных возвратов по неуспеху, когда приходится отменять предыдущую работу чуть ли не всей программы.[7]
1.2.2.3 Языки представления знаний.
В рамках каждого базового языка ИИ явным образом выделяются и прямое его использование, и расширение за счет пакетов функций, и создание «автономного» языка представления знаний (ЯПЗ) с последующей интерпретацией или компиляцией программ на созданном языке. Но в последнем случае базовый язык, как правило, становится инструментальным средством для реализации ЯПЗ.
Независимо от реализации ЯПЗ должен отвечать следующим требованиям:
n наличие простых и вместе с тем достаточно мощных средств представления сложно структурированных и взаимосвязанных объектов;
n возможность отображения описаний объектов на разные виды памяти ЭВМ;
n наличие гибких средств управления выводом, учитывающих необходимость структурирования правил работы решателя;
n «прозрачность» системных механизмов для программиста, т. е. возможность их до определения и переопределения на уровне входного языка;
n возможность эффективной реализации, как программной, так и аппаратной;
Конечно, перечисленные требования во многом противоречивы. Но лишь тогда, когда в рамках разумного компромисса учтены все эти требования, создаются удачные ЯПЗ.
Среди ЯПЗ первого поколения (70-е годы) лишь некоторые сыграли заметную роль в программной поддержке систем представления знаний (СПЗ). Выделим среди них KRL, FRL, KL-ONE. Характерными чертами этих языков были: двухуровневое представление данных, представление закономерностей предметной области и связей между понятиями в виде присоединенных процедур, семантический подход к сопоставлению образцов и поиску по образцу.
KRL.
Один из самых интересных языков этой группы - KRL, в основу которого были положены следующие концепции: организация знаний в виде специально выделенных единиц с присоединенными описаниями и процедурами; наличие средств представления многоаспектного и/или неполного знания об объектах; возможность описания объектов через сопоставление их с другими объектами с учетом уточняющих описаний; наличие гибкого набора базовых средств описания стратегий вывода решений и возможность их динамического изменения. Однако KRL широко не использовался в интеллектуальных системах из-за некоторой его громоздкости и отсутствия собственных средств описания процедур. Как следствие, в KRL активно использовался Лисп. Часто нельзя было понять, имеем мы дело с KRL-программой и присоединенными Лисп-функциями или с Лисп-программой, в которой применяется KRL как способ представления данных.
FRL.
Язык FRL не самостоятельныйязык, а хорошо продуманная библиотечная система над Лиспом. В FRL не предлагается принципиально новых по сравнению с KRL концепций представления знаний, но тем не менее он оказался более удобным благодаря тщательному и экономному отбору базовых алгоритмических средств, а также более простому их синтаксическому оформлению. Здесь имеются развитые средства манипулирования иерархическими списками свойств объектов, включая механизмы наследования свойств и набор присоединенных к описаниям процедур.
Для всех ЯПЗ по сравнению с традиционными языками программирования характерна существенно большая «активность» данных, что приводит к стиранию граней между декларативной и процедурной компонентами. Кроме того, реальные объемы обрабатываемых данных требуют при реализации ЯПЗ использования концепции базы данных и методов, развитых при создании СУБД. И, наконец, ЯПЗ тяготеют больше к режиму интерпретации, чем к компиляции, характерной для реализации обычных языков программирования. В области разработки и реализации ЯПЗ можно выделить три круга проблем: определение входных языков СПЗ; выбор выходного языка соответствующего транслятора и собственно проблемы этапа трансляции.
Входной язык СПЗ должен быть близок к языку предметной области и по лексике, и по синтаксису, и по семантике.
От выбора выходного языка зависит не только эффективность, но и сама возможность реализации ЯПЗ. Выходной язык должен отвечать по крайней мере следующим требованиям: иметь достаточно большой набор примитивов работы с образцами; обладать встроенными средствами эффективной поддержки рекурсии; иметь гибкие средства описания потоков управления. Кроме того, в рамках выходного языка необходимы средства отображения данных на основную и внешнюю память и удобные средства работы с этими данными. И, наконец, желательно, чтобы в нем имелись достаточно развитые средства определения новых типов данных.
В настоящее время языков программирования, где имела бы место эффективная реализация всех указанных требований, пока нет. Поэтому выбор целевого языка ЯПЗ-транслятора всегда компромисс.
На данном этапе существует сотни языков и систем представления знаний. Поэтому рассмотрим лишь некоторые особенности нескольких ЯПЗ.
RLL.
Это фреймовый язык представления знаний (представитель популярного в 70-х годах подхода «фреймы до конца», является инструментальной средой для создания специализированных ЯПЗ.
Подобно другим инструментальным средствам, RLL содержит два слоя: базисные примитивы и средства их комбинирования на более высоком уровне, чем Лисп. При этом технология конструирования специальных ЯПЗ в рамках RLL-среды сводится, как правило, к редактированию уже существующих заготовок и последующему конвертированию их в Лисп.
Учитывая последовательную ориентацию RLL на концепцию фреймов, все структуры (декларативные и процедурные), более сложные чем список значений, описываются здесь в виде фрейм-подобных RLL-элементов.
С помощью RLL-элементов описываются понятия не только предметной области, но и самой RLL-среды (например, слот, механизм наследования, структура управления и т. д.). Заранее на уровне RLL-интерпретатора или конвертора фиксируется семантика ограниченного числа системных понятий - это множества, списки, слоты и др. RLL-элементы имеют явно специфицированные родовидовые отношения, которые также являются системными понятиями, и встроенный механизм описания отношений с помощью многосвязных списков.
В RLL имеется и библиотека удачных управляющих структур, и определенные средства конструирования из них решателей, необходимых для конкретной ЭС.
Одним из основных стандартных механизмов вывода решений в RLL является agenda (управляющий список с динамической коррекцией элементов).
ART.
Этот язык демонстрирует другую парадигму «фреймы плюс продукции», характерную для начала 80-х годов. Это не только язык представления знаний, но и определенное программное окружение, включающее редакторы, отладчики, трансляторы и модули управления.
Входной язык системы ART весьма гибкий и обеспечивает использование фактов, схем, комбинаций этих понятий и правил. Декларативную компоненту этого ЯПЗ составляют факты и схемы. По определению, факт включает три основных компонента: утверждение, значение истинности и точку зрения. С каждым утверждением может быть связано одно из трех значений истинности true, falseили unknown, а также определенные сферы его справедливости, которое и называется точкой зрения. Факты описываются экземплярами фреймов. Фреймы-прототипы в ART представляются схемами, каждая из которых описывает объекты и/или классы объектов с фиксированными свойствами. Механизмы наследования свойств при этом поддерживаются самой системой.
В целом язык ART погружен в Лисп-среду, так что синтаксически и фреймовые и продукционные структуры выражаются здесь как атомы, функции и списки языка Лисп. Такой подход в ART естественен, так как первоначально был реализован на Лисп-машинах. Средства описания фактов в языке ART почти полностью «отданы на откуп» Лиспу, что снижает концептуальную целостность языка , так как средства описания схем и правил здесь хотя и похожи на лисповские, но свои. В ART пользователю дается небольшой набор встроенных стратегий вывода решений и весьма ограниченный выбор из ART-действий, взаимодействующих с модулем вывода. Но в системе имеется возможность выхода в базовый язык Лисп, где программируются любые управляющие стратегии.
В полном объеме ART представляет разработчику ЭС достаточно мощные средства представления знаний, но эффективно в системе ART могут работать только квалифицированные Лисп-программисты, готовые реализовать в этом языке все процедуры поддержки ЯПЗ.
Дальнейшее развитие ЯПЗ смещается в сторону продукций. Вместе с тем в настоящее время уже редко удается классифицировать языки и системы представления знаний на шкале «фреймы - продукции - семантические сети - ...» однозначно. И хотя тот или иной формализм представления знаний накладывает в большей или меньшей степени свой отпечаток на соответствующий ЯПЗ, современные языки и системы, как правило, поддерживают несколько формализмов одновременно.
1.3 Особенности диалектов языка Лисп.
1.3.1 Диалекты Лиспа.
Маклисп.
Кроме символьной обработки Маклисп широко использовался в традиционных числовых вычислениях, применяемых , например, в обработке речи и изображений. Кроме исследователей ИИ и разработчиков алгебраической системы Максима на Маклисп оказали влияние и работы групп в МИТ по робототехнике, обработке речи и изображений. Исходя из требований, предъявляемых этими областями, в Маклисп были включены новые математические типы данных, такие как матричная и битовая обработка, а также широкий набор арифметических функций и средств. Быть может, важнейшая из них - возможность вычислений с неограниченной точностью, основывающаяся на созданных Кнутом (1969) алгоритмах.[2]
Маклисп был также первой Лисп-системой для которой создан хороший транслятор. Транслятор генерирует машинную программу в форме списков. Машинный код в виде списка легко обрабатывать и результирующий код для числовых задач получался эффективнее, чем у лучших фортрановских трансляторов.
Однако большую часть своих свойств Маклисп приобрел под влиянием стоящих перед исследователями ИИ проблем и накопленного опыта. Так в язык попали макросы чтения и таблицы чтения, позволяющие легко изменять и расширять структуру языка. Таким же образом из требований к программам и окружению возникли управляющие структуры, механизмы обработки прерываний и ошибок, а также использование управляющих символов, создан и интегрирован в систему экранный редактор, появились управление и взаимодействие параллельных процессов.
Основное внимание разработчики Маклиспа сосредоточили на эффективности. Этому служат указания, уточняющие способы обработки аргументов функций, а также экранирование от вмешательства программиста внутренних механизмов системы. За счет этих мер скорость работы Маклиспа в 1.5-2.5 раза выше, чем Интерлисп.[7]
Всего в Маклиспе используется около 400 функций. Самым большим недостатком системы является то, что ее никогда не документировали должным образом. Документация по этой системе разбросана по различным отчетам и руководствам. Маклисп был исследовательской системой и не предназначался для обучения и промышленного использования.[2]
муЛисп.
Интерпретатор Мулисп-85, разработанный для ПЭВМ серии IBMPC - удачный вариант реализации диалекта языка, включающий сравнительно ограниченный набор базовых функций (около 260) и оказавшийся в следствие этого более простым для изучения.
По сравнению с Коммон Лиспом диалект муЛисп не имеет такого широкого спектра доступных типов данных. В нем обеспечивается работа только с двумя типами числовой информации: целыми числами с любым основанием и рациональными. В диалекте отсутствуют средства работы со структурами, массивами, потоками и другими типами данных, указанная реализация языка Лисп имеет одно существенное преимущество - возможность пополнения базового набора функций путем подключения подпрограмм, написанных на языке ассемблера, что позволило повысить гибкость использования интерпретатора и эффективность прикладного программного обеспечения, создаваемого на его основе. Возможность такого пополнения отсутствует в большинстве других Лисп-систем, являющихся в этом смысле замкнутыми программными продуктами.
Среди других, вероятно, менее существенных, особенностей системы можно указать на реализацию специального механизма, позволяющего не заботиться о присваивании начальных значений литеральным атомам, получающих изначальное значение, равное «печатному» имени самого атома. Еще одной особенностью диалекта является возможность использования новой синтаксической конструкции «встроенный COND», существенно сокращающей тексты описаний функций пользователя и применяемой при записи тел функций и лямбда-выражений.[7]
Набор базовых функций муЛисп-интерпретатора включает ряд функций, обеспечивающих доступ практически ко всем функциям ОС ЭВМ через соответствующие прерывания. Наконец, указанная Лисп-сис-тема обеспечивается библиотеками Лисп-функций, дополняющими базовый набор функциями, имеющимися в диалектах Коммон Лисп и Интерлисп, что облегчает решение проблемы переносимости исходных текстов программных модулей, а также библиотеками, позволяющими выполнять манипулирование окнами на экране дисплея и обрабатывать управляющие воздействия через устройство типа «мышь». В комплект дополнительного программного обеспечения к интерпретатору входят интерактивный редактор текстов и простая обучающая система, написанные на диалекте языка муЛисп.[7]
Интерлисп.
Интерлисп появился в 1972 году из ББН-Лиспа. К 1978 году, когда вышло описание Интерлиспа, язык и система уже достаточно стабилизировались. Интерлисп уже не был языком в том же смысле, что и Маклисп или другие Лисп-системы или обычные традиционные системы программирования. Он представлял собой интегрированную среду программирования, в которую вошло множество различных вспомогательных средств. Интерлисп стал классическим примером хорошо развитых программных средств и средств в системах разделения времени.[2]
Этот диалект наряду с Коммон Лиспом один из наиболее распространенных, имеет достаточно развитый аппарат представления и манипулирования различными структурами данных, включая массивы. Среди общих особенностей данного варианта языка следует отметить использование для обозначения встроенных функций нетрадиционных имен, что порой затрудняет перенос готовых программных продуктов на другие диалекты и другие ЭВМ.[7]
В 1974 году Xeroxначала разработку для Интерлиспа персональной лисповской рабочей станции под названием Alto. В реализации Лиспа для Alto впервые применили спроектированную специально для языка Лисп микропрограммируемую систему команд и мини-ЭВМ, способную с более высокой производительностью, чем универсальные ЭВМ, интерпретировать лисповские программы. Из этой машины Alto впоследствии развились Лисп-машины серии 1100 фирмы Xerox.
На основе версии Интерлиспа, работавшей в системе разделения времени, была создана совместимая снизу вверх версия Лиспа Интерлисп-де, используемая на Лисп-машинах серии 1100. В ее пользовательский интерфейс входили многооконное взаимодействие, графика с высокой разрешающей способностью, средства выбора из меню и мышь, а также ориентированный на использование экрана инспектор структур данных. Идея разделения экрана на многие независимые окна родилась в XLG. Алан Кэй уже в конце 60-х годов предложил такую идею подхода к компьютерам будущего и интерфейсу между человеком и машиной. Работа XLG привела к созданию в 70-х годах к разработке языка программирования Smolltalk и объектного программирования.
При создании Интерлиспа работа велась весьма тщательно. Система хорошо документирована и более новые версии совместимы с более ранними. Так преимуществом системы стало непрерывно пополняющееся большое количество переносимого программного обеспечения. С другой стороны, ограничение системы старым зафиксированным уже в конце 70-х годов диалектом сделало систему отчасти устаревшей и трудно расширяемой. В Интерлиспе среди прочего отсутствуют иерархические типы данных, объекты и замыкания. К тому же он базируется на динамическом связывании, тогда как новые версии Лиспа - статические. Однако из Интерлиспа берет начало новая версия - Коммон Лисп (1986). Для программирования на более высоком уровне в Интерлисп разработаны такие средства, в которых уже присутствовали объекты.
Интерлисп - столь замкнутая система, что доступна только ее оттранслированная версия в машинных кодах. В некоторых других системах, таких как, например Зеталисп, поддерживается версия Лиспа на исходном языке, которая доступна пользователю и может модифицироваться им. Развитие закрытых систем, похожих на Интерлисп, связано с ресурсами, имеющимся у создавших их лабораторий.
Интерлисп использует свыше 500 функций и большое количество системных имен и флажков, с помощью которых можно настроить и подогнать систему. Интерлисп реализован в системе разделения времени на многих больших ЭВМ.
В Интерлиспе основное внимание было уделено удобству системы для пользователя. Главный принцип разработчиков этого диалекта: все, что может иметь место в системе, должно естественно выражаться в терминах ее входного языка. Поэтому в Интерлисп программисту доступно все. Он может переопределять любые, в том числе и встроенные, функции; задавать и переопределять реакции на ошибки; работать непосредственно с уровня входного языка с внутренними структурами интерпретатора и т. д. При этом система поддерживает свою целостность и работоспособность.[7]
Франс Лисп.
Маклисп стал основой для многих новых диалектов языка Лисп, первым из которых был Франс Лисп. Эта версия Лиспа названа в честь известного венгерского композитора. Главным мотивом разработки Франс Лисп было желание получить современную Лисп-систему для новых машин VAX, чтобы на них можно было использовать систему Максима и другое лисповское программное обеспечение. Франс Лисп в довольно большой степени напоминает Маклисп, на котором первоначально была реализована Максима. Однако в диалекте отсутствуют некоторые устаревшие особенности Маклиспа и содержатся более новые системные идеи, заимствованные в то время в MIT Лисп-машин для Зеталиспа.
Новый диалект был реализован в университете в Беркли на ЭВМ VAX 780/11 на языке Си под управлением системы UNIX. Франс Лисп довольно широко используется как под управлением UNIX, так и под управлением VAX/VMS и в настоящее время является наиболее часто используемой версией Лиспа для систем разделения времени. Кроме того, он широко используется и на 32-битовых микро-ЭВМ и рабочих станциях, работающих под управлением UNIX.
Благодаря своей хорошей переносимости Франс Лисп получил распространение во многих университетах и исследовательских учреждениях. Сопровождение системы также разошлось в различных исправлениях системных ошибок, реализациях наиболее эффективных алгоритмов, а также в расширениях языка.
Зеталисп Лисп-машин.
Зеталисп также опирается на Маклисп. Он создан в 70-е годы в MIT в рамках проекта Лисп-машины, финансированного оборонным агентством. С самого начала его целью было изготовление коммерческого продукта. В 1979 году в связи с проектом родились два предприятия изготавливающие Лисп-машины: SymbolicInc. и LispMachineInc. (LMI). После этого в 80-е годы работа по развитию Зета Лиспа продолжалась в них независимо друг от друга на коммерческой основе. В какой-то мере системы отличаются друг от друга, но в части Зета Лиспа машины почти совместимы.[2]
Зета Лисп содержит следующие развитые механизмы и черты:
n широкий выбор типов данных;
n возможность объектно-ориентированного программирования в системе Flavor;
n современные управляющие структуры, динамические механизмы передачи управления сопрограммы и процессы;
n гибкий механизм ключевых слов в лямбда-списке и многозначные функции;
n ввод и вывод основывающийся на потоках;
nпространства имен;
n уже готовые функции, в том числе для сортировки, работы с линейными управлениями и матричные вычисления.
Выбор используемых в среде Зеталиспа инструментов и языков программирования зависит от поставщика, причем предлагаемый набор средств все время расширяется. Среди других языков предлагаются Фортран, Паскаль, Ада и Пролог. Для этих языков в среде Зеталиспа существуют особенно развитые программные окружения, и разработанные в них программы можно выполнять вместе с программами на Лиспе.
Готовые инструменты и прикладные разработки в большом количестве имеются для работы с ЭС, с естественным языком и речью, с реляционными базами данных, машинной графики и машинного проектирования.[2]
Коммон Лисп.
Этот диалект отличается наиболее широким представлением различных структур данных и включает около 800 встроенных функций. В этом диалекте обеспечиваются средства обработки основных классов числовой информации: целых, вещественных и комплексных. Символьные данные (литеры, литеральные атомы, строки) в Коммон Лиспе соответствуют основным возможностям других Лисп-систем. Дополнительно имеются средства обработки непечатных литер в символьных именах.
Одним из существенных преимуществ диалекта Коммон Лисп является наличие средств обработки массивов и структур, по своим возможностям не уступающих соответствующим средствам традиционных языков программирования (Фортран, Паскаль). Массивы в Коммон Лиспе могут иметь любое неотрицательное число измерений и индексируются последовательностью целых чисел. Тип компонентов массива может быть произвольным. Выделяется подкласс векторов - одномерных массивов, среди которых отдельно рассматриваются строки и битовые массивы.
Структуры Коммон Лиспа являются типом многокомпонентных записей, определяемых пользователем и имеющих именованные компоненты. Встроенное макроопределение DEFSTRUCT используется для определения структур новых типов. Для создания данных нового типа в виде структуры предусмотрены средства автоматической генерации набора функций, обеспечивающих средства манипулирования объектами этого класса.[1]
Удобным средством контроля доступа к различным переменным и функциям Лисп-программ в Коммон-Лиспе являются пакеты. Пакет - множество имен объектов, определенных и доступных в нем. Внутри пакета имена объектов подразделяются на внутренние и внешние. Первые предназначены для использования только внутри данного пакета, а вторые - для обеспечения связи с другими пакетами. Лисп-интерпретатор представляет широкий спектр средств манипулирования с пакетами. Как правило, Лисп-система имеет в своем составе четыре стандартных пакета: lisp (содержащий примитивы системы), user(умалчиваемый пакет прикладных программ и данных пользователя), keyword (содержащий ключевые слова всех встроенных функций и функций, определяемых пользователем), system (зарезервированный для системных целей).
Значительной переработке и расширению в Коммон Лиспе подверглись средства ввода-вывода и передачи информации. Для эффективной организации различных обменов с внешней средой введена концепция потоков, позволяющих осуществлять одно- и (или) двухстороннюю передачу информации. Для потоков предусмотрен набор базовых функций. В диалекте различают символьные и двоичные потоки. В первом случае передача осуществляется по байтам, а во втором - целыми числами. Кроме стандартных потоков пользователь имеет возможность создавать и использовать собственные потоки.[2]
В дополнение к указанным типам данных Коммон Лисп имеет ряд специфических классов объектов: хэш-таблицы, обеспечивающие эффективный способ доступа к данным по ключу; READ-таблицы, обеспечивающие управление обработкой информации поступающей из входного потока Лисп-системы, и некоторые другие. Такое множество имеющихся в диалекте различных типов данных, с одной стороны, развеивает существующее ошибочное представление о языке Лисп как о средстве обработки только символьной информации, а с другой - наличие мощных средств манипулирования типами данных существенно усложняет его.[7]
Этот диалект оставлен открыт: принципиальным является то, что осталась возможность в будущем, когда подойдет время и будет достигнуто согласие, добавить новые средства и методы. Эта идея как раз соответствует духу Лиспа.
Коммон Лисп не является готовой программной системой в том же смысле, что и Интерлисп, поскольку вопросы среды в основном оставлены открытыми. В стандарте не определено, каким должен быть редактор или другие вспомогательные средства. Сказано лишь в самом общем виде, каким образом они вызываются. Для того чтобы обеспечить быстрое развитие, среда и инструментальные средства еще не затронуты стандартизацией, и поэтому есть возможность создавать различные среды для различных целей. Коммон Лисп не определяет также и интерфейс пользователя.
В Коммон Лисп на современном этапе не включены даже средства объектного программирования, хотя и определены необходимые для этого базовые механизмы (замыкание и др.). Таким образом, объекты можно реализовать на Лиспе. Но уже ведется работа по стандартизации средств и форм объектного программирования.
В Коммон Лиспе много внимания уделено практическим требованиям, и, вероятно, поэтому не все его черты эстетичны и чисты. Несомненно, что и другие Лисп-системы будут использоваться в дальнейшем, и их также необходимо развивать.
Коммон Лисп предназначен не только для работы со списками или для символьной обработки, он является универсальным языком программирования, включающим в себя особенно хорошие средства для численных вычислений, управления данными и связи. На Коммон Лиспе можно с одинаковым успехом писать программы в традиционных операторном, процедурном, фразовом стиле, а также и в свойственных Лиспу стилях. В языке содержатся предпосылки для использования различных способов и стилей программирования, таких как операторное, функциональное, макропрограммирование, программирование, управляемое данными, и продукционное программирование, а также средства, необходимые для логического и объектного программирования и реализации других средств более высокого уровня.[1]
Можно смело сказать, что Коммон Лисп содержит почти все, что на сегодняшний день могут дать другие известные языки программирования, и, кроме того, он предусматривает средства для расширения языка.
1.3.2 Лисп-машины.
С наступлением 70-х годов большие системы ИИ и алгебраические системы натолкнулись на ограничения памяти и эффективности, существующие и на больших универсальных ЭВМ. Восемнадцатибитовое поле адреса широко используемых машин PDP-10/20 стало серьезным ограничением, к тому же исследователи ИИ не могли работать в системе разделения времени в дневное время из-за большой нагрузки на машины. Из этих проблем родилась идея об отдельной Лисп-машине и о маневре, который известен под названием «бегство из разделения времени». На это направление повлияло также и быстрое развитие микро-электронники в 70-х годах, сделавшее возможным проектирование и производство ориентированных на язык процессоров и персональных ЭВМ.
Первый отчет, связанный с Лисп-машинами, появился в серии изданий лаборатории ИИ MIT в 1974 году, а интегральная схема LSI была изготовлена в 1978 году. Первые промышленные Лисп-машины появились на рынке несколько лет спустя.
Часть идей, касающихся Лисп-машин, зародилась в Исследовательском центре PaloAlto фирмы Xerox и была результатом пионерских разработок в области обработки данных на персональных ЭВМ и экранно-ориентированных человеко-машинных интерфейсов. Это были объектно-ориентированный подход, а также специальные интегрированные в среду средства и методы программирования, созданные фирмами Xerox и BBN в ходе работы над Интерлиспом.[2]
Цельюпроектирования Лисп-машин была разработка их в виде персональных ЭВМ, которые можно было бы использовать не только для профессиональных исследований в области ИИ, но и для различных промышленных и коммерческих приложений. Разработке и их распространению помешала необходимость переноса программного обеспечения большого объема из дорогой среды больших машин.
По производительности оборудования Лисп-машины очень эффективны, кроме того, они имеют большой объем основной памяти. Их аппаратура спроектирована специально для вычислений на Лиспе. С точки зрения эффективности одной из наиболее важных особенностей является проверка типов на уровне аппаратуры, используемая в системах, происходящих из MIT.
Однако наиболее существенным преимуществом такой аппаратуры является возможность использования на Лисп-машине интегрированной программной среды. В ней наряду с самим Лиспом содержатся разнообразные программные средства. Программное обеспечение использует тысячи функций. Во многих системах помимо Лиспа доступны и другие языки (Паскаль, Ада, Си, Пролог и др.). Так, в систему можно добавить реализованные ранее на других языках части или сделать традиционное программирование более эффективным с помощью разнообразнейших средств, имеющихся на Лисп-машине.
Создание Лисп-машин дало новый толчок развитию Лиспа. Кроме высокого быстродействия (первая же Лисп-машина работала в несколько раз быстрее, чем Маклисп) и огромной виртуальной списковой памяти, достоинством Лисп-машин является и то, что для них это единственный язык программирования. На нем написаны все системные программы, начиная с ОС и кончая всевозможными препроцессорами, и программы пользователя. Такая однородность значительно упрощает как разработку самих системных компонентов, так и взаимодействие с ними. По сути дела, на Лисп-машинах стирается грань между системным и прикладным программным обеспечением. В настоящее время Лисп-машины выпускаются рядом фирм США, Японии и Западной Европы. В бывших социалистических странах также имеются положительные примеры разработки таких машин.[7]
1.3.3 Выводы.
Современные диалекты языка Лисп можно
рассматривать как мощные интерактивные системы программирования. Это
объясняется двумя причинами. Во-первых, сам язык Лисп претерпевает серьезные
изменения - развиваются средства языка, предназначенные для обработки
нетрадиционных для Лиспа типов данных: массивов, векторов, матриц; появляются
некоторые средства управления памятью (пакеты), отсутствующие в Лиспе.
Серьезные изменения претерпевают и управляющие структуры. Появились
несвойственные природе языка Лисп функции, заимствованные из Фортрана, Алгола,
Паскаля, Си: Do,
Для ПЭВМ ограничения по памяти и быстродействию все еще остаются существенными. Однако положение не безнадежно. Развитие Лисп-систем для ПЭВМ идет сегодня по трем различным направлениям. Первое связано с увеличением емкости памяти, которая может использоваться Лисп-системой. С этой целью ряд компаний разработал версии языка GoldenCommonLisp, использующие расширения оперативной памяти и виртуальную память. Второе направление связанно с повышением быстродействия Лисп-систем. Третье направление состоит в разработке эффективных компиляторов программ с языка Лисп в традиционные языки (чаще всего в язык Си).
Положительным нововведением в современные диалекты языка можно считать псевдоассемблерные команды, которые позволяют оперировать основными регистрами машины и организовывать прерывания на уровне DOS иBIOS. Кроме того, многие Лисп-системы имеют хорошие интерфейсы с другими языками (Фортран, Паскаль, Ассемблер, Си), что позволяет повысить эффективность прикладных Лисп-программ.
Если же говорить о глобальной тенденции развития самой идеологии языка Лисп, то очевидно, что она связана с созданием объектно-ориентированных версий языка как наиболее пригодных для реализации систем ИИ.
Анализ существующих языков обработки символьной информации, использование их для реализации интеллектуальных систем, а также сравнение тенденций развития этих языков позволяют сделать несколько замечаний.
1. Можно предположить, что Лисп еще значительное время будет оставаться основным языком для реализации интеллектуальных систем.
2. Уже в ближайшее время можно ожидать появления языков, вобравших в себя лучшие черты Лиспа и др. языковпрограммирования ИИ.
3. Наблюдается явная тенденция к созданию параллельных версий языков для программирования задач ИИ. Языки типа Лисп, Пролог, Рефал (а также всевозможные модификации и «смеси» этих и/или других языков символьной обработки) будут все больше уступать свои позиции на уровне инженеров по знаниям специальным языкам представления знаний, оставаясь инструментарием системных программистов.
На основании анализа сравнительных характеристик для изучения языка Лисп в курсе лабораторных работ по предмету «Системы искуственного интеллекта»был выбран диалект муЛисп. Выбор этого диалекта основан на следующих его особенностях:
1. Простота в изучении (благодаря небольшому набору базовых функций).
2. Близость к стандарту языка.
3. Возможность пополнения базового набора функций.
4. Дополнительные библиотеки Лисп-функций, расширяющие базовый набор функций, имеющимися в диалектах Коммон Лисп и Интерлисп, а также библиотеками, позволяющими выполнять манипулирование окнами на экране дисплея и работать с устройством «мышь».
5. Дополнительное программное обеспечение к интерпретатору: интерактивный редактор текстов и простая обучающая система.
2. Теоретическая часть.
2.1 Основные особенности языка Лисп.
От других языков программирования Лисп отличается следующими свойствами:
1.одинаковая форма данных и программ;
2.хранение данных, не зависящее от места;
3.автоматическое и динамическое управление памятью;
4.функциональная направленность;
5.Лисп - бестиповый язык;
6.интерпретирующий и компилирующий режимы работы;
7.пошаговое программирование;
8.единый системный и прикладной язык программирования.
Теперь рассмотрим эти свойства более подробно.
Одинаковая форма данных и программ.
В Лиспе формы представления программы и обрабатываемых ею данных одинаковы. И то и другое представляется списочной структурой, имеющей одинаковую форму. Таким образом программы могут обрабатывать и преобразовывать другие программы и даже самих себя. В процессе трансляции можно введенное и сформированное в результате вычислений выражение данных проинтерпретировать в качестве программы и непосредственно выполнить. Это свойство обладает не только теоретическим, но и большим практическим значением.
Универсальный единообразный и простой лисповский синтаксис списка не зависит от применения, и с его помощью легко определять новые формы записи, представления и абстракции. Даже сама структура языка является, таким образом, расширяемой и может быть заново определена. В то же время достаточно просто написание интерпретаторов, компиляторов, редакторов и других средств. К Лиспу необходимо подходить как к языку, с помощью которого реализуются специализированные языки, ориентированные на приложение, и создается окружение более высокого уровня. Присущая Лиспу расширяемость не встречается в традиционных замкнутых языках программирования.
Хранение данных не зависящее от места.
Списки, представляющие программы и данные, состоят из списочных ячеек, расположение и порядок которых в памяти не существенны. Структура списка определяется логически на основе имен символов и указателей. Добавление новых элементов в список или удаление из списка может производиться без переноса списка в другие ячейки памяти. Резервирование о освобождение могут в зависимости от потребности осуществляться динамически, ячейка за ячейкой.
Автоматическое и динамическое управление памятью.
Пользователь не должен заботиться об учете памяти. Система резервирует и освобождает память автоматически в соответствии с потребностью. Когда память кончается, запускается специальный мусорщик. Мусорщик перебирает все ячейки и собирает являющиеся мусором ячейки в список свободной памяти для того, чтобы их можно было использовать заново. Cреда Лиспа постоянно содержится в порядке В современных Лисп-системах выполнение операции сборки мусора занимает от одной до нескольких секунд. В задачах большого объема сборщик мусора запускается весьма часто, что резко ухудшает временные характеристики прикладных программ. Во многих системах мусор не образуется, поскольку он сразу же учитывается. Управление памятью просто и не зависит от физического расположения, поскольку свободная память логически состоит из цепочки списочных ячеек.
В первую очередь данные обрабатываются в оперативной и виртуальной памяти, которая может быть довольно большой. Файлы используются в основном для хранения программ и данных в промежутках между сеансами
.
Функциональная направленность Лиспа.
Функциональное программирование, используемое в Лиспе, основывается на том, что в результате каждого действия возникает значение. Значения становятся элементами следующих действий, и конечный результат всей задачи выдается пользователю. Обойти это можно только при помощи специальной функции QUOTE. То обстоятельство, что результатом вычислений могут быть новые функции, является важным преимуществом Лиспа.
Лисп - бестиповый язык.
В Лиспе имена символов, переменных, списков, функций и других объектов не закреплены предварительно за какими- ни будь типами данных. Типы в общем не связаны с именами объектов данных, а сопровождают сами объекты. Переменные в различные моменты времени могут представлять различные объекты. В этом смысле Лисп является бестиповым языком.
Динамическая, осуществляемая лишь в процессе исполнения, проверка типа и позднее связывание допускают разностороннее использование символов и гибкую модификацию программ. Функции можно определять практически независимо от типов данных, к которым они применяются.
Но указанная бестиповость не означает, что в Лиспе нет данных различных типов. Наоборот набор типов данных наиболее развитых Лисп-систем очень разнообразен.
Одним из общих принципов развития Лисп-систем было свободное включение в язык новых возможностей и структур, если считалось, что они найдут более широкое применение. Это было возможно в связи с естественной расширяемостью языка.
Платой за динамические типы являются действия по проверке типа на этапе исполнения. В более новых Лисп-системах (Коммон Лисп) возможно факультативное определение типов. В этом случае транслятор может использовать эту информацию для оптимизации кода. В Лисп-машинах проверка осуществляется на уровне аппаратуры.
Интерпретирующий и компилирующий режимы работы.
Лисп в первую очередь интерпретируемый язык. Программы не нужно транслировать, и их можно исправлять в процессе исполнения. Если какой-то участок программы отлажен и не требует изменений то его можно оттранслировать, тогда она выполняется быстрее. В одной и той же программе могут быть транслированные и интерпретированные функции. Транслирование по частям экономит усилия программиста и время вычислительной машины.
Однако компилирующий режим предусмотрен далеко не во всех Лисп-системах, его использование накладывает ряд дополнительных ограничений на технику программирования.
Пошаговое программирование.
Программирование и тестирование программы осуществляется функция за функцией, которые последовательно определяются и тестируются. Написание, тестирование и исправление программы осуществляются внутри Лисп-системы без промежуточного использования ОС.
Вспомогательные средства, такие например как, редактор, трассировщик, транслятор и другие образуют общую интегрированную среду, язык которой нельзя отличить от системных средств. Отдельные средства по своему принципу являются прозрачными, чтобы их могли использовать другие средства. Работа может производиться часто на различных уровнях или в различных рабочих окнах. Такой способ работы особенно хорошо подходит для исследовательского программирования и быстрого построения прототипов.
Единый системный и прикладной языки программирования.
Лисп является одновременно как языком прикладного так и системного программирования. Он напоминает машинный язык тем, что как данные, так и программы представлены в одинаковой форме. Язык превосходно подходит для написания интерпретаторов и трансляторов как для него самого, так и для других языков. Наиболее короткий интерпретатор Пролога, написанный на Лиспе занимает несколько десятков строк.
Традиционно Лисп-системы в основной своей части написаны на Лиспе. Лисп можно в хорошем смысле считать языком машинного и системного программирования высокого уровня. И это особенно хорошо для Лисп-машин, которые вплоть до уровня аппаратуры спроектированы для Лиспа и системное программное обеспечение которых написано на Лиспе.
2.2Понятия языка Лисп.
2.2.1 Атомы и списки.
Основная структура данных в Лиспе - символьные или S-выражения, которые определяются как атомы или списки.
Символы и числа представляют собой те объекты Лиспа, из которых строятся остальные структуры. Поэтому их называют атомами.
Символ - это имя, состоящее из букв, цифр и специальных знаков, которое обозначает какой-нибудь предмет, объект, действие из реального мира. В Лиспе символы обозначают числа, другие символы или более сложные структуры, программы (функции) и другие лисповские объекты.
Пример: х, г-1997, символ, function.
Числа не являются символами, так как число не может представлять иные лисповские объекты, кроме самого себя, или своего числового значения. В Лиспе используется большое количество различных типов чисел (целые, десятичные и т. д.) - 24, 35.6, 6.3 e5.
Символы T и NIL имеют в Лиспе специальное назначение: T обозначает логическое значение истина, а NIL - логическое значение ложь. Символы T и NIL имеют всегда одно и тоже фиксированное встроенное значение. Их нельзя использовать в качестве имен других лисповских объектов. Символ NIL обозначает также и пустой список.
Числа и логические значения T и NIL являются константами, остальные символы - переменными, которые используются для обозначения других лисповских объектов.
Список - это упорядоченная последовательность, элементами которой являются атомы или списки (подсписки). Списки заключаются в круглые скобки, элементы списка разделяются пробелами. Открывающие и закрывающие скобки находятся в строгом соответствии. Список всегда начинается с открывающей и заканчивается закрывающей скобкой. Список, который состоит из 0 элементов называют пустым и обозначают () или NIL. Пустой список - это атом. Например: (а в (с о) р), (+ 3 6).
 |

 Символ
Символ

Число T, NILСписки
Константы
Атомы
S-выражения
Рис.2 Символьные выражения.
2.2.2 Внутреннее представление списка.
Оперативная память машины логически разбивается на маленькие области, называемые списочными ячейками. Списочная ячейка состоит из двух частей, полей CAR и CDR (головы и хвоста соответственно). Каждое из полей содержит указатель. Указатель может ссылаться на другую списочную ячейку или на другой лисповский объект, например, атом. Указатели между ячейками образуют как бы цепочку, по которой можно из предыдущей ячейки попасть в следующую и так до атомарных объектов. Каждый известный системе атом записан в определенном месте памяти лишь один раз. Указателем списка является указатель на первую ячейку списка. На одну и ту же ячейку может указывать несколько указателей, но исходить только один.
Графически списочная ячейка представляется прямоугольником (рис3), разделенным на части CAR и CDR. Указатель изображается в виде стрелки, начинающейся в одной из частей прямоугольника и заканчивающейся на изображении другой ячейки или атоме, на которые ссылается указатель.
 |
Рис.3 Списочная ячейка.
Логически идентичные атомы содержатся в системе лишь один раз. Но логически идентичные списки могут быть представлены различными списочными ячейками. Например, список ((dc) adc) изображается как показано на рис.4. В результате вычислений в памяти могут возникнуть структуры на которые нельзя потом сослаться. Это происходит, если структуры не сохранены с помощью функции SETQ или теряется ссылка на старое значение в связи с новым переприсваиванием.
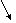
 |
A D C
 |
 |





Рис.4
|
|||
 |
A D C
 |
рис.5
В зависимости от способа построения логическая и физическая структуры двух списков могут оказаться различными. Например, список ((dc) adc) может иметь и другую структуру (рис5). Логическая структура всегда топологически имеет форму двоичного дерева, в то время как физическая структура может быть ациклическим графом, т. е. ветви могут снова сходиться, но никогда не могут образовывать замкнутые циклы (указывать назад).
При логическом сравнивании списков используют предикат EQUAL, сравнивающий не физические указатели, а совпадение структурного построения списков и совпадение атомов, формирующих список.
Предикат EQ можно использовать лишь для сравнения двух символов. Во многих реализациях Лиспа этот предикат обобщен таким образом, что с его помощью можно определить физическое равенство двух выражений (т. е. ссылаются ли значения аргументов на один физический лисповский объект) не зависимо от того, является ли он атомом или списком.
2.2.3 Написание программы на Лиспе.
Любая Лисп-система представляет собой небольшую программу, назначение которой - выполнение программ путем интерпретации S-выражений, подаваемых на вход. Механизм работы Лисп-системы очень прост. Он состоит из трех последовательных шагов: считывание S-выражения; интерпретация S-выражения; печать S-выражения.
Обычно, написание программы на Лиспе - написание некоторой функции, возможно весьма сложного вида, при вычислении использующей какие-либо другие функции или рекурсивно саму себя. Однако на практике часто оказывается, что более удобно решать задачи путем выполнения последовательности отдельных более или менее простых шагов с сохранением и дальнейшим использованием промежуточных результатов. Шагом в нашем случае будет вычисление некоторой функции Лиспа. Разрешая использовать переменные не только в качестве аргументов функций, мы расстаемся с чистотой функционального программирования, но вместе с тем приобретаем инструмент, в ряде случаев облегчающий написание программ и нередко повышающий эффективность их работы на ВМ с традиционной архитектурой. Наиболее широко в практическом программировании на Лиспе распространен смешанный стиль программирования: программу стараются писать функционально, но при этом соответствующие функции не делают слишком сложными, переходя везде, где это облегчает написание соответствующей функции и понимание принципа ее работы, к императивному (второму) методу программирования.
Итак, как правило, программа написанная на Лиспе, представляет собой последовательность вызовов некоторых функций, как встроенных в Лисп, так и предварительно описанных самим пользователем, а средством связи между последовательно вызываемыми функциями являются переменные, позволяющие запомнить любой объект (атом, список, точечную пару).
Все Лисп-системы имеют некоторый набор базовых функций (их мы рассмотрим в лабораторных работах), которые изначально встроены в интерпретатор. Кроме того, пользователь может определять свои собственные функции на языке Лисп, используя специальные конструкторы функций. Если атом f не удается интерпретировать как встроенную функцию языка или как функцию, определенную пользователем, большинство интерпретаторов выдают сообщение об ошибке.
Множества базовых функций различных диалектов сильно отличаются друг от друга, и их число колеблется от нескольких десятков до нескольких сотен. Встроенные функции выполняются с большей скоростью, чем функции, определенные пользователем, так как первые реализованы на том же языке, что и вся Лисп-система (Ассемблер, С, Паскаль). Чрезмерное увеличение базового набора функций приводит к уменьшению рабочей памяти, отводимой под задачи пользователя.
2.2.4 Определение функций.
Определение функций и их вычисление в Лиспе основано на лямбда-исчислении Черча. В лямбда-исчислении Черча функция записывается в следующем виде:
lambda(x1,x2,...,xn).fn
В Лиспе лямбда-выражение имеет вид
(LAMBDA (x1 x2 ... xn) fn)
Символ LAMBDA означает, что мы имеем дело с определением функции. Символы xiявляются формальными параметрами определения, которые имеют аргументы в описывающем вычисления теле функции fn. Входящий в состав формы список, образованный из параметров, называют лямбда-списком.
Телом функции является произвольная форма, значение которой может вычислить интерпретатор Лиспа.
Формальность параметров означает, что их можно заменить на любые другие символы, и это не отразится на вычислениях, определяемых функцией.
Лямбда-выражение - это определение вычислений и параметров функции в чистом виде без фактических параметров, или аргументов. Для того, чтобы применить такую функцию к некоторым аргументам, нужно в вызове функции поставить лямбда-определение на место имени функции:
(лямбда-выражение а1 а2 ... аn)
Здесь ai - формы, задающие фактические параметры, которые вычисляются как обычно.
Вычисление лямбда-вызова, или применение лямбда-выражения к фактическим параметрам, производится в два этапа. Сначала вычисляются значения фактических параметров и соответствующие формальные параметры связываются с полученными значениями. Этот этап называется связыванием параметров. На следующем этапе с учетом новых связей вычисляется форма, являющаяся телом лямбда-выражения, и полученное значение возвращается в качестве значения лямбда-вызова. Формальным параметрам после окончания вычисления возвращаются те связи, которые у них, возможно были перед вычислением лямбда-вызова.
Лямбда-вызовы можно свободно объединять между собой и другими формами. Вложенные лямбда-вызовы можно ставить как на место тела лямбда-выражения, так и на место фактических параметров.
Лямбда-выражение является как чисто абстрактным механизмом для описания и определения вычислений, так и механизмом для связывания формальных и фактических параметров на время выполнения вычислений. Лямбда-выражение - это безымянная функция, которая пропадает тотчас после вычисления значения формы. Ее трудно использовать снова, так как нельзя вызвать по имени, хотя ранее выражение было доступно как списочный объект. Однако используются и безымянные функции, например при передаче функции в качестве аргумента другой функции или при формировании функции в результате вычислений, другими словами, при синтезе программ.
Лямбда-выражение соответствует используемому в других языках определению процедуры или функции, а лямбда-вызов - вызову процедуры или функции. Записывать вызовы функций полностью с помощью лямбда-вызовов не разумно, поскольку очень скоро выражения в вызове пришлось бы повторять, хотя разные вызовы одной функции отличаются лишь в части фактических параметров. Проблема разрешима путем именования лямбда-выражений и использования в вызове лишь имени.
Дать имя и определить новую функцию можно с помощью функции DEFUN:
(DEFUNимя лямбда-список тело)
DEFUN соединяет символ с лямбда-выражением, и символ начинает представлять определенные этим лямбда-выражением вычисления. Значением этой формы является имя новой функции.
В различных диалектах Лиспа вместо DEFUN используются другие имена и формы (DEFINE, DE, CSETQ и др.).
2.2.5 Рекурсия и итерация.
Будучи языком функций, символьным языком и языком списков, Лисп является и рекурсивным языком. В программировании на Лиспе рекурсия используется для организации повторяющихся вычислений. На ней же основано разбиение проблемы на подзадачи, решение которых пытаются свести к уже решенной или решаемой в данный момент задачи.
Основная идея рекурсивного определения заключается в том, что функцию можно с помощью рекуррентных формул свести к некоторым начальным значениям, к ранее определенным функциям или к самой определяемой функции, но с более «простыми» аргументами. Вычисление такой функции заканчивается в тот момент, когда оно сводится к известным начальным значениям. Разумеется, можно организовать вычисления по рекуррентным формулам и без использования рекурсии, однако при этом встает вопрос о ясности программы и доказательстве ее эквивалентности исходным формулам. Использование рекурсии позволяет легко запрограммировать вычисление по рекуррентным формулам.
В рекурсивном описании действий имеет смысл обратить внимание на следующие обстоятельства. Во-первых, процедура содержит всегда по крайней мере одну терминальную ветвь и условие окончания. Во-вторых, когда процедура доходит до рекурсивной ветви, то функционирующий процесс приостанавливается, и новый такой же процесс запускается сначала, но уже на новом уровне. Прерванный процесс каким-нибудь образом запоминается. Он будет ждать и начнет исполняться лишь после окончания нового процесса. В свою очередь, новый процесс может приостановиться, ожидать и т. д.
Так образуется как бы стек прерванных процессов, из которых выполняется лишь последний в настоящий момент времени процесс; после окончания его работы продолжает выполняться предшествовавший ему процесс. Целиком весь процесс выполнен, когда стек снова опустеет, или, другими словами, все прерванные процессы выполнятся.
Можно говорить о рекурсии по значению, когда вызов является выражением, определяющим результат функции. Если в качестве результата функции возвращается значение некоторой другой функции и рекурсивный вызов участвует в вычислении аргументов этой функции, то будем говорить о рекурсии по аргументам. Аргументом рекурсивного вызова может быть вновь рекурсивный вызов и таких вызовов может быть много.
Для обеспечения «идеологической» совместимости с другими языками программирования, а также для повышения эффективности программ при решении некоторых частных задач в язык была введена группа функций, предоставляющих возможность организации итерационной обработки информации.
В указанной группе прежде всего выделяются так называемые отображающие или MAP-функции: MAPC, MAPCAR, MAPLIST и другие. MAP-функционалы являются функциями, которые некоторым образом отображают список (последовательность) в новую последовательность или порождают побочный эффект, связанный с этой последовательностью. Каждая из них имеет более двух аргументов, значением первого должно быть имя определенной ранее или базовой функции, или лямбда-выражение, вызываемое MAP-функцией итерационно, а остальные аргументы служат для задания аргументов на каждой итерации. Естественно, что количество аргументов в обращении к MAP-функции должно быть согласовано с предусмотренным количеством аргументов у аргумента-функции. Различие между всеми MAP-функциями состоит в правилах формирования возвращаемого значения и механизме выбора аргументов итерирующей функции на каждом шаге.
Рассмотрим основные типы MAP-функций.
MAPCAR.
Значение этой функции вычисляется путем применения функции fnк последовательным элементам xi списка, являющегося вторым аргументом функции. Например в случае одного списка получается следующее выражение:
(MAPCARfn ‘(x1 x2 ... xn))
В качестве значения функционала возвращается список, построенный из результатов вызовов функционального аргумента MAPCAR
MAPLIST.
MAPLISTдействует подобно MAPCAR, но действия осуществляет не над элементами списка, а над последовательными CDR этого списка.
Функционалы MAPCARи MAPLIST используются для программирования циклов специального вида и в определении других функций, поскольку с их помощью можно сократить запись повторяющихся вычислений.
Функции MAPCAN и MAPCON являются аналогами функций MAPCARи MAPLIST. Отличие состоит в том, что MAPCAN и MAPCON не строят, используя LIST, новый список из результатов, а объединяют списки, являющиеся результатами, в один список.
LOOP .
Другим типичным представителем группы итерационных функций может служить функция LOOP, имеющая в общем случае вид (LOOPexpr1 expr2 ... exprN), где в качестве аргументов могут быть использованы любые синтаксически и семантически допустимые S-выражения либо специальные конструкции.
2.2.6 Функции интерпретации выражения.
Почти во всех диалектах определены функции APPLY и FUNCALL, позволяющие интерпретировать S-выражения. Обращения к этим функциям имеют следующий вид:
(APPLYfunarg)
(FUNCALL fun arg1 arg2 ... argN)
APPLY и FUNCALL вычисляют функции, являющиеся их первыми аргументами, производя связывание формальных аргументов с указанными S-выражениями arg или arg1, arg2, ... argN. В качестве значения возвращается результат применения функции fun, которая может быть встроенной или определенной функцией или лямбда-выражением.
Необходимо отметить еще одну особенность языка Лисп, которая вытекает из природы организации структур данных и программ и механизма их интерпретации. На языке легко реализовать задачи автоматического синтеза программ. Он позволяет с помощью одних функций формировать определения других функций, программно анализировать и редактировать эти определения как S-выражения, а затем исполнять их.
2.2.7 Макросредства.
Часто бывает полезно не выписывать вычисляемое выражение вручную, а сформировать его с помощью программы. Эта идея автоматического динамического программирования особенно хорошо реализуется в Лиспе. Программное формирование выражений наиболее естественно осуществляется с помощью специальных макросов. Использование макросредств, предлагаемых современными Лисп-системами, - один из самых эффективных путей реализации сложных программ. Макросы дают возможность расширять синтаксис и семантику Лиспа и использовать новые подходящие для решаемой задачи формы предложений. Они дают возможность писать компактные, ориентированные на задачу программы, которые автоматически преобразуются в более сложный, но более близкий машине эффективный лисповский код. При наличии макросредств некоторые функции в языке могут быть определены в виде макрофункций. Такое определение фактически задает закон предварительного построения тела функции непосредственно перед фазой интерпретации.
Синтаксис определения макроса выглядит так же, как синтаксис используемой при определении функций формы DEFUN:
(DEFMACROимя лямбда-список тело)
Вызов макроса совпадает по форме с вызовом функции, но его вычисление отличается от вычисления вызова функции. Первое отличие состоит в том, что в макросе не вычисляются аргументы. Тело макроса вычисляется с аргументами в том виде, как они записаны.
Второе отличие состоит в том, что интерпретация функций, определенных как макро, производится в два этапа. На первом, называемом макрорасширением, происходит формирование лямбда-определения функции в зависимости от текущего контекста, на втором осуществляется интерпретация созданного лямбда-выражения.
Макросы отличаются от функций и в отношении контекста вычислений. Во время расширения макроса доступны синтаксические связи из контекста определеня. Вычисление же полученной в результате расширения формы производится вне контекста макровызова, и поэтому статические связи из макроса не действуют. Использование макрофункций облегчает построение языка с лиспоподобной структурой, имеющего свой синтаксис, более удобный для пользователя. Чрезмерное использование макросредств затрудняет чтение и понимание программ.
2.2.8 Функции ввода-вывода.
Современные диалекты языка Лисп, как правило, имеют развитые средства управления вводом-выводом. Основу этих средств составляют три основные функции READ, RATOM и PRINT. Первые две позволяют осуществлять операций ввода S-выражений (READ) и атомов (RATOM), последняя выполняет вывод S-выражений.
Лисповская функция чтения READобрабатывает выражение целиком. Вызов функции осуществляется в виде
(READ)
Функция не показывает, что она ждет ввода выражения. Она лишь читает выражение и возвращает в качестве значения само это выражение, после чего вычисления продолжаются.
Для вывода выражений используют функцию PRINT. Это функция с одним аргументом, которая сначала вычисляет значение аргумента, а затем выводит это значение. Функция PRINT перед выводом аргумента переходит на новую строку, а после него выводит пробел. Таким образом, значение выводится всегда на новую строку. Более подробно эти и другие функции рассмотрим в лабораторных работах.
Базовый набор функций обычно наряду с указанными функциями включает различные их модификации и дополнительные функции, позволяющие при программировании легко получить некоторые дополнительные эффекты (автоматическое дополнение печатной строки с изображением S-выражения специальными символами перевода каретки на начало следующей строки, блокировка специальных метасимволов при выводе литеральных атомов, в печатных именах которых присутствуют непечатные символы и т. д.). кроме того, практически каждый диалект содержит набор функций управления входными и выходными потоками для связи с внешними устройствами ЭВМ. Однако указанные функции являются одной из наиболее машинно-зависимых составляющих Лисп-систем, поскольку по необходимости учитывают специфику среды операционной системы.
2.3 Знания в ИИ.
2.3.1 Требования к знаниям.
Знания должны отвечать следующим требованиям:
1. Должны быть явными и доступными. Это главное отличие знаний от других программных продуктов.
2. Использовать высококачественный опыт специалистов, т, е, знания должны отражать уровень наиболее квалифицированных специалистов в данной области.
3. Обладать гибкостью, т. е. система может наращиваться постепенно в соответствии с нуждами бизнеса или заказчика.
4. Иметь систему объяснений. Интересует не только ответ, но и как машина к нему пришла.
5. Обладать возможностью прогнозирования. Система должна не только давать ответы на конкретно поставленные вопросы, но и показывать как они изменяются в новой ситуации.
6. Память должна быть инстуциональной, т. е. специалисты уходят, их опыт остается. База знаний становится постоянно обновляющимся справочником наилучших стратегий и методов.
2.3.2 Основные типы знаний.
Определение знания как понятия - трудная проблема. В области ИИ наиболее важные типы знаний классифицируются следующим образом:
1. Объекты и их свойства.
Объекты - это существующие в прикладной области универсальные понятия и их представители: живые существа, предметы или материалы или абстрактные понятия.
2. События.
События описывают участие объектов в деятельности и ситуациях. События характеризуют, например, время, место и причинно-следственные отношения.
3. Действия.
Обычно интеллектуальная деятельность предполагает также способность совершать действия, т. е. процедурные знания о том, каким образом что-то делается, например каким образом из старых данных на основе правил выводятся новые.
4. Метазнания.
Метазнания - это знания о знаниях и их использовании, например способность выбрать метод решения для проблем разных типов.
2.3.3. Методы представления знаний.
Представление знаний - это основная область исследований по ИИ. Особенности представления знаний и механизм логического вывода определяют дваосновных элемента ЭС - БЗ и машину логического вывода. Любая работающая со знаниями программа должна каким-то образом отображать знания из своей области применения. Обычно для этого не достаточно примитивных структур данных, используемых в традиционной обработке данных, таких как числа, массивы, записи и др., и методов работы с ними. В ИИ используются символьные языки представления знаний и формализмы, стоящие на более высоком понятийном уровне.
Рассмотрим важнейшие из общих методов и формализмов, разработанных для представления и обработки знаний:
1. Логика. В программах ИИ особенно часто используются различные формы логики предикатов первого порядка. Основное преимущество базирующихся на логике формализмов состоит в ром, что обычно с их помощью проще обеспечить корректность структур и решений системы, чем с помощью других способов представления.
2. Продукционные системы
Наиболее распространенными простым для понимания является представление знаний при помощи правилпродукциивида «ЕСЛИ <условие>,ТО <следствие>». Такие системы называют продукционными.Эти правила похожи на условные операторы IF-THENязыков программирования,однако совершенно по другому интерпретируются.
Через правила можно определить, как программа должна реагировать на изменение данных. При этом не нужно заранее знать блок-схему управления обработкой данных. В обычнойпрограммесхема передачи управления и использованияданных предопределения самой программой. Ветвление в таких программахвозможно только в заранее выбранных точках. Для задач, ход решения которых управляется самими данными, где ветвление скорее норма, чем исключение, этот способ малоэффективен.
В состав продукционных систем входят:база знаний (используюттермин:«база правил»);рабочая память или база данных; машина вывода (используют термин: «управляющая структура»). База правилсодержит правилапродукций.Рабочая память отображает текущее состояние процессаконсультации.Содержит текущиезначения переменных и состояние машины вывода. Машина вывода являющаяся,по сути, интерпретатором правил определяет последовательность активизации правил,выполняет их,частично заполняет рабочую память по собственний инициативе,и частично по инструкциям из базы правил. Работа интерпретатора правил состоит из циклически повторяющихся этапов. Сначала определяется, какие правила могут выполняться в данный момент, для чего отдельные части правил сравниваются с информацией хранимой в рабочей памяти. Затем определяется, какоеправило следует выполнять первым.Критерием может быть приоритет,скорость выполнения правила и некоторые другие вещи. Затем правило исполняется, под чем подразумевается изменение рабочей области,внутренних переменных машинывывода и окружения.
Существует два основных метода просмотра и выполнения правил. Это прямой и обратный выводы.
Прямой вывод,управляемый посылками правил, похож на выполнение зацикленной программы, на алгоритмическом языке, представляющей собой набор условных операторов. Припрямомвыводе выполняются только те правила, посылки которых принимают истинное значение. Процесс поиска и выполнения правил продолжается до техпор,пока не будет достигнута цель консультации или не будут исчерпаны все правила и ни в одном посылканеокажется истинной.
При обратном выводе,управляемом следствиямиилицелями правил (используетсядля создания ЭС диагностики и интерпретации), происходит движение от следствий к посылкам. Машина вывода выбирает очередную неизвестную переменную и пытается присвоить ейкакое-тозначение. Для этого она просматривает все правила, в THEN поле которых присутствует эта переменная и проверяет посылку правила. Если в посылке правила присутствуют не определенные переменные, то аналогичным способом машина вывода пытается найти их. Если правило с искомой переменной не выполняется,то ищутся другие правила,содержащие в THEN полеэту переменную.
Возможен так же смешанный вывод.
3. Семантические сети. В семантической сети понятия и классы, а также отношения и связи между ними представлены в виде поименованного графа. Каждый узел содержит ссылку на один или несколько других узлов.Ссылка представляет собой так же понятие, устанавливающее взаимосвязь между узлами. Предполагается, чтопонятий-ссылок меньше чем узлов сети,и с помощью этого ограниченного круга понятий можно определить каждый узел сети через узлы нижнего уровня, содержащие обобщенные понятия.
Преимущества такого формализма заключаются в его наглядности и непосредственной связанности понятий через сеть, которая позволяет быстро находить связи понятий и на этой основе управлять решениями.
4. Фреймы. Это частный случай семантических сетей. Это метод представления знаний,который связываетсвойства с узлами , представляющими понятия и объекты. Свойства описываются атрибутами (называемыми слотами) и их значениями. Использование фреймов с их атрибутами и взаимосвязями позволяет хранить знания опредметной областив структурированномвиде, представлять в БЗ абстракции и аналогии.
С операциями присваивания значений фреймам и другими операциями можно сочетать сложные побочные действия и взаимовлияния.
Используются и другие связанные с конкретным применением способы представления, но они менее распространены и, как правило, не годятся для использования в общем случае.
Не всегда можно однозначно сказать, какой формализм представления использован в системе. В рамках одной и той же системы для представления различных видов знаний могут быть использованы различные формализм.
Лабораторная работа № 1.
Тема: Ознакомительная работа в среде MuLisp. Базовые функции Лиспа. Символы, свойства символов. Средст-ва языка для работы с числами.
Цель: Ознакомиться со средой MuLisp. Изучить базовые функции Лиспа, символы и их свойства, а также средства для работы с числами.
1. Основные положения программирования на Лиспе.
2. Загрузка системы, системный редактор.
3. Базовые функции языка. Символы, свойства символов.
4. Средства языка для работы с числами.
5. Задание к лабораторной работе.
6. Вопросы.
1. Основные положения программирования на Лиспе.
nсписочных структур, лямбда-исчислении и теории рекурсий.
n«ENTER».
nQUOTE.
n
n
n
Атомы - это символы и числа.
Список - упорядоченная последовательность, элементами которой являются атомы либо списки. Списки заключаются в круглые скобки, элементы списка разделяются пробелами. Несколько пробелов между символами эквивалентны одному пробелу. Первый элемент списка называется «головой», а остаток , т. е. список без первого элемента, называется «хвостом. Список в котором нет ни одного элемента, называется пустым и обозначается «()» либо NIL.
nMuLisp, прописные и строчные буквы отождествляются и представляются прописными буквами.
nTи NIL имеют в Лиспе специальное назначение: T- обозначает логическое значение истина, а NIL - логическое значение ложь.
nMuLispом нового символа, за его величину принимается он сам. Такая ссылка символа на себя называется автоссылкой.
nLSP.
nвсюпрограмму в одну строку. Однако отступы в строках и пустые строки делают структуру программы понятней и более читабельней. Так же выравнивание начальных и конечных скобок основных выражений помогают убедитьсяв балансе ваших скобок.
n загружатьсяиспользуяфункцию LOAD:
(load <имя файла>)
Эта функция загружает файл выражений и выполняетэти выражения. <Имя файла> - это строковая константа, которая представляет собойимя файлабезрасширения (подразумеваетсярасширение ".lsp"). Еслиоперацияуспешно завершена, LOAD возвращает имя последней функции, определенной в файле. Если операция не выполнена, LOAD возвращает имя файла в виде строкового выражения.
Функция LOAD не может вызыватьсяиздругой функцииLISP.Она должна вызыватьсянепосредственно с клавиатуры, в то время какниодна другаяфункцияLISP не находится в процессе выполнения.
nLSP.
nMuLisp включает в себя сравнительно небольшой набор базовых функций, указанная Лисп-система обеспечивается библиотеками Лисп-функций, дополняющими базовый набор функциями, имеющимися в CommonLisp-е и других диалектах(Common.lsp, Array.lspи т. д. ...).
2. Загрузка системы. Системный редактор.
Запуск системы MuLispс расширением Common.lsp осуществляется командой:
MuLisp87.comCommon.lsp.
После нескольких секунд загрузки на экране дисплея появится сообщение:
MuLisp-87 IBM PC MS-DOS Version 6.01 (11/05/87)
(C ) Copyright SoftWarehouse, Inc., 1983, 1985, 1986, 1987.
All rights Reserved Worldwide.
; LoadingC:Common.lsp
После чего появится знак $, означающий приглашение системы к работе. Для загрузки системного редактора необходимо набрать следующую команду:
(LOADedit.lsp)
Системный редактор начинает работать. Он чистит экран рисует рамку и выдает на экран свое меню:
Alpha, Block, Delete, Jump, List, Options, Print, Quit, Replace, Search, Transfer, Undelete и Window.
Затем система ждет, пока пользователь не выберет одну из опций. Для этого необходимо установить курсор на выбранной опции и нажать клавишу «Enter». Переход от одной опции к другой производится с помощью клавиши «Tab».
nAlpha: включение режима редактирования.
nBlock: работа с блоком. Выделение, копирование, удаление, перенос и др.
nDelete: удаление блока, символа, слова, строки.
nJump: переход в начало или конец текста программы, вверх-вниз страницы.
nList: работа со списком. Удаление, переход к предыдущему, последующему.
nOptions: работа с цветами, монитором, звуком.
nPrint: печать текста программы.
nQuit: выход из системы.
nReplace: изменение строки.
nSearch: поиск строки. Причем строчные и прописные буквы различаются.
nTransfer: работа с файлами. Запись, нахождение, объединение, удаление.
nUndelete: восстановление.
nWindow: работа с окнами. Открыть, закрыть, перейти к другому и т. д.
3. Базовые функции языка.
Функции разбора.
Функция CARвозвращает в качестве значения первый элемент списка.
(CARсписок) ð S - выражение (атом либо список).
_(CAR ‘(a b c d)) ð a
_(CAR ‘((a b) c d)) ð (a b)
_(CAR ‘(a)) ð a
_(CARNIL) ð NIL «Голова пустого списка - пустой список.»
Вызов функции CARс аргументом (abcd) без апострофа был бы проинтерпретирован как вызов функции «a» с аргументом «bcd», и было бы получено сообщение об ошибке.
Функция CAR имеет смысл только для аргументов, являющихся списками.
(CAR ‘a) ð Error
Функция CDR - возвращает в качестве значения хвостовую часть списка, т. е. список, получаемый из исходного списка после удаления из него головного элемента:
(CDRсписок) ð список
Функция CDRопределена только для списков.
_(CDR ‘(a b c d)) ð (b c d)
_(CDR ‘((a b) c d)) ð (c d)
_(CDR ‘(a (b c d))) ð ((b c d))
_(CDR ‘(a)) ð NIL
_(CDR NIL) ð NIL
_(CDR ‘a) ðError
Функция создания CONS.
Функция CONS строит новый список из переданных ей в качестве аргументов головы и хвоста.
(CONSголова хвост)
Для того чтобы можно было включить первый элемент функции CONSв качестве первого элемента значения второго аргумента этой функции, второй аргумент должен быть списком. Значением функции CONS всегда будет список:
(CONSs-выражение список) ð список
_(CONS ‘a ‘(b c)) ð (a b c)
_(CONS ‘(a b) ‘(c d)) ð ((a b) c d)
_(CONS (+ 1 2) ‘(+ 3)) ð (3 + 3)
_(CONS ‘(a b c) NIL) ð ((a b c))
_(CONS NIL ‘(a b c)) ð (NIL a b c)
Предикаты ATOM, EQ, EQL, EQUAL.
Предикат - функция, которая определяет, обладает ли аргумент определенным свойством, и возвращает в качестве значения NILили T.
Предикат ATOM- проверяет, является ли аргумент атомом:
(ATOMs - выражение)
Значением вызова ATOMбудет T, если аргументом является атом, и NIL - в противном случае.
_(ATOM ‘a) ð T
_(ATOM ‘(a b c)) ð NIL
_(ATOM NIL) ð T
_(ATOM ‘(NIL)) ð NIL
Предикат EQсравнивает два символа и возвращает значение T, если они идентичны, в противном случае - NIL. С помощью EQ сравнивают только символы или константы T и NIL.
_(EQ ‘a ‘b) ð NIL
_(EQ ‘a (CAR ‘(a b c))) ð T
_(EQNIL ()) ðT
Предикат EQLработает так же как и EQ, но дополнительно позволяет сравнивать однотипные числа.
_(EQL 2 2) ð T
_(EQL 2.0 2.0) ð T
_(EQL 2 2.0) ð NIL
Для сравнения чисел различных типов используют предикат «=». Значением предиката «=» является Tв случае равенства чисел независимо от их типов и внешнего вида записи.
(= 2 2.0) ðT
Предикат EQUAL проверяет идентичность записей. Он работает как EQL , но дополнительно проверяет одинаковость двух списков. Если внешняя структура двух лисповских объектов одинакова, то результатомEQUALбудет T.
_(EQUAL ‘a ‘a) ð T
_(EQUAL ‘(a b c) ‘(a b c)) ð T
_(EQUAL ‘(a b c) ‘(CONS ‘a ‘(b c))) ð T
_(EQUAL 1.0 1) ðNIL
Функция NULL проверяет на пустой список.
_(NULL ‘()) ðT
Вложенные вызовы CARи CDR.
Комбинации вызовов CAR и CDR образуют уходящие в глубину списка обращения, в Лиспе для этого используется более короткая запись. Желаемую комбинацию вызовов CAR и CDR можно записать в виде одного вызова функции:
(C...Rсписок )
Вместо многоточия записывается нужная комбинация из букв Aи D (для CARи CDR соответственно). В один вызов можно объединять не более четырех функций CARи CDR.
(CADAR x) ó (CAR (CDR (CAR x)))
_(CDDAR ‘((a b c d) e)) ð (c d)
_(CDDR ‘(klm)) ð (M)
Функция LIST - создает список из элементов. Она возвращает в качестве своего значения список из значений аргументов. Количество аргументов произвольно.
_(LIST ‘a ‘b ‘c) ð (abc)
_(LIST ‘a ‘b (+ 1 2)) ð (ab 3)
4. Символы, свойства символов.
Функции присваивания: SET, SETQ, SETF.
Функция SET - присваивает символу или связывает с ним некоторое значение. Причем она вычисляет оба своих аргумента. Установленная связь действительна до конца работы, если этому имени не будет присвоено новое значение функцией SET.
_(SET ‘a ‘(b c d)) ð (b c d)
_a ð(b c d)
_(SET (CAR a) (CDR (o f g)) ð (f g)
_a ð (b c d)
_(CAR a) ð b
_b ð (f g)
Значение символа вычисляется с помощью специальной функции Symbol-value, которая возвращает в качестве значения значение своего аргумента.
_(Symbol-value (CAR a)) ð (f g)
Функция SETQ - связывает имя, не вычисляя его. Эта функция отличается от SETтем, что вычисляет только второй аргумент.
_(SETQ d ‘(l m n)) ð (l m n)
Функция SETF - обобщенная функция присваивания. SETF используется для занесения значения в ячейку памяти.
( SETFячейка-памяти значение)
_(SETFячейка ‘(abc)) ð (abc)
_ ячейка ð (abc)
Переменная «ячейка» без апострофа указывает на ячейку памяти, куда помещается в качестве значения список (abc).
Свойства символа.
В Лиспе с символом можно связать именованные свойства. Свойства символа записываются в хранимый вместе с символом список свойств. Свойство имеет имя и значение. Список свойств может быть пуст. Его можно изменять или удалять без ограничений.
(имя1 знач1 имя2 знач2 ... имяN значN)
Пусть имя студент имеет следующий список свойств:
(имя Иван отчество Иванович фамилия Иванов)
Функция GET - возвращает значение свойства, связанного с символом.
(GETсимвол свойство )
При отсутствии свойства функция GET возвращает NIL в качестве ответа.
_(GET ‘студент ‘имя) ð Иван
_(GET ‘студент ‘группа) ð NIL
Присваивание и удаление свойств.
Для присваивания символу свойств в MuLisp (как и в CommonLisp) отдельной функции нет. Для этого используются уже известные нам функции:
(SETF (GETсимвол свойство) значение)
_(SETF (GET ‘студент ’группа) ’РВ-90-1) ð РВ-90-1
_(GET ‘студент ’группа) ð РВ-90-1
Удаление свойства и его значения осуществляется псевдофункцией REMPROP:
Эта функция возвращает в качестве значения имя удаляемого свойства. Если удаляемого свойства нет, то возвращается NIL.
(REMPROPсимвол свойство)
_(REMPROP ‘студент ’группа) ð группа
_(GET ‘студент ’группа) ð NIL
_(REMPROP ‘студент ’ср_бал) ð NIL
Для просмотра всего списка свойств используют функцию SYMBOL-PLIST. Значением функции является весь список свойств.
(SYMBOL-PLIST‘СИМВОЛ)
(SYMBOL-PLIST‘студент) ð (имя Иван отчество Иванович фамилия Иванов)
Свойства символов независимо от их значений доступны из всех контекстов пока не будут явно изменены или удалены. Изменение значения символа не влияет на другие свойства. Свойства символа передаются другому символу с помощью функции SETQ.
5. Средства языка для работы с числами. (Математические и логические функции).
В языке Лисп как для вызова функций, так и для записи выражения принята единообразная префиксная форма записи, при которой как имя функции или действия, так и сами аргументы записываются внутри скобок:
(fx), (gxy), (hx (gyz)) и т. д.
Арифметические действия:
(+числа) - сложение чисел
(- число числа) - вычитание чисел из числа
(* числа) - умножение чисел
и т. д.
_(+ 5 7 4) ð 16
_(- 10 3 4 1) ð 2
_(/ 15 3) ð 5
Сравнение чисел:
(= число числа) ð равны (все)
(< число числа) ð меньше (для всех)
(> число числа) ð больше (для всех)
и т. д.
Числовые предикаты:
(ZEROP число) ð проверка на ноль
(MINUSP число) ð проверка на отрицательность
и т. д.
Логические действия:
(NOT объект) ð логическое отрицание
(AND(формы)) ð логическое И
(OR (формы)) ðлогическоеИЛИ
_(AND (ATOM NIL) (NULL NIL) (EQ NIL NIL)) ð T
_( NOT (NULLNIL)) ð NIL
Кроме приведенных, существует множество других, но не менее полезных функций.
6. Задание к лабораторной работе.
1. Запишите последовательности вызовов CARи CDR, выделяющие из приведенных ниже списков символ «а». Упростите эти вызовы с помощью функций C...R.
а) (1 2 3 а 4)
б) (1 2 3 4 а)
в) ((1) (2 3) (а 4))
г) ((1) ((2 3 а) (4)))
д) ((1) ((2 3 а 4)))
е) (1 (2 ((3 4 (5 (6 а))))))
2. Каково значение каждого из следующих выражений:
a) (ATOM (CAR (QUOTE ((1 2) 3 4))));
b) (NULL (CDDR (QUOTE ((5 6) (7 8)))));
c) (EQUAL (CAR (QUOTE ((7 )))) (CDR (QUOTE (5 7))));
d) (ZEROP (CADDDR (QUOTE (3 2 1 0))));
3. Проделайте следующие вычисления с помощью интерпретатора Лиспа:
а) 3.234*(45.6+2.43)
б) 55+21.3+1.54*2.5432-32
в) (34-21.5676-43)/(342+32*4.1)
4. Определите значения следующих выражений:
а) ‘(+ 2 (* 3 5))
б) (+ 2 ‘(* 3 5))
в) (+ 2 (’ * 3 5))
г) (+ 2 (* 3 ’5))
д) (quote ‘quote)
е) (quote 6)
5.1 Составьте список студентов своей группы
(ФИО ФИО ... ФИО)
5.2 Для каждого студента
а) с помощью функции LIST составьте следующие списки:
Для самого студента - (дата рождения), (адрес), (средний бал по лекционным занятиям), (средний бал по практическим занятиям), (средний бал по лабораторным работам). Для отца и матери - (ФИО), (дата рождения), (адрес), (место работы).
б) с помощью функций CONS и SETQ объедините полученные списки и присвойте их в виде значений символам, означающим ФИО каждого студента:
ФИО ст. - (((дата рождения ст.) (адрес ст.)((ср. бал(до десятых) по лекционным занятиям) (ср. бал по практическим занятиям) (ср. бал по лабораторным работам))) (((ФИО отца) (дата рождения отца) (адрес) (место работы отца)) ((ФИО матери) (дата рождения матери) (адрес) (место работы матери)))).
5.3 Для произвольно выбранных студентов с помощью базовых функций сравните:
а) год рождения;
б) успеваемость (с учетом того, что число, характеризующее средний бал, может быть как целым, так и дробным );
в) выясните, не являются ли они родственниками;
г) выясните, живут ли они с родителями.
6.1 Для каждого студента составьте списки свойств
а) оценки по лекциям;
б) оценки по практикам;
в) оценки по лабораторным работам.
6.2 Для произвольно выбранных студентов сравнить свойства.
7. Вопросы.
1 Перечислите базовые функции.
2 Каковы типы аргументов базовых функций?
3 Какие значения они возвращают?
4 Что такое предикат?
5 Назовите основные отличия предикатов EQ, EQL, EQUALи =.
6 Назовите отличия функций CONSи LIST.
7 Что такое символ?
8 Различия функций SET, SETQ, SETF?
9 Особенности свойств символов?
Лабораторная работа №2.
Тема: Определение функций. Функции ввода-вывода. Вычисления, изменяющие структуру.
Цель: Получить навыки в написании функций. Изучить функции ввода-вывода.
1. Функции, определяемые пользователем.
2. Функция ввода.
3. Функции вывода.
4. Вычисления, изменяющие структуру.
5. Задание к лабораторной работе.
6. Вопросы.
1. Функции, определяемые пользователем.
Определение функций и их вычисление в Лиспе основано на лямбда-исчислении Черча.
В Лиспе лямбда-выражение имеет вид
(LAMBDA (x1 x2 ... xn) fn)
Символ LAMBDA означает, что мы имеем дело с определением функции. Символы xiявляются формальными параметрами определения, которые имеют аргументы в описывающем вычисления теле функции fn. Входящий в состав формы список, образованный из параметров, называют лямбда-списком.
Телом функции является произвольная форма, значение которой может вычислить интерпретатор Лиспа.
_(lambda (x y) (+ x y))
Формальность параметров означает, что их можно заменить на любые другие символы, и это не отразится на вычислениях, определяемых функцией.
Лямбда-выражение - это определение вычислений и параметров функции в чистом виде без фактических параметров, или аргументов. Для того, чтобыприменить такую функцию к некоторым аргументам, нужно в вызове функции поставить лямбда-определение на место имени функции:
(лямбда-выражение а1 а2 ... аn)
Здесь ai - формы, задающие фактические параметры, которые вычисляются как обычно.
_((lambda (x y) (+ x y)) 1 2) ð 3
Лямбда-вызовы можно свободно объединять между собой и другими формами. Вложенные лямбда-вызовы можно ставить как на место тела лямбда-выражения, так и на место фактических параметров.
_((lambda (x) ;Тело лямбда-вызова -
((lambda (y) (list x y)) ‘b)) ‘a) ð (a b) лямбда-вызов.
Записывать вызовы функций полностью с помощью лямбда-вызовов не разумно, поскольку очень скоро выражения в вызове пришлось бы повторять, хотя разные вызовы одной функции отличаются лишь в части фактических параметров. Проблема разрешима путем именования лямбда-выражений и использования в вызове лишь имени.
Дать имя и определить новую функцию можно с помощью функции DEFUN:
(DEFUNимя лямбда-список тело)
DEFUN соединяет символ с лямбда-выражением, и символ начинает представлять определенные этим лямбда-выражением вычисления. Значением этой формы является имя новой функции.
После именования функцииее вызов осуществляется по имени и параметрам.
_(defun list1 (x y)
(cons x (cons y nil))) ð list1
_(list1 ‘c ‘n) ð (cn)
(eval <выражение>)
Функция возвращает результат выражения <выражение>, где <выражение> - любое выражение языка LISP. Например, дано:
(setq a 123)
(setq b 'a)
(eval 4.0) ð 4.000000
(eval (abs -10)) ð 10
(eval a) ð 123
(eval b) ð 123
2. Функцияввода.
Лисповская функция чтения READобрабатывает выражение целиком. Вызов функции осуществляется в виде
_(READ)
(Вводимое выражение) ð ;выражение пользователя
ð(ВВОДИМОЕ ВЫРАЖЕНИЕ) ;значение функции READ
...
Функция не показывает, что она ждет ввода выражения. Она лишь читает выражение и возвращает в качестве значения само это выражение, после чего вычисления продолжаются.
Если прочитанное выражение необходимо сохранить для дальнейшего использования, то вызов READ должен быть аргументом какой-нибудь формы, например присваивания (SETQ), которая свяжет полученное выражение:
_(SETQinput (READ))
(+ 1 2) ;введенное выражение
(+ 1 2) ;значение
_inputð (+1 2)
3. Функции вывода.
Для вывода выражений используют несколько функций: PRINT, PRIN1, PRINC.
Функция PRINT.
Это функция с одним аргументом, которая сначала вычисляет значение аргумента, а затем выводит это значение. Функция PRINT перед выводом аргумента переходит на новую строку, а после него выводит пробел. Таким образом, значение выводится всегда на новую строку.
_(PRINT (+ 1 2))
3 ;вывод
3 ;значение
PRINT является псевдофункцией, у которой есть как побочный эффект, так и значение. Значением функции является значение ее аргумента, а побочным эффектом - печать этого значения.
Функции PRIN1 и PRINC.
Эти функции работают так же, как PRINT, но не переходят на новую строку и не выводят пробел:
(PRIN1 5) ð 55
(PRINC 4) ð 44
Обеими функциями можно выводить кроме атомов и списков и другие типы данных которые мы рассмотрим позже:
_(PRIN1 «CHG») ð «CHG»«CHG»
_(PRINC «tfd») ðtfd«tfd» ;вывод без кавычек,
;результат - значение аргумента
С помощью функция PRINC можно получить более приятный вид. Она выводит лисповские объекты в том же виде, как и PRIN1, но преобразует некоторые типы данных в более простую форму.
Функция TERPRI.
Эта функция переводит строку. У функции TERPRIнет аргументов и в качестве значения она возвращает NIL:
_(DEFUN out (x y)
(PRIN1 x) (PRINC y)
(TERPRI) (PRINC (LIST ‘x ‘y)) ð out
_(out 1 2) ð 12
(1 2)
4. Вычисления, изменяющие структуру.
Основными функциями, изменяющими физическую структуру списков, являются RPLACAи RPLACD, которые уничтожают прежние и записывают новые значения в поля CAR и CDR списочной ячейки:
(RPLACAячейка значение-поля) ;поле CAR
(RPLACDячейка значение-поля) ;поле CDR
Первым аргументом является указатель на списочную ячейку, вторым - записываемое в нее новое значение поля CARили CDR. Обе функции возвращают в качестве результата указатель на измененную списочную ячейку:
_(SETQ a ‘(b c d)) ð (b c d)
_(RPLACA a ‘d) ð (d c d)
_(RPLACD a ‘(o n m)) ð (d o n m)
_að (donm)
5. Задания к лабораторной работе.
1. Определите с помощью лямбда-выражения функцию, вычисляющую:
a) +y-x*y;
b) x*x+y*y;
c) x*y/(x+y)-5*y;
2. Определите функции (NULLx), (CADDR x) и (LISTx1 x2 x3) с помощью базовых функций. (Используйте имена NULL1, CADDR1 и LIST1, чтобы не переопределять одноименные встроенные функции системы.
3. Используя композицию, напишите функции, которые осуществляют обращение списка из 2, 3, ... , n элементов.
4. Используя композицию описанных выше предикатов и логических связок, постройте функцию, которая проверяет, является ли ее аргумент:
a) списком из 2, 3, ... элементов;
b)списком из 2, 3, ... атомов;
5. Напишите функцию:
a) P(n) для произвольного целого n есть список из трех элементов, а именно: квадрата, куба и четвертой степени числа n;
b)
c) , что A(n) естьсписок (The answer is n). Так, значением (A 12) будет (The answer is 12);
d)
6. Для каждого из следующих условий определить функцию одного аргумента L, которая имеет значение T, если условие удовлетворяется, и NIL в противном случае:
a) n-ый элемент Lесть 12;
b) n-ый элемент L есть атом;
c) L имеет не более n элементов (атомов или подсписков).
7. Напишите функцию, которая вводит фразу на естественном языке и преобразует ее в список.
8. Напишите функцию, которая спрашивает у пользователя ФИО студента из группы (список группы составлен раньше) и выдает следующие данные о нем:
a)
b)
c)
d)
9. Напишите функцию:
a)
b)
10. Каковы будут значения выражений (RPLACAxx) и (RPLACDxx), если:
a) x = ’(a b);
b) x = ’(a);
11. Вычислите значение следующих выражений:
a) (RPLACD ‘(a) ‘b);
b) (RPLACA ‘(a) ‘b);
c) (RPLACD (CDDR ‘(a b x)) ‘c);
d) (RPLACD ‘(nil) nil)
6. Вопросы.
1. Что такое лямбда-выражение?
2. Для чего используется функция DEFUN?
3. Чем различаются основные функции вывода?
4. Что возвращает в качестве значения функция READ?
5. Особенности функций, изменяющих структуру?
Лабораторная работа №3.
Тема: Организация вычислений в Лиспе.
Цель: Изучить основные функции и их особенности для организации вычислений в Лиспе.
1. Предложения LETи LET*.
2. Последовательные вычисления.
3. Разветвление вычислений.
4. Циклические вычисления.
5. Передача управления.
6. Задание к лабораторной работе.
7. Вопросы.
1. Предложения LET и LET*.
Предложение LET создает локальную связь внутри формы:
(LET ((m1 знач1) (m2 знач2)...)
форма1 форма2 ...)
Вначале статические переменные m1, m2, ... связываются (одновременно) с соответствующими значениями знач1, знач2, ... . Затем слева на право вычисляются значения формы1, формы2, ... . Значение последней формы возвращается в качестве значения всей формы. После вычисления связи статических переменных ликвидируются.
Предложения LET можно делать вложенными одно в другое.
_(LET ((x ‘a) (y ‘b))
(LET ((z ‘c)) (LIST x y z))) ð (a b c)
_(LET ((x (LET ((z ‘a)) z)) (y ‘b))
(LIST x y)) ð (a b)
_(LET ((x 1) (y (+ x 1)))
(LIST x y)) ð ERROR
При вычислении у У и Х еще нет связи. Значения переменным присваиваются одновременно. Это означает, что значения всех переменных mi вычисляются до того, как осуществляется связывание с формальными параметрами.
Подобной ошибки можно избежать с помощью формы LET*:
_(LET* ((x 1) (y (+ x 1)))
(LIST x y)) ð (1 2)
2. Последовательные вычисления.
Предложения PROG1 и PROGN позволяют работать с несколькими вычисляемыми формами:
(PROG1 форма1 ... формаN)
(PROGN форма1 ... формаN)
Эти специальные формы последовательно вычисляют свои аргументы и в качестве значения возвращают значение первого (PROG1) или последнего (PROGN) аргумента.
_(PROG1 (SETQ x 1) (SETQ y 5)) ð 1
_(PROGN (SETQ j 8) (SETQ z (+x j))) ð 9
3. Разветвление вычислений.
Условное предложение COND:
(COND (p1 a1)
...
(pn an))
Предикатами pi и результирующими выражениями ai могут быть произвольные формы. Выражения pi вычисляются последовательно до тех пор, пока не встретится выражение, значением которого является T. Вычисляется результирующее выражение, соответствующее этому предикату, и полученное значение возвращается в качестве значения всего предложения COND. Если истинного предиката нет то значением COND будет NIL.
Рекомендуется в качестве последнего предиката использовать символ T. Тогда соответствующее ему an будет вычисляться в том случае, если другие условия не выполняются.
Если условию не ставится в соответствие результирующее выражение, то в качестве результата выдается само значение предиката. Если же условию соответствуют несколько форм, то при его истинности формы вычисляются последовательно слева на право и результатом предложения COND будет значение последней формы.
Предложения COND можно комбинировать.
(COND ((> x 0) (SETQ рез x))
((< x 0) (SETQ x -x) (SETQ рез х))
((= х 0))
(Т ‘ошибка))
Предложение IF.
(IF условие то-форма иначе-форма)
(IF (> x 0) (SETQ y (+ y x)) (SETQ y (- y x)))
Если выполняется условие (т. е. х>0), то к значению y прибавляется значение х, иначе (x<0) от y отнимается отрицательное значение х, т. е. прибавляется абсолютное его значение.
Можно использовать формуWHEN.
(WHEN условие форма1 форма2 ... )
Выбирающее предложение CASE^
(CASE ключ
(список-ключей1 m11 m12 ... )
(список-ключей2 m21 m22 ... )
....)
Сначала вычисляется значение ключевой формы - ключ. Затем его сравнивают с элементами списка-ключейi. Когда в списке найдено значение ключевой формы, начинают вычисляться соответствующие формы mi1, mi2, ... . Значение последней возвращается в качестве значения всего предложения CASE.
_(SETQ ключ 3) ð 3
_(CASE ключ
(1 ‘one)
(2 ‘(one + one) ‘two)
(3 ‘(two + one) ‘three) ð three
4. Циклические вычисления.
Предложение DO.
(DO ((var1 знач1 шаг1) (var2 знач2 шаг2) ...)
(условие-окончания форма11 форма12 ...)
форма21 форма22 ...)
Первый аргумент описывает внутренние переменные var1, var2, ..., их начальные значения - знач1, знач2, ... и формы обновления - шаг1, шаг2, ....
Вначале вычисления предложения DOI внутренним переменным присваиваются начальные значения, если значения не присваиваются, то по умолчанию переменным присваивается NIL. Затем проверяется условие-окончания. Если оно действительно, то последовательно выполняются формы1i и значение последней возвращается в качестве значения всего предложения DO, иначе последовательно вычисляются формы2i.
На следующем цикле переменным vari одновременно присваиваются значения форм - шагi, вычисляемых в текущем контексте, проверяется условие-окончания и т. д.
_(DO ((x 5 (+ x 1)) (y 8 (+ y 2)) (рез 0))
((< x 10) рез)
(SETQ рез (+ рез xy))
5. Передача управления.
На Лиспе можно писать программы и в обычном операторном стиле с использованием передачи управления. Однако во многих системах не рекомендуется использовать эти предложения, так как их можно заменить другими предложениями (например DO) и, как правило, в более понятной форме. Но мы рассмотрим предложения передачи управления, хотя использовать их не следует.
(PROG (m1 m2 ... mn)
оператор1
оператор2
...
операторm)
Перечисленные в начале формы переменные mi являются локальными статическими переменными формы, которые можно использовать для хранения промежуточных результатов. Если переменных нет, то на месте списка переменных нужно ставить NIL. Если какая-нибудь форма операторi является символом или целым числом, то это метка перехода. На такую метку можно передать управление оператором GO:
(GO метка)
GO не вычисляет значение своего «аргумента».
Кроме этого, в PROG-механизм входит оператор окончания вычисления и возврата значения:
(RETURN результат)
Операторы предложения PROG вычисляются слева направо (сверху вниз), пропуская метки перехода. Оператор RETURN прекращает выполнение предложения PROG; в качестве значения всего предложения возвращается значение аргумента оператора PROG. Если во время вычисления оператор RETURN не встретился, то значением PROG после вычисления его последнего оператора станет NIL .
После вычисления значения формы связи программных переменных исчезают.
6. Задания к лабораторной работе.
1. Запишите следующие лямбда-вызовы с использованием формы LET и вычислите их на машине:
a) ((LAMBDA (x y) (LIST x y)
‘(+ 1 2) ‘c);
b) ((LAMBDA (x y) ((LAMBDA (z) (LIST x y z)) ‘c)
‘a ‘b);
c) ((LAMBDA (x y) (LIST x y))
((LAMBDA (z) z) ‘a)
‘b).
2. Напишите с помощью композиции условных выражений функции от четырех аргументов AND4(x1 x2 x3 x4) и OR4(x1 x2 x3 x4), совпадающие с функциями AND и OR от четырех аргументов.
3. Пусть L1 и L2 - списки. Напишите функцию, которая возвращала бы T, если N-ыедва элемента этих функций соответственно равны друг другу, и NIL в противном случае.
4. Написать условное выражение (используя COND), которое:
a) NIL, если L атом, и T в противном случае;
b) L ,состоящего из трех элементов, первый из этих трех, который является атомом, или список, если в списке нет элементов атомов.
5. С помощью предложений COND или CASE определите функцию, которая возвращает в качестве значения столицу заданного аргументом государства.
6. Напишите с помощью условного предложения функцию, которая возвращает из трех числовых аргументов значение большего, меньшего по величине числа.
7. Запрограммируйте с помощью предложения DO функцию факториал.
8. Запишите с помощью предложения PROG функцию (аналог встроенной функции LENGTH), которая возвращает в качестве значения длину списка (количество элементов на верхнем уровне).
9. Используя функцию COND, напишите функцию, которая спрашивает у пользователя ФИО двух студентов из группы (список группы составлен раньше) для которых:
а) сравнивает год рождения и выдает результат (кто старше или что они ровесники);
б) сравнивает средний бал и выдает сообщение о результатах сравнения;
с) проверяет родственные связи (если одни и те же родители, то они родственники) и выдает об этом сообщение.
10. Напишите подобные функции, но уже используя функцию IF.
Для двух последних заданий вывод информации осуществить при помощью функций PRINT, PRIN1, PRINC.
Center - находит среднее из трех чисел:
(DEFUN center (x y z)
(COND ((> x y) (IF (< x z) (PROGN (PRINT x)
(PRINT «среднее (1)»))
(IF (> y z) (PROGN (PRINT y)
(TERPRI)
(PRINT «среднее (2)»))
(PROGN (PRIN1 z)
(PRIN1«среднее (3)»)))))
((< x y) (IF (< y z) (PROGN (PRIN1 y)
(TERPRI)
(PRIN1 «среднее (4)»))
(IF (> x z)(PROGN (PRINC x)
(PRINC«среднее (5)»))
(PROGN (PRINC z)
(TERPRI)
(PRINC «среднее (6)»)))))
(T (PRINC «ошибка ввода»))))
7. Вопросы.
1. Для чего используется предложение LET?
2. В чем его отличие от предложения LET*?
3. Чем различаются функции COND и IF?
4. Каковы возвращаемые ими значения?
5. Чем различаются функции PROG1 и PROGN?
6. Почему не желательно использовать операторы передачи управления? Чем их можно заменить?
Лабораторная работа №4.
Тема: Рекурсия в Лиспе. Функционалы и макросы.
Цель: Изучить основы программирования с применением рекурсии. Научиться работать с функционалами и макросами.
1. Рекурсия. Различные формы рекурсии.
2. Применяющие функционалы.
3. Отображающие функционалы.
4. Макросы.
5. Задание к лабораторной работе.
6. Вопросы.
1. Рекурсия. Различные формы рекурсии.
Основная идея рекурсивного определения заключается в том, что функцию можно с помощью рекуррентных формул свести к некоторым начальным значениям, к ранее определенным функциям или к самой определяемой функции, но с более «простыми» аргументами. Вычисление такой функции заканчивается в тот момент, когда оно сводится к известным начальным значениям.
Рекурсивная процедура, во-первых содержит всегда по крайней мере одну терминальную ветвь и условие окончания. Во-вторых, когда процедура доходит до рекурсивной ветви, то функционирующий процесс приостанавливается, и новый такой же процесс запускается сначала, но уже на новом уровне. Прерванный процесс каким-нибудь образом запоминается. Он будет ждать и начнет исполняться лишь после окончания нового процесса. В свою очередь, новый процесс может приостановиться, ожидать и т. д.
Будем говорить о рекурсии по значению и рекурсии по аргументам. В первом случаевызов является выражением, определяющим результат функции. Во втором - в качестве результата функции возвращается значение некоторой другой функции и рекурсивный вызов участвует в вычислении аргументов этой функции. Аргументом рекурсивного вызова может быть вновь рекурсивный вызов и таких вызовов может быть много.
Рассмотрим следующие формы рекурсии:
n
n
n
Рекурсия называется простой, если вызов функции встречается в некоторой ветви лишь один раз. Простой рекурсии в процедурном программировании соответствует обыкновенный цикл.
Для примера напишем функцию вычисления чисел Фибоначчи (F(1)=1; F(2)=1; F(n)=F(n-1)+F(n-2) при n>2):
(DEFUN FIB (N)
(IF (> N 0)
(IF (OR N=1 N=2)1
(+ (FIB (- N 1)) (FIB (- N 2))))
‘ОШИБКА_ВВОДА))
Рекурсию называют параллельной, если она встречается одновременно в нескольких аргументах функции:
(DEFUN f ...
...(g ... (f ...) (f ...) ...)
...)
Рассмотрим использование параллельной рекурсии на примере преобразования списочной структуры в одноуровневый список:
(DEFUN PREOBR (L)
(COND
((NULL L) NIL)
((ATOM L) (CONS (CAR L) NIL))
(T (APPEND
(PREOBR (CAR L))
(PREOBR (CDR L))))))
Рекурсия является взаимной между двумя и более функциями, если они вызывают друг друга:
(DEFUN f ...
...(g ...) ...)
(DEFUN g ...
...(f ...) ...)
Для примера напишем функцию обращения или зеркального отражения в виде двух взаимно рекурсивных функций следующим образом:
(DEFUN obr (l)
(COND ((ATOM l) l)
(T (per l nil))))
(DEFUN per (l res)
(COND ((NULL l) res)
(T (per (CDR l)
(CONS (obr (CAR l)) res)))))
2. Применяющие функционалы.
Функции, которые позволяют вызывать другие функции, т. е. применять функциональный аргумент кего параметрам называют применяющими функционалами. Они дают возможность интерпретировать и преобразовывать данные в программу и применять ее в вычислениях.
APPLY
APPLY является функцией двух аргументов, из которых первый аргумент представляет собой функцию, которая применяется к элементам списка, составляющим второй аргумент функции APPLY:
(APPLY fn список)
_(SETQ a ‘+) ð +
_(APPLY a ‘(1 2 3)) ð 6
_(APPLY ‘+ ‘(4 5 6)) ð 15
FUNCALL.
Функционал FUNCALL по своему действию аналогичен APPLY, но аргументы для вызываемой он принимает не списком, а по отдельности:
(FUNCALL fn x1 x2 ... xn)
_(FUNCALL ‘+ 4 5 6) ð 15
FUNCALL и APPLY позволяют задавать вычисления (функцию) произвольной формой, например, как в вызове функции, или символом, значением которого является функциональный объект. Таким образом появляется возможность использовать синонимы имени функции. С другой стороны, имя функции можно использовать как обыкновенную переменную, например для хранения другой функции (имени или лямбда-выражения), и эти два смысла (значение и определение) не будут мешать друг другу:
_(SETQ list ‘+) ð +
_(FUNCALL list1 2) ð 3
_(LIST 1 2) ð (1 2)
3. Отображающие функционалы.
Отображающие или MAP-функционалы являются функциями, которые являются функциями, которые некоторым образом отображают список (последовательность) в новую последовательность или порождают побочный эффект, связанный с этой последовательностью. Каждая из них имеет более двух аргументов, значением первого должно быть имя определенной ранее или базовой функции, или лямбда-выражение, вызываемое MAP-функцией итерационно, а остальные аргументы служат для задания аргументов на каждой итерации. Естественно, что количество аргументов в обращении к MAP-функции должно быть согласовано с предусмотренным количеством аргументов у аргумента-функции. Различие между всеми MAP-функциями состоит в правилах формирования возвращаемого значения и механизме выбора аргументов итерирующей функции на каждом шаге.
Рассмотрим основные типы MAP-функций.
MAPCAR.
Значение этой функции вычисляется путем применения функции fn к последовательным элементам xi списка, являющегося вторым аргументом функции. Например в случае одного списка получается следующее выражение:
(MAPCAR fn ‘(x1 x2 ... xn))
В качестве значения функционала возвращается список, построенный из результатов вызовов функционального аргумента MAPCAR.
_(MAPCAR ‘LISTP ‘((f) h k (i u)) ð (T NIL NIL T)
_(SETQ x ‘(a b c)) ð (a b c)
_(MAPCAR ‘CONS x ‘(1 2 3)) ð ((a . 1) (b . 2) (c . 3))
MAPLIST.
MAPLIST действует подобно MAPCAR, но действия осуществляет не над элементами списка, а над последовательными CDR этого списка.
_(MAPLIST ‘LIST ‘((f) h k (i u)) ð (T T T T)
_(MAPLIST ‘CONS ‘(a b c) ‘(1 2 3)) ð (((a b c) 1 2 3) ((b c) 2 3) ((c ) 3))
Функционалы MAPCAR и MAPLIST используются для программирования циклов специального вида и в определении других функций, поскольку с их помощью можно сократить запись повторяющихся вычислений.
Функции MAPCAN и MAPCON являются аналогами функций MAPCAR и MAPLIST. Отличие состоит в том, что MAPCAN и MAPCON не строят, используя LIST, новый список из результатов, а объединяют списки, являющиеся результатами, в один список.
4. Макросы.
Программное формирование выражений наиболее естественно осуществляется с помощью макросов. Макросы дают возможность писать компактные, ориентированные на задачу программы, которые автоматически преобразуются в более сложный, но более близкий машине эффективный лисповский код. При наличии макросредств некоторые функции в языке могут быть определены в виде макрофункций. Такое определение фактически задает закон предварительного построения тела функции непосредственно перед фазой интерпретации.
Синтаксис определения макроса выглядит так же, как синтаксис используемой при определении функций формы DEFUN:
(DEFMACRO имя лямбда-список тело)
Вызов макроса совпадает по форме с вызовом функции, но его вычисление отличается от вычисления вызова функции. Первое отличие состоит в том, что в макросе не вычисляются аргументы. Тело макроса вычисляется с аргументами в том виде, как они записаны.
Второе отличие состоит в том, что интерпретация функций, определенных как макро, производится в два этапа. На первом, называемом макрорасширением, происходит формирование лямбда-определения функции в зависимости от текущего контекста, на втором осуществляется интерпретация созданного лямбда-выражения.
_(DEFMACRO setqq (x y)
(LIST ‘SETQ x (LIST ‘QUOTE y))) ð setqq
_(setqq a (b c)) ð (b c)
_a ð (b c)
Макросы отличаются от функций и в отношении контекста вычислений. Во время расширения макроса доступны синтаксические связи из контекста определения. Вычисление же полученной в результате расширения формы производится вне контекста макровызова, и поэтому статические связи из макроса не действуют. Использование макрофункций облегчает построение языка с лиспоподобной структурой, имеющего свой синтаксис, более удобный для пользователя. Чрезмерное использование макросредств затрудняет чтение и понимание программ.
5. Задания к лабораторной работе.
1. Напишите рекурсивную функцию, определяющую сколько раз функция FIB вызывает саму себя. Очевидно, что FIB(1) и FIB(2) не вызывают функцию FIB.
2. Напишите функцию для вычисления полиномов Лежандра (P0(x)=1, P1(x)=x, Pn+1(x)= ((2*n+1)*x*Pn(x)-n*Pn-1(x))/(n+1) при n>1).
3. Напишите функцию:
a)
b)
c)
4. Напишите функцию:
a) X и N, которая создает список из Nраз повторенных элементов X;
b)
c) (a b) ð ((a) (b));
d)
e)
f) X, N и V, добавляющую X на N-е место в список V.
5. Напишите функцию:
a) SUBST, но в которой третий аргумент W обязательно должен быть списком;
b) X на Y только на верхнем уровне W;
c) Y на число, равное глубине вложения Y в W, например Y=A, W=((A B) A (C (A (A D)))) ð ((2 B) 1 (C (3 (4 D))));
d) SUBST, но производящую взаимную замену X на Y, т. е. X ð Y, Y ð X.
6. Вычислите значения следующих вызовов:
a) (APPLY ‘LIST ‘(a b));
b) (FUNCALL ‘LIST ‘(a b));
c) (FUNCALL ‘APPLY ‘LIST ‘(a b));
d) (FUNCALL ‘LIST ‘APPLY ‘(a b);
7. Определите функционал (A-APPLY f x), который применяет каждую функцию fi списка
f = (f1 f2 ... fn)
к соответствующему элементу xi списка
x = (x1 x2 ... xn)
и возвращает список, сформированный из результатов.
8. Определите функциональный предикат (КАЖДЫЙ пред список), который истинен в том и только в том случае, когда, являющийся функциональным аргументом предикат пред истинен для всех элементов списка список.
9. Определите функциональный предикат (НЕКОТОРЫЙ пред список), который истинен, когда предикат истинен хотя бы для одного элемента списка.
10. Определите FUNCALL через функционал APPLY.
11. Определите функционал (MAPLIST fn список) для одного списочного аргумента.
12. Определите макрос, который возвращает свой вызов.
13. Определите лисповскую форму (IF условие p q) в виде макроса.
Примеры написания функций.
;Subst - заменяет все вхождения Y в W на X.
(DEFUN subst (x y w)
(COND ((NULL w) NIL) ;проверка на окончание списка
((EQUAL ‘y ‘w) x)
((ATOM ‘w) w) ;
(t (CONS (subst x y (car w)) ;поиск в глубину
(subst x y (cdr w)))))) ;поиск в ширину
;COMPARE1 - сравнение с образцом
(defun compare1(p d)
(cond ((and (null p) (null d)) t);исчерпались списки?
((or (null p) (null d)) nil) ;одинакова длина списков?
((or (equal1 (car p) '&);присутствует в образце атом &
(equal1 (car p) (car d))) ;или головы списков равны
(compare1 (cdr p) (cdr d))) ;& сопоставим с любым атомом
((equal1 (car p) '*) ;присутствует в образце атом *
(cond ((compare1 (cdr p) d));* ни с чем не сопоставима
((compare1 (cdr p) (cdr d))) ;* сопоставима с одним атомом
((compare1 p (cdr d))))))) ;* сопоставима с несколь ;кими атомами
6. Вопросы.
1. Что такое рекурсия?
2. Назовите достоинства ее использования?
3. Что такое функционал?
4. Назовите особенности применяющих и отображающих функционалов?
5. Для чего они используются?
6. Что такое макрос?
7. Когда их используют?
Лабораторная работа №5.
Тема: Типы данных и средства работы с ними. Представление знаний.
Цель: Изучить типы данных, используемые в MuLisp, а так же научиться применять их в программах.
1. Точечная нотация.
2. Структурированные типы данных.
3. Представление знаний.
4. Задания к лабораторной работе.
5. Вопросы.
1. Точечная нотация.
В Лиспе существует понятие точечной пары. Название точечной пары происходит из использованной в ее записи точечной нотации, в которой для разделения полейCAR и CDR используется выделенная пробелами точка. Базовые функции CAR и CDR действуют совершенно симметрично.
_(CONS ‘a ‘d) ð (a . d)
_(CAR ‘(a . b)) ð a
_(CDR ‘(a . (b . c))) ð (b . c)
Любой список можно записать в точечной нотации. Преобразование можно осуществить (на всех уровнях списка) следующим образом:
(a1 a2 ... an) ó (a1 . (a2 ....(an . nil)... ))
_(a b c (d e)) ó (a . (b . (c . ((d . (e . nil)) . nil))))
Признаком списка здесь служит NIL в поле CDR последнего элемента списка, символизирующий его окончание.
Использование точечных пар в программировании на Лиспе в общем-то излишне. Точечные пары применяются в теории, книгах и справочниках по Лиспу. Кроме того они используются совместно с некоторыми типами данных и с ассоциативными списками, а также в системном программировании.
2. Структурированные типы данных.
Списки (ассоциативные).
Ассоциативный список или просто а-список - состоит из точечных пар, поэтому его также называют списком пар.
((a1 . t1) (a2 . t2) ... (an . tn))
Первый элемент пары называют ключом а второй - связанными с ключом данными. Обычно ключом является символ. связанные с ним данные могут быть символами, списками или какими не будь другими лисповскими объектами.
В работе со списками пар нужно уметь строить списки, искать данные по ключу и обновлять их.
PAIRLIS.
Функция PAIRLIS строит а-список из списка ключей и списка, сформированного из соответствующих им данных. Третьим аргументом является старый а-список, в начало которого добавляются новые пары:
(PAIRLIS ключи данные а-список)
_(SETQ спис ‘(один . Иванов)) ð (один . Иванов)
_(SETQ спис
(PAIRLIS ‘(три два) ‘(Петров Сидоров)
спис)) ð ((три . Петров) (два . Сидоров) (один . Иванов))
ASSOC.
Ассоциативный список можно считать отображением из множества ключей в множество значений. Данные можно получить с помощью функции
(ASSOC ключ а-список)
которая ищет в списке пар данные, соответствующие ключу, сравнивая искомый ключ с ключами пар слева направо.
_(ASSOC ‘три спис) ð (три . Петров)
ACONS.
Ассоциативный список можно обновлять и использовать в режиме стека. Новые пары добавляются к нему только в начало списка, хотя в списке уже могут быть данные с тем же ключом. Это осуществляется функцией ACONS:
(ACONS x y а-список)
Поскольку ASSOC просматривает список слева направо и доходит лишь до первой пары с искомым ключом, то более старые пары как бы остаются в тени более новых.
Строки.
Строка состоит из последовательности знаков. В строке знаки записываются в последовательности друг за другом, для ограничения которой с обеих сторон в качестве ограничителя используется знак «».
При вводе строки в интерпретаторе, в качестве результата получаем ту же строку.
CHAR.
Произвольный элемент строки можно прочитать (т. е. сослаться на него с помощью индекса) функцией CHAR:
(CHAR строка n)
(CHAR «строка» 0) ð с ;индексация начинается с 0
Сравнение строк.
(STRING= строка1 строка2)
(STRING< строка1 строка2)
(STRING> строка1 строка2)
(STRING/= строка1 строка2)
Массивы.
Для работы с массивами в MuLisp необходимо загрузить файл ARRAY.LSP.
Массивы создаются формой:
(MAKE-ARRAY (n1 n2 ... nN) режимы)
Функция возвращает в качестве значения новый объект - массив. n1, n2, ... nN - целые числа, их количество N отражает размерность массива, а значения - размер по каждой размерности. Необязательными аргументами можно задать тип элементов массива, указать их начальные значения или придать самому массиву динамический размер. Общий размер массива в этом случае знать и закреплять не обязательно.
Для вычислений, осуществляемых с массивами, наряду с функцией создания массива используются функции для выборки и изменения элементов массива. Ссылка на элемент N-мерного массива осуществляется с помощью вызова:
(ARREF массив n1 n2 ...nN)
n1, n2, ..., nN - координаты, или индексы, элемента, на который ссылаются. В качестве функции присваивания используется обобщенная функция присваивания SETF.
_(SETQ мас (MAKE-ARRAY ‘(54)
:ELEMENT-TYPE ‘ATOM
:INITIAL-ELEMENT A)) ð (ARRAY((A A A A) ... (A A A A) (5 6)))
_(SETF (AREF мас0 1) B) ð B
_мас ð(ARRAY ((A B A A) ... (A A A A )))
Структуры.
Для объединения основных типов данных (чисел, символов, строк, массивов) в комплексы, отображающие предметы, факты используется составной тип, который называется структурами.
Определение структурного типа осуществляется с помощью макроса DEFSTRUCT, формой которого является
(DEFSTRUCT класс-структур
поле1
поле2
...)
Определим структурный тип БАЗА состоящий из компонент ПРОФИЛЬ, ПЛОЩ и ВМЕСТИМ:
_(DEFSTRUCT база
профиль площ вместим) ð БАЗА
Для каждого нового типа данных генерируется начинающаяся с MAKE- функция создания структуры данного типа. Например объект типа БАЗА можно создать и присвоить переменной БАЗА1 следующим вызовом:
_(SETQ БАЗА1 (MAKE-БАЗА))
Полю с помощью ключевого слова, которым является имя поля с двоеточием перед ним, присвоить при создании начальное значение.
Вызов MAKE-БАЗА возвращает в качестве значения созданную структуру.
Для копирования структуры генерируется функция, начинающаяся с COPY- (COPY-БАЗА).
Для каждого поля определяемой структуры создается функция доступа, имя которой образуется написанием после имени типа через тире имени поля, например:
_(БАЗА-ПРОФИЛЬ x)
Вызов возвращает значение поля ПРОФИЛЬ для БАЗЫ, задаваемой структурой x.
Для присваивания значений полям структуры используется обобщенная функция присваивания SETF:
_(SETF (БАЗА-ПРОФИЛЬ БАЗА1) ОВОЩ) ð ОВОЩ
3. Представление знаний.
Продукционные системы
Для представления знаний используют различные формализмы и языки представления данных. Наиболее распространенными простым для понимания является представление знаний при помощиправил продукциивида:
«ЕСЛИ <условие>, ТО <следствие>»
Условия и следствия - это простые предложения естественного языка. Такие формализмы называют продукционными. Эти правила похожи на условные операторы IF-THENязыков программирования,однако совершенно по другому интерпретируются.
(ЕСЛИ на лампочку подано напряжение
и лампочка не горит
то лампочка перегорела)
Через правила можно определить, как программа должна реагировать на изменение данных. При этом не нужно заранее знать блок-схему управления обработкой данных. В обычнойпрограммесхема передачи управления и использованияданных предопределения самой программой. Ветвление в таких программахвозможно только в заранее выбранных точках. Для задач, ход решения которых управляется самими данными, где ветвление скорее норма, чем исключение, этот способ малоэффективен.
Фреймы.
Это частный случай семантических сетей. Это метод представления знаний,который связываетсвойства с узлами , представляющими понятия и объекты. Свойства описываются атрибутами (называемыми слотами) и их значениями.
[f(
где f - имя фрейма;
Использование фреймов с их атрибутами и взаимосвязями позволяет хранить знания опредметной областив структурированномвиде, представлять в БЗ абстракции и аналогии. Система знаний представляется в виде сети под фреймом или субфреймом. Каждый из фреймов отражает определенные свойства, понятия, т. е. позволяет удовлетворять требованию структурированности и связности.
С операциями присваивания значений фреймам и другими операциями можно сочетать сложные побочные действия и взаимовлияния.
Одной из важнейших концепций формализма фреймов является наследование. Можно дать указание, что если значение слота в одном из фреймов не задается, то фрейм должен унаследовать умалчивамое значение этого слота из фрейма более высокого уровня. Наследование фреймами значений слотов будет осуществляться в том случае, если в фрейме будет присутствовать слот РАЗНОВИДНОСТЬ, в котором содержится имя другого фрейма.
Используются и другие связанные с конкретным применением способы представления, но они менее распространены и, как правило, не годятся для использования в общем случае.
Не всегда можно однозначно сказать, какой формализм представления использован в системе. В рамках одной и той же системы для представления различных видов знаний могут быть использованы различные формализмы.
Пример1.
В качестве примера представления знаний в виде продукций рассмотрим программу хранящуюся в файле EXSIS.LSP.
;EXSIS.LSP - пример представления знаний в виде продукций
;определим предложения являющиеся правилами в виде структур, состоящих
из имени правила, условий и выводов, представленных в виде списка фактов
(defstruct prav имя условия выводы) ;определение структурного типа PRAV
;создание структур типа PRAV и присваивание их переменным PRAV1 ... PRAV5
(setq prav1 (make-prav :имя 'prav1 ;присвоение полю имя значения
:условия '((жив имеет шерсть))
:выводы '((жив млекопитающее))))
(setq prav2 (make-prav :имя 'prav2
:условия '((жив кормит детенышей молоком))
:выводы '((жив млекопитающее))))
(setq prav3 (make-prav :имя 'prav3
:условия '((жив имеет перья))
:выводы '((жив птица))))
(setq prav4 (make-prav :имя 'prav4
:условия '((жив умеет летать)
(жив несет яйца))
:выводы '((жив птица))))
(setq prav5 (make-prav :имя 'prav5
:условия '((жив ест мясо))
:выводы '((жив хищник))))
(setq *правила* '(prav1 prav2 prav3 prav4 prav5) ;список, хранящий правила системы
(defun проверь-правило (правило)
;проверяет применимо ли правило
(подмнож (prav-условия правило) *факты*))
(defun подмнож (подмнож множ)
;проверяет, является ли множ подмнож
(equal подмнож (intersection1 подмнож множ)))
(defun добавь-выводы (правило)
;расширяет список фактов правилами вывода
(do ((выводы (prav-выводы правило))) ;инициализация начального значения
((null выводы) *факты*) ;условие окончания
(if (member (car выводы) *факты*) nil ;проверка - входит «голова»
(progn (prin1 "Согласно правилу:") ;выводов в список фактов
(prin1 (prav-name правило))
(push (car выводы) *факты*)))
(setq выводы (cdr выводы)))) ;шаг изменения
Для проверки работоспособности программы необходимо выполнить следующую последовательность команд:
MuLisp-87.com Common.lsp - Загрузка системы
(load structur.lsp) - подключение приложения для работы со структурами
(load rash.lsp) - подключение расширения, которое мы рассмотрим позже
(load exsis.lsp) - подключение тестируемой программы
В начале работы с программой необходимо инициализировать список фактов
(SETQ *факты* ‘(начальные факты))
где начальные факты - условия из какого-либо правила
Пример2.
Пример представления знаний с помощью фреймов. В примере упоминаются три фрейма - МЕРОПРИЯТИЕ, СОБРАНИЕ и СОБРАНИЕ1. Фрейм МЕРОПРИЯТИЕ - наиболее общий, фрейм СОБРАНИЕ- более конкретный, описывающий вид МЕРОПРИЯТИЯ, а фрейм СОБРАНИЕ1 - наиболее уточненный фрейм, описывающий конкретное СОБРАНИЕ. Фрейм СОБРАНИЕ называется субфреймом фрейма МЕРОПРИЯТИЕ, а СОБРАНИЕ1 - субфрейм фрейма СОБРАНИЕ.
(собрание имя фрейма
(разновидность (мероприятие)) имена и значения слотов
(время (среда 14.00)) (умалчиваемые значения
(место (зал заседаний)) наследуются субфреймами)
)
(собрание1
(разновидность (собрание))
(присутствуют ((Вася) (Петя) (Маша)))
)
Реализация фрейм-программы на Лиспе.
;EXSIS2 - реализация фрейм-программы на Лиспе.
(setf (get ‘собрание ‘разновидность) ‘мероприятие)
(setf (get ‘собрание ‘время) ‘(среда 14.00))
(setf (get ‘собрание ‘место) ‘(зал заседаний))
(setf (get‘собрание1 ‘разновидность)‘собрание)
(setf (get ‘собрание1 ‘присутствуют)‘((Вася) (Петя) (Маша)))
;функция - определяющая наследуемые свойства
(defun наследование (фрейм имя_слота)
(cond ((get фрейм имя_слота)) ;имеется во фрейме данный слот?
;если да, то вернуть его значение.
(t (cond ((get фрейм ‘разновидность) ;иначе - проверить наличие
;слота разновидность. В случае его присутствия - рекурсивно применить
;функцию к верхним фреймам
(наследование (get фрейм ‘разновидность) имя_слота))
(t nil)))))
4. Задания к лабораторной работе.
1.Переведите следующие списочные записи в точечные:
a) (w (x));
b) ((w) x);
c) (nil nil nil);
d) (v (w) x (y z));
e) ((v w) (x y) z);
f) (((v) w x) y z).
2. Переведите следующие точечные записи в списочные:
a) ;
b) ((a . nil) . nil);
c) (nil . (a . nil));
d) (a . ((b . (c . nil)) . ((d . (e . nil)) . nil)));
e) (a . (b . ((c . (d . ((e . nil) . (nil))) . nil)));
f) ((a . (b . nil)) . (c . ((d . nil) . (e . nil)))).
3. Напишите функцию:
a) pairlis, которая строит список пар;
b) assoc, которая ищет пару, соответствующую ключу.
4. Напишите функцию, аналог функции putassoc которая физически изменяет а-список (putassoc1ключ данные а-список).
5. Расширьте возможности программы EXSIS.LSP:
a)
b)
c)
d) EXSIS.LSP), и которая выполняла бы их в диалоговом режиме.
6. Подобным образом измените программу EXSIS1.LSP.
7. Разработайте базу знаний и правила базы знаний РАСПИСАНИЕ ЗАНЯТИЙ используя:
a)
b)
5. Вопросы.
1. В чем особенности точечной нотации?
2. Назовите структурированные типы данных, их особенности?
3. Способы представления знаний?
4. Их достоинства и недостатки?
Лабораторная работа № 6.
Тема: Изучение учебной версии языка Лисп - dlisp. Расширение библиотеки функций dlisp.
Цель: Ознакомиться с учебной версией Лиспа - dlisp. Изучить ее возможности и особенности. Расширить библиотеку функций dlisp.
1. Интерфейс пользователя.
2. Функции, поддерживаемые dlisp.
3. Расширение библиотеки функций dlisp.
4. Задание к лабораторной работе.
5. Вопросы.
1. Интерфейс пользователя.
Запуск системы осуществляется командой:
DLISP.EXE
При загрузке системы начинает работать редактор, он чистит экран, рисует рамку и выдает на экран главное меню:
Файл. Имеет следующие опции: новый, открыть, сохранить, сохранить как, выход.
Просмотр: экран вывода, экран интерпретатора.
Редактор.
Поиск: поиск, повторить поиск, замена.
Запуск: выполнить, перезапустить, продолжить.
Отладка: шаг, трассировка, контрольная точка, очистить все.
Параметры: режим экрана, проверка синтаксиса.
Справка.
Затем система ждет, пока пользователь не выберет одну из опций.
Редактор работает с файлами, имеющими расширение LSP и находящимися в той же директории, что и файл DLISP.EXE
Результаты вычислений выводятся на специальный экран. Для просмотра этих результатов необходимо выбрать опцию «Просмотр» главного меню, а в ней - «экран вывода». Чтобы вернуться назад необходимо нажать любую клавишу.
Для переключения в режим диалога используют клавиши SHIFT+TAB.
Для повтора предыдущей команды используют клавишу F3.
2. Функции, поддерживаемые dlisp.
Dlisp поддерживает несколько различных типов данных:
* списки
* символы
* строковые константы
* действительные числа
* целые числа
По синтаксису и соглашениям Dlisp близок к MuLispу, более того, он является небольшойего частью.
Dlisp содержит некоторое число заранее определенныхфункций.Каждая функция вызывается как список, первым элементом которого является имяфункции, а остальными - аргументы этой функции (если они есть).Многиеиз функций - стандартные функции LISP, их можно найти в каждом руководстве по языку.
Функции MuLispа поддерживаемые dlispом и определенные нами в предыдущих лабораторных работах.
(+ <число> <число>...)
(- <число> <число>...)
(* <число> <число>...)
(/ <число> <число>...)
(= <атом> <атом>...)
(/= <атом1> <атом2>)
(< <атом> <атом>...)
(<= <атом> <атом>...)
(> <атом> <атом>...)
(>= <атом> <атом>...)
(and <выражение>...)
(atom <элемент>)
(boundp <атом>)
(car <список>)
(cdr <список> )
(cond (<тест1> <результат>...)...)
(cons <первый элемент> <список>)
(defun <символ> <список аргументов> <выражение>...)
(eq <выражение1> <выражение2>)
(if <текст-выражение> <выражение-тогда> [<выражение-иначе>])
(lambda <аргументы> <выражение> ...)
(list <выражение> ...)
(listp <элемент>)
(mapcar <функция> <список1>...<списокn>)
(not <элемент>)
(null <элемент>)
(numberp <элемент>)
(or <выражение>...)
(princ <выражение> [<описатель файла>])
(print <выражение> [<описатель файла>])
(progn <выражение>...)
(quote <выражение>)
(read <строка>)
(set <символ> <выражение>)
(setq <символ1> <выражение1> [<символ2> <выражение2>]...)
(while <тест-выражение> <выражение>...)
(zerop <элемент>)
Функции dlispа не используемые MuLispом.
(cos <угол>)
Эта функция возвращает косинус <угла>, где <угол> - выражаетсяв радианах. Например:
(cos0.0) возвращает1.000000
(cospi) возвращает-1.000000
(sin <элемент>)
Эта функция возвращает синус <угла>какдействительноечисло, где <угол> выражен в радианах. Например:
(sin 1.0) возвращает0.841471
(sin 0.0) возвращает0.000000
(min <число> <число>...)
Этафункция возвращаетнаименьшееиз заданных <чисел>. Каждое<число> может быть действительным или целым.
(nth
Эта функция
возвращает "энный" элемент <списка>, где
(nth 3 '(a b c d e)) возвращает D
(nth 0 '(a b c d e)) возвращает A
(nth 5 '(a b c d e)) возвращает nil
(strcat <строка1> <строка2>...)
Этафункция возвращаетстроку,которая является результатом сцепления строки1>, <строки2> и т.д. Например:
(strcat "a" "bout") возвращает "about"
(strcat "a" "b" "c") возвращает "abc"
(strcat "a" "" "c") возвращает "ac"
(strlen <строка>)
Этафункция возвращаетдлинув символах строковой константы <строка> как целую величину. Например:
(stalen "abcd") возвращает 4
(stalen "ab") возвращает 2
(stalen "") возвращает 0
(subst <новый элемент> <старый элемент> <список>)
Эта функция просматривает <список> в поиске <старых элементов> и возвращает копию <списка> с заменой каждого встречного <старогоэлемента> на<новый элемент>. Если <старый элемент> не найден в <списке>, SUBST возвращает <список> неизменным. Например, дано:
(setq sample '(a b (c d) b))
тогда:
(subst'qq'b sample) возвращает (A QQ (C D) QQ)
(subst 'qq 'z sample) возвращает (A B (C D) B)
(subst 'qq '(c d) sample) возвращает (A B QQ B)
(subst '(qq 'rr) '(c d) sample) возвращает(A B(QQ RR) B)
(subst '(qq 'rr) 'z sample) возвращает (A B (C D) B)
В сочетании с функцией ASSOC, SUBST обеспечивает удобный способ заменывеличины, найденной по ключу в структурированном списке. Например, дано:
(stq who '((ferst john) (mid q) (last public)))
тогда:
(setq old (assoc 'first who)) возвращает (FIRST JOHN)
(setq new '(first j))возвращает (FIRST J)
(setq new old who)возвращает ((FIRST J) (MID Q) (LAST PUBLIC))
(type <элемент>)
Эта функция возвращает TYPE (тип) <элемента>, где TYPE - одно из следующих значений (как атом):
REAL числа с плавающей запятой
STR строковые константы
INTцелые величины
SYM символы
LIST списки (и функции пользователя)
3. Расширение библиотеки функций dlisp.
Основные принципы программирования на dlisp те же, что и в MuLisp, при этом сохраняется и синтаксис MuLispа.
Никогда не используйте имена встроенных функций или символов для функций, определяемых вами, так как это сделает недоступными встроенные функции.
Пример расширения библиотеки функций dlispа содержится в файле rash.lsp. Для его запуска необходимо выполнить следующую последовательность команд:
MuLisp87.com Common.lsp
(load rash.lsp)
;File rash.lsp
;(Приложение к учебной версии языка Лисп dlisp).
;Содержит функции, расширяющие библиотеку dlisp Лиспа.
;Функция APPEND1 соединяет два списка в один
(defun append1 (l p)
(if (null l) p ;L пуст - вернуть P (условие окончания),
(cons (car l) ;иначе - создать список,
(append1 (cdr l) p)))) ;используя рекурсию.
;EQUAL1 - логическая идентичность объектов (параллельная рекурсия)
(defun equal1 (u v)
(cond ((null u) (null v)) ;возвращает T если U и V пустые
((numberp u) (if (numberp v) (= u v) ;проверка
nil)) ;на идентичность
((numberp v) nil) ; чисел
((atom u) (if (atom v) (eq u v) ;сравнение атомов
nil))
((atom v) nil)
(t (and (equal1 (car u) (car v)); идентичность "голов"
(equal1 (cdr u) (cdr v)))))) ;идентичность "хвостов"
;DELETE1 - удаляет элемент X из списка L
(defun delete1 (x l)
(cond ((null l) nil)
((equal1 (car l) x) (delete1 x (cdr l)))
(t (cons (car l) (delete1 x (cdr l)))))) ;ветвь выполняется
;в случае невыполнения предыдущих.
;FULLENGTH1 - определяет полную длину списка L (на всех уровнях)
(defun fullength1 (l)
(cond ((null l) 0);для пустого списка возвращается 0
((atom l) 1);если L является атомом - возвращается 1
(t (+ (fullength1 (car l)) ;подсчет в глубину
(fullength1 (cdr l)))))) ;подсчет в ширину
;DELETELIST1 - удаляет все элементы, входящие в список U из списка V
(defun deletelist1 (u v)
(cond ((null u) v)
(t (delete1 (car u)
(deletelist1 (cdr u) v)))))
;MEMBER1 - проверяет вхождение элемента U в список V на верхнем уровне
(defun member1 (u v)
(cond ((null v) nil)
((equal1 u (car v)) v)
(t (member1 u (cdr v)))))
;В случае присутствия S-выражения U в списке V функция возвращает остаток списка V, начинающийся с U, в противном случае результатом вычисления является NIL.
;INTERSECTION1 - вычисляет список общих элементов двух списков
(defun intersection1 (u v)
(cond ((null u) nil)
((member1 (car u) v);проверка на вхождение "головы" сп. U в сп. V
(cons (car u) (intersection1 (cdr u) v)));создание списка
(t (intersection1 (cdr u) v))));ненужные элементы отбрасываются
;UNION1 - объединяет два списка, но в отличие от APPEND1,
;в результирующий список не добавляются повторяющиеся элементы
(defun union1 (u v)
(cond ((null u) v)
((member1 (car u) v) ;отсеивание
(union1 (cdr u) v)) ; ненужных элементов
(t (cons (car u)
(union1 (cdr u) v)))))
;COPY-LIST1 - копирует верхний уровень списка
(defun copy-list1 (l)
(cond ((null l) nil)
(t (cons (car l)
(copy-list1 (cdr l))))))
;COPY_TREE1 - копирует списочную структуру
(defun copy-tree1 (l)
(cond ((null l) nil)
((atom l) l)
(t (cons (copy-tree1 (car l))
(copy-tree1 (cdr l))))))
;ADJOIN1 - добавляет элемент к списку
(defun adjoin1 (x l)
(cond ((null l) nil)
((atom l) (cons x ;если L атом, то он преобразуется в список,
(cons l nil))) ;а затем к нему добавляется X
(t (cons x l))))
;SET-DIFFERENCE1 - находит разность двух списков
(defun set-difference1 (w e)
(cond ((null w) nil)
((member1 (car w) e);отбрасываются ненужные
(set-difference1 (cdr w) e));элементы
(t (cons (car w)
(set-difference1 (cdr w) e)))))
;COMPARE1 - сравнение с образцом
(defun compare1(p d)
(cond ((and (null p) (null d)) t);исчерпались списки?
((or (null p) (null d)) nil) ;одинакова длина списков?
((or (equal1 (car p) '&) ;присутствует в образце атом &
(equal1 (car p) (car d))) ;или головы списков равны
(compare1 (cdr p) (cdr d))) ;& сопоставим с любым атомом
((equal1 (car p) '*) ;присутствует в образце атом *
(cond ((compare1 (cdr p) d));* ни с чем не сопоставима
((compare1 (cdr p) (cdr d))) ;* сопоставима с одним атомом
((compare1 p (cdr d))))))) ;* сопоставима с несколькими
;атомами
;SUBSTITUTE1 - замена в списке L атома S на атом N
(defun substitute1 (n s l)
(cond ((null l) nil)
((atom (car l))
(cond ((equal1 s (car l))
(cons n (substitute1 n s (cdr l))))
(t (cons (car l) (substitute1 n s (cdr l))))))
(t (cons (substitute1 n s (car l))
(substitute1 n s (cdr l))))))
;DELETE-DUPLICATES1 - удаление повторяющихся элементов
(defun delete-duplicates1 (l)
(cond ((null l) nil)
((member1 (car l) (cdr l))
(delete-duplicates1 (cdr l)))
(t (cons (car l) (delete-duplicates1 (cdr l))))))
;ATOMLIST1 - проверка на одноуровневый список
(defun atomlist1 (l)
(cond ((null l) t)
((listp (car l)) nil)
(t (atomlist1 (cdr l)))))
;REVERSE1 - обращает верхний уровень списка
(DEFUN REVERSE1 (l)
(COND ((NULL l ) NIL)
(T (APPEND1 (REVERSE1 (CDR l))
(CONS (CAR l) NIL)))))
4. Задание к лабораторной работе.
Напишите функцию, аналог системной функции Лиспа:
1. а) (1+ <число>) Результат функции - <число>, увеличенное на единицу.
в) (1- <число>)Результат функции - <число>, уменьшенное на единицу.
2. а) (incf память приращение) Добавление приращения к числу в памяти.
в) (decf память приращение) Вычитание приращения из числа в памяти.
3. (expt <основание> <степень>) Эта функция возвращает <основание>, возведенноевуказанную <степень>.Если обааргумента целые, то результат - целое число. В любом другом случае, результат - действительное число.
4. (gcd <число1> <число2>) Функция возвращаетнаибольшийобщий делитель <числа1> и <числа2>. <Число1> и <число2> должны быть целыми.
5. а) (first <список>), second, third, и т. д. возвращающие соответственно первый, второй, третий, и т. д. элемент списка.
в) (last <список>) Эта функция возвращает последнийэлементсписка. <Список>не должен быть равен nil. LAST возвращает либо атом либо список.
6. а) (max <число> <число>...) Эта функция возвращает наибольшее иззаданных чисел.
в) (min <число> <число> ...) Эта функция возвращает наименьшее из заданных чисел.
7. а) (evenp <число>) Проверяет, четное ли число. Она возвращает T - если число четное и NIL- в противном случае.
в) (oddrp <число>) Эта функция - противоположная по действию функции evenp.
8. которая сортирует числа:
а) по возрастанию.
в) по убыванию.
9. предикат - который определяет:
а) числа с плавающей запятой.
в) целые числа.
г) строковые константы.
д) символы.
е) списки.
10. зависящую от одного аргумента, которая генерирует все циклические перестановки списка.
11. зависящую от одного элемента, которая по данному списку вычисляет список его элементов:
а) встречающихся в нем более 1, 2, ... раз.
в) встречающихся в нем не менее 2, 3, ... раз.
P. S. Запишите все функции, написанные вами, в один файл. Для отладки программы используйте встроенные средства dlispа.
5. Вопросы.
1. Какие способы тестирования программ предусмотрены в dlisp?
2. В чем их различия?
3. Какие функции предусмотрены для работы со строковыми константами в dlisp?
4. Назовите их основные особенности?
Заключение.
В результате выполнения дипломной работы было проделано следующее:
n Проведен анализ языков программирования ИИ, а такжедиалектов и систем Лиспа.
n В качестве теоретических сведений рассмотрены основные особенности и возможности языка Лисп.
n Разработан комплекс лабораторных работ по изучению языка MuLisp для студентов специальности «Компьютерные и интеллектуальные системы и сети», имеющих следующие темы:
Лабораторная работа №1.
Тема: Ознакомительная работа в среде MuLisp. Базовые функции Лиспа. Символы, свойства символов. Средства языка для работы с числами.
Цель: Освоить среду MuLisp. Изучить базовые функции Лиспа, символы и их свойства, а также средства для работы с числами.
Лабораторная работа №2.
Тема: Определение функций. Функции ввода-вывода. Вычисления, изменяющие структуру.
Цель: Получить навыки в написании функций на Лиспе. Изучить функции ввода- вывода.
Лабораторная работа №3.
Тема: Организация вычислений в Лиспа.
Цель: Изучить основные функции и их особенности для организации вычислений в Лиспе.
Лабораторная работа №4.
Тема: Рекурсия в Лиспе. Функционалы и макросы.
Цель: Изучить основы программирования с применением рекурсии. Научится работать с функционалами и макросами.
Лабораторная работа №5.
Тема: Типы данных, используемые в MuLisp. Точечное представление списков. Представление знаний.
Цель: Изучить основные типы данных MuLisp. Разобраться с точечной нотацией списков.
Лабораторная работа №6.
Тема: Изучение учебной версии интегрированной среды dlisp. Расширение библиотеки функций dlisp.
Цель: Ознакомиться с учебной версией интегрированной среды dlisp. Изучить ее возможности и особенности. Расширить библиотеку функций dlisp.
n Разработаны задания, требующие индивидуальной работы студента и контрольные вопросы, позволяющие оценить уровень знаний студента по каждой теме.
n Часть лабораторных работ была выполнена студентами 5-го курса специальности «Компьютерные и интеллектуальные системы и сети», после чего были проработаны (изучены и исправлены) недостатки, а так же расширен круг вопросов, раскрываемых в лабораторных работах.